我就废话不多说了,还是直接看代码吧!
import pandas as pd # 伪造一些数据 fake_data = {'subject':['math', 'english'], 'A': [88, 90], 'B': [70, 80], 'C': [60, 78]} # 宽表 test = pd.DataFrame(fake_data, columns=['subject', 'A', 'B', 'C']) test subjectABC 0math887060 1english908078 # 转换为窄表 pd.melt(test, id_vars=['subject']) subjectvariablevalue 0mathA88 1englishA90 2mathB70 3englishB80 4mathC60 5englishC78补充知识:pandas从单条目数据集生成宽表
需求
场景
从医院数据库中导出了大量的体检数据,但体检数据表中,每一行代表某人某次体检的某一项体检的结果。目的想将每一个人的每一次体检结果作为一行存储,每一列为体检项。
示例
StuID Type Num 0 111021 Math 89 1 111021 English 93 2 312983 English 91 3 314621 English 82 4 314621 Math 92 5 112341 Math 82 目的:转换成如下表格
StuID English Math 0 111021 93 89 1 312983 91 NaN 2 314621 82 92 3 112341 NaN 82 方案一
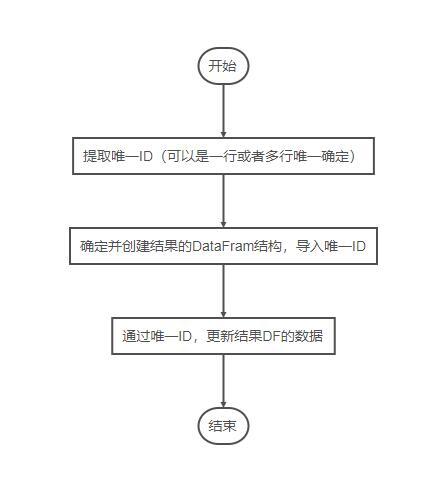
具体代码如下
#将'B'列的类别调整为行。 #1 num = df[~df.duplicated(subset=['StuID'])].loc[:,'StuID'].to_list() #2 result_df = pd.DataFrame({'StuID': np.array(num)},columns=['StuID','English','Math']) #3 for i in df.index: t = df.loc[i,'Type'] num = df.loc[i,'StuID'] result_df.loc[result_df['StuID'] == num,[t]] = df.loc[i,'Num'] print(result_df)结果

以上这篇pandas使用之宽表变窄表的实现就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:pandas
pandas使用之宽表变窄表的实现
看: 1834次 时间:2020-07-19 分类 : 数据分析
- 相关文章
- 2021-12-20python数据挖掘使用Evidently创建机器学习模型仪表板
- 2021-12-20Python多进程共享numpy 数组的方法
- 2021-12-20python数据分析近年比特币价格涨幅趋势分布
- 2021-12-20python调用matlab的方法详解
- 2021-12-20python学习与数据挖掘应知应会的十大终端命令
- 2021-07-20pandas中NaN缺失值的处理方法
- 2021-07-20Python数据分析入门之数据读取与存储
- 2021-07-20Python 如何读取字典的所有键-值对
- 2021-07-20如何获取numpy的第一个非0元素索引
- 2021-07-20Python机器学习之KNN近邻算法
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!