NumPy
什么是NumPy
NumPy是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。主页为https://numpy.org/。
安装NumPy
使用pip工具来安装。
python -m pip install numpy使用NumPy读取mnist数据
如果直接从网络上读取mnist数据,恭喜你,目前国内基本需要一个小时以上。所以建议预先下载mnist数据包。
工作环境
当前我的工作环境如下:Win10 + Anaconda。使用Spyder4做为IDE。Anaconda的安装可以参考我的blog。
将数据放置到指定目录
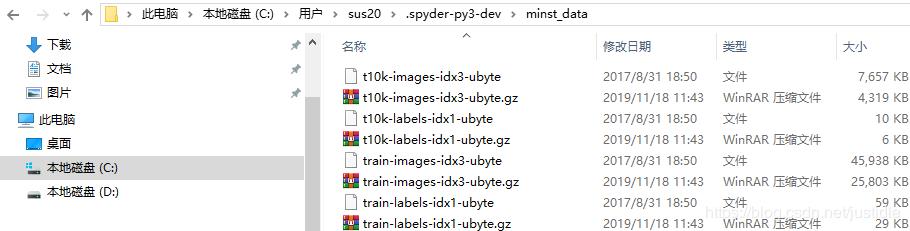
下图是我当前的工作目录环境,因此在C:\Users\sus20\.spyder-py3-dev目录下,建立子目录minist。如下图所示:

将下载好的四个gz文件拷贝到这个目录下,并将这四个gz文件解压。如下图所示:
使用NumPy读取MNIST
load_mnist 函数返回两个数组,第一个是一个 n * m 维的 NumPy array(images),这里的 n 是样本行数,m 是特征列数。训练数据集包含 60,000 个样本,测试数据集包含 10,000 样本。
在 MNIST 数据集中的每张图片由 28 * 28 个像素点构成,每个像素点用一个灰度值表示。在这里,我们将 28 * 28 的像素展开为一个一维的行向量,这些行向量就是图片数组里的行(每行 784 个值, 或者说每行就是代表了一张图片)。
load_mnist 函数返回的第二个数组(labels) 包含了相应的目标变量,也就是手写数字的类标签(整数 0-9)。
import os import struct import numpy as np def load_mnist(path, kind='train'): """Load MNIST data from `path`""" labels_path = os.path.join(path,'%s-labels-idx1-ubyte'% kind) images_path = os.path.join(path,'%s-images-idx3-ubyte'% kind) with open(labels_path, 'rb') as lbpath: magic, n = struct.unpack('>II',lbpath.read(8)) labels = np.fromfile(lbpath,dtype=np.uint8) #读入magic是一个文件协议的描述,也是调用fromfile 方法将字节读入NumPy的array之前在文件缓冲中的item数(n). with open(images_path, 'rb') as imgpath: magic, num, rows, cols = struct.unpack('>IIII',imgpath.read(16)) images = np.fromfile(imgpath,dtype=np.uint8).reshape(len(labels), 784) return images, labels print(load_mnist("minst_data"))运行代码,将得到如下图结果,说明我们已经正确的从本地读取MNIST数据集。

下一步,我们要开始使用TensorFlow读取MNIST数据集。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:numpy
使用NumPy读取MNIST数据的实现代码示例
看: 1631次 时间:2021-02-07 分类 : 数据分析
- 相关文章
- 2021-12-20python数据挖掘使用Evidently创建机器学习模型仪表板
- 2021-12-20Python多进程共享numpy 数组的方法
- 2021-12-20python数据分析近年比特币价格涨幅趋势分布
- 2021-12-20python调用matlab的方法详解
- 2021-12-20python学习与数据挖掘应知应会的十大终端命令
- 2021-07-20pandas中NaN缺失值的处理方法
- 2021-07-20Python数据分析入门之数据读取与存储
- 2021-07-20Python 如何读取字典的所有键-值对
- 2021-07-20如何获取numpy的第一个非0元素索引
- 2021-07-20Python机器学习之KNN近邻算法
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!