http_request2.py用于发起http请求
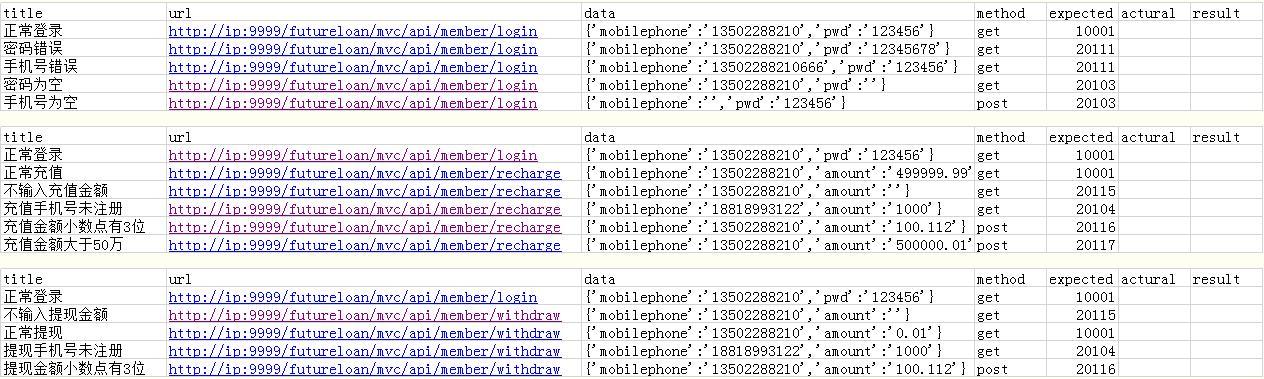
#读取多条测试用例 #1、导入requests模块 import requests #从 class_12_19.do_excel1导入read_data函数 from do_excel2 import read_data from do_excel2 import write_data from do_excel2 import count_case #定义http请求函数 COOKIE=None def http_request2(method,url,data): if method=='get': print('发起一个get请求') result=requests.get(url,data,cookies=COOKIE) else: print('发起一个post请求') result=requests.post(url,data,cookies=COOKIE) return result #返回响应体 # return result.json() #返回响应结果:结果是字典类型:{'status': 1, 'code': '10001', 'data': None, 'msg': '登录成功'} #从Excel读取到多条测试数据 sheets=['login','recharge','withdraw'] for sheet1 in sheets: max_row=count_case(sheet1) print(max_row) for case_id in range(1,max_row): data=read_data(sheet1,case_id) print('读取到第{}条测试用例:'.format(data[0])) print('测试数据 ',data) #print(type(data[2])) #调用函数发起http请求 result=http_request2(data[4],data[2],eval(data[3])) print('响应结果为 ',result.json()) if result.cookies: COOKIE=result.cookies #将测试实际结果写入excel #write_data(case_id+1,6,result['code']) write_data(sheet1,case_id+1,7,str(result.json())) #对比测试结果和期望结果 if result.json()['code']==str(data[5]): print('测试通过') #将用例执行结果写入Excel write_data(sheet1,case_id+1,8,'Pass') else: write_data(sheet1,case_id+1,8,'Fail') print('测试失败')do_excel2.py完成对excel中用例的读、写、统计
# 导入load_workbook from openpyxl import load_workbook #读取测试数据 #将excel中每一条测试用例读取到一个列表中 #读取一条测试用例——写到一个函数中 def read_data(sheet_name,case_id): # 打开excel workbook1=load_workbook('test_case2.xlsx') # 定位表单(test_data) sheet1=workbook1[sheet_name] print(sheet1) test_case=[] #用来存储每一行数据,也就是一条测试用例 test_case.append(sheet1.cell(case_id+1,1).value) test_case.append(sheet1.cell(case_id+1,2).value) test_case.append(sheet1.cell(case_id+1,3).value) test_case.append(sheet1.cell(case_id+1,4).value) test_case.append(sheet1.cell(case_id+1,5).value) test_case.append(sheet1.cell(case_id+1,6).value) return test_case #将读取到的用例返回 #调用函数读取第1条测试用例,并将返回结果保存在data中 # data=read_data(1) # print(data) #将测试结果写会excel def write_data(sheet_name,row,col,value): workbook1=load_workbook('test_case2.xlsx') sheet=workbook1[sheet_name] sheet.cell(row,col).value=value workbook1.save('test_case2.xlsx') #统计测试用例的行数 def count_case(sheet_name): workbook1=load_workbook('test_case2.xlsx') sheet=workbook1[sheet_name] max_row=sheet.max_row #统计测试用例的行数 return max_rowtest_case2.xlsx存储测试用例

补充知识:python用unittest+HTMLTestRunner+csv的框架测试并生成测试报告
直接贴代码:
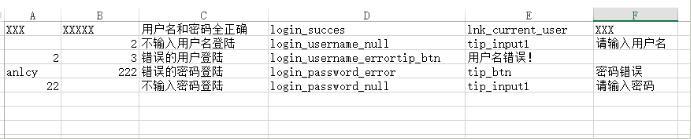
import csv # 导入scv库,可以读取csv文件 from selenium import webdriver import unittest from time import sleep import time import os import HTMLTestRunner import codecs import sys dr = webdriver.Chrome() class testLo(unittest.TestCase): def setUp(self): pass def test_login(self): '''登陆测试''' path = 'F:\\Python_test\\' # 要读取的scv文件路径 my_file = 'F:\\pythonproject\\interfaceTest\\testFile\\ss.csv' # csv.reader()读取csv文件, # Python3.X用open,Python2.X用file,'r'为读取 # open(file,'r')中'r'为读取权限,w为写入,还有rb,wd等涉及到编码的读写属性 #data = csv.reader(codecs.open(my_file, 'r', encoding='UTF-8',errors= 'ignore')) with codecs.open(my_file, 'r', encoding='UTF-8',errors= 'ignore') as f: data=csv.reader((line.replace('\x00','') for line in f)) # for循环将读取到的csv文件的内容一行行循环,这里定义了user变量(可自定义) # user[0]表示csv文件的第一列,user[1]表示第二列,user[N]表示第N列 # for循环有个缺点,就是一旦遇到错误,循环就停止,所以用try,except保证循环执行完 print(my_file) for user in data: print(user) dr.get('https://passport.cnblogs.com/user/signin') # dr.find_element_by_id('input1').clear() dr.find_element_by_id('input1').send_keys(user[0]) # dr.find_element_by_id('input2').clear() dr.find_element_by_id('input2').send_keys(user[1]) dr.find_element_by_id('signin').click() sleep(1) print('\n' + '测试项:' + user[2]) dr.get_screenshot_as_file(path + user[3] + ".jpg") try: assert dr.find_element_by_id(user[4]).text try: error_message = dr.find_element_by_id(user[4]).text self.assertEqual(error_message, user[5]) print('提示信息正确!预期值与实际值一致:') print('预期值:' + user[5]) print('实际值:' + error_message) except: print('提示信息错误!预期值与实际值不符:') print('预期值:' + user[5]) print('实际值:' + error_message) except: print('提示信息类型错误,请确认元素名称是否正确!') def tearDown(self): dr.refresh() # 关闭浏览器 dr.quit() if __name__ == "__main__": # 定义脚本标题,加u为了防止中文乱码 report_title = u'登陆模块测试报告' # 定义脚本内容,加u为了防止中文乱码 desc = u'登陆模块测试报告详情:' # 定义date为日期,time为时间 date = time.strftime("%Y%m%d") time = time.strftime("%Y%m%d%H%M%S") # 定义path为文件路径,目录级别,可根据实际情况自定义修改 path = 'F:\\Python_test\\' + date + "\\login\\" + time + "\\" # 定义报告文件路径和名字,路径为前面定义的path,名字为report(可自定义),格式为.html report_path = path + "report.html" # 判断是否定义的路径目录存在,不能存在则创建 if not os.path.exists(path): os.makedirs(path) else: pass # 定义一个测试容器 testsuite = unittest.TestSuite() # 将测试用例添加到容器 testsuite.addTest(testLo("test_login")) # 将运行结果保存到report,名字为定义的路径和文件名,运行脚本 report = open(report_path, 'wb') #with open(report_path, 'wb') as report: runner = HTMLTestRunner.HTMLTestRunner(stream=report, title=report_title, description=desc) runner.run(testsuite) # 关闭report,脚本结束 report.close()csv文件格式:
备注:
使用python处理中文csv文件,并让execl正确显示中文(避免乱码)设施编码格式为:utf_8_sig,示例:
''''' 将结果导出到result.csv中,以UTF_8 with BOM编码(微软产品能正确识别UTF_8 with BOM存储的中文文件)存储 ''' #data.to_csv('result_utf8_no_bom.csv',encoding='utf_8')#导出的结果不能别excel正确识别 data.to_csv('result_utf8_with_bom.csv',encoding='utf_8_sig')以上这篇python利用Excel读取和存储测试数据完成接口自动化教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
- << 上一篇 下一篇 >>
python利用Excel读取和存储测试数据完成接口自动化教程
看: 1951次 时间:2020-07-14 分类 : 数据分析
- 相关文章
- 2021-12-20python数据挖掘使用Evidently创建机器学习模型仪表板
- 2021-12-20Python多进程共享numpy 数组的方法
- 2021-12-20python数据分析近年比特币价格涨幅趋势分布
- 2021-12-20python调用matlab的方法详解
- 2021-12-20python学习与数据挖掘应知应会的十大终端命令
- 2021-07-20pandas中NaN缺失值的处理方法
- 2021-07-20Python数据分析入门之数据读取与存储
- 2021-07-20Python 如何读取字典的所有键-值对
- 2021-07-20如何获取numpy的第一个非0元素索引
- 2021-07-20Python机器学习之KNN近邻算法
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!