这篇文章主要介绍了Pandas数据离散化原理及实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
为什么要离散化
- 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具
- 扔掉一些信息,可以让模型更健壮,泛化能力更强
什么是数据的离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值
分箱
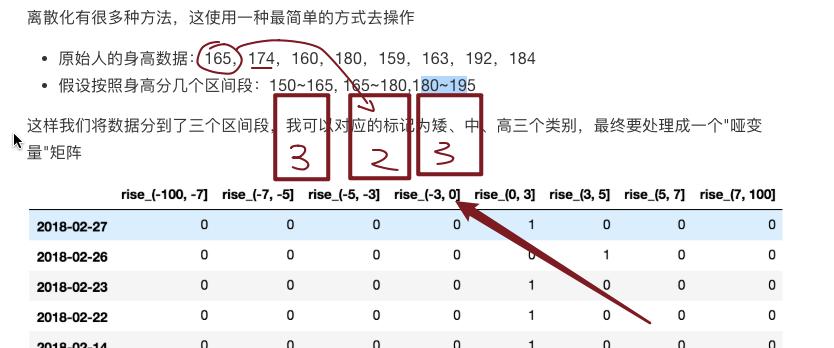
案例
1.先读取股票的数据,筛选出p_change数据
data = pd.read_csv("./data/stock_day.csv") p_change= data['p_change']2.将股票涨跌幅数据进行分组
使用的工具:
- pd.qcut(data, bins)——等深分箱:
- 对数据进行分组将数据分组 一般会与value_counts搭配使用,统计每组的个数
- series.value_counts():统计分组次数
# 自行分组 qcut = pd.qcut(p_change, 10) # 计算分到每个组数据个数 qcut.value_counts()自定义区间分组:
- pd.cut(data, bins)——等宽分箱:
- bins是整数—等宽
- bins是列表--自定义分箱
# 自己指定分组区间 bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100] p_counts = pd.cut(p_change, bins)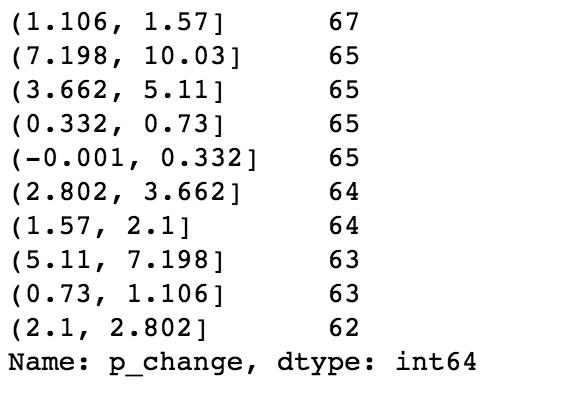
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
- 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具
-
<< 上一篇 下一篇 >>
标签:pandas
Pandas数据离散化原理及实例解析
看: 2075次 时间:2021-02-23 分类 : 数据分析
- 相关文章
- 2021-12-20python数据挖掘使用Evidently创建机器学习模型仪表板
- 2021-12-20Python多进程共享numpy 数组的方法
- 2021-12-20python数据分析近年比特币价格涨幅趋势分布
- 2021-12-20python调用matlab的方法详解
- 2021-12-20python学习与数据挖掘应知应会的十大终端命令
- 2021-07-20pandas中NaN缺失值的处理方法
- 2021-07-20Python数据分析入门之数据读取与存储
- 2021-07-20Python 如何读取字典的所有键-值对
- 2021-07-20如何获取numpy的第一个非0元素索引
- 2021-07-20Python机器学习之KNN近邻算法
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!