1、简要说明
结巴分词支持三种分词模式,支持繁体字,支持自定义词典
2、三种分词模式
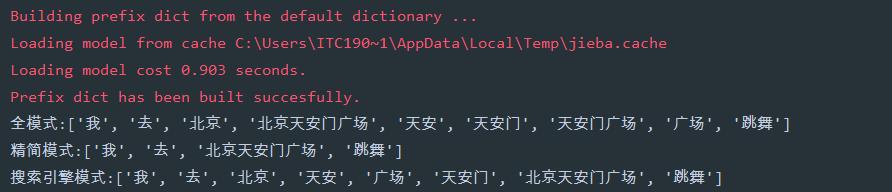
全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
精简模式:把句子最精确的分开,不会添加多余单词,看起来就像是把句子分割一下
搜索引擎模式:在精简模式下,对长词再度切分
# -*- encoding=utf-8 -*- import jieba if __name__ == '__main__': str1 = '我去北京天安门广场跳舞' a = jieba.lcut(str1, cut_all=True) # 全模式 print('全模式:{}'.format(a)) b = jieba.lcut(str1, cut_all=False) # 精简模式 print('精简模式:{}'.format(b)) c = jieba.lcut_for_search(str1) # 搜索引擎模式 print('搜索引擎模式:{}'.format(c))运行
3、某个词语不能被分开
# -*- encoding=utf-8 -*- import jieba if __name__ == '__main__': str1 = '桃花侠大战菊花怪' b = jieba.lcut(str1, cut_all=False) # 精简模式 print('精简模式:{}'.format(b)) # 如果不把桃花侠分开 jieba.add_word('桃花侠') d = jieba.lcut(str1) # 默认是精简模式 print(d)运行
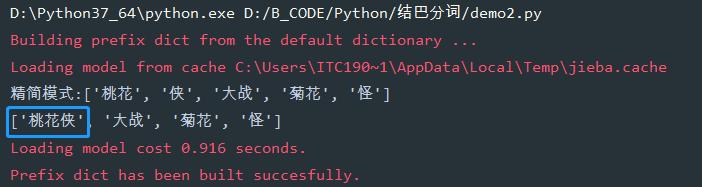
4、 某个单词必须被分开
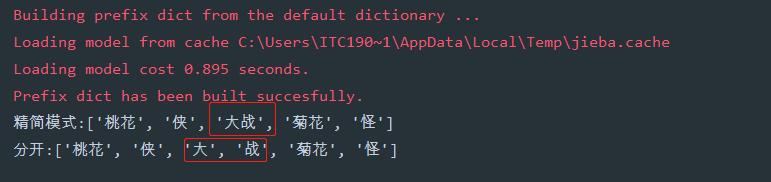
# -*- encoding=utf-8 -*- import jieba if __name__ == '__main__': # HMM参数,默认为True '''HMM 模型,即隐马尔可夫模型(Hidden Markov Model, HMM),是一种基于概率的统计分析模型, 用来描述一个系统隐性状态的转移和隐性状态的表现概率。 在 jieba 中,对于未登录到词库的词,使用了基于汉字成词能力的 HMM 模型和 Viterbi 算法, 其大致原理是: 采用四个隐含状态,分别表示为单字成词,词组的开头,词组的中间,词组的结尾。 通过标注好的分词训练集,可以得到 HMM 的各个参数,然后使用 Viterbi 算法来解释测试集,得到分词结果。 ''' str1 = '桃花侠大战菊花怪' b = jieba.lcut(str1, cut_all=False, HMM=False) # 精简模式,且不使用HMM模型 print('精简模式:{}'.format(b)) # 分开大战为大和战 jieba.suggest_freq(('大', '战'), True) e = jieba.lcut(str1, HMM=False) # 不使用HMM模型 print('分开:{}'.format(e))运行
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
Python jieba结巴分词原理及用法解析
看: 1889次 时间:2020-12-01 分类 : 数据分析
- 相关文章
- 2021-12-20python数据挖掘使用Evidently创建机器学习模型仪表板
- 2021-12-20Python多进程共享numpy 数组的方法
- 2021-12-20python数据分析近年比特币价格涨幅趋势分布
- 2021-12-20python调用matlab的方法详解
- 2021-12-20python学习与数据挖掘应知应会的十大终端命令
- 2021-07-20pandas中NaN缺失值的处理方法
- 2021-07-20Python数据分析入门之数据读取与存储
- 2021-07-20Python 如何读取字典的所有键-值对
- 2021-07-20如何获取numpy的第一个非0元素索引
- 2021-07-20Python机器学习之KNN近邻算法
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!