今天晚上,笔者接到客户的一个需要,那就是:对多分类结果的每个类别进行指标评价,也就是需要输出每个类型的精确率(precision),召回率(recall)以及F1值(F1-score)。
对于这个需求,我们可以用sklearn来解决,方法并没有难,笔者在此仅做记录,供自己以后以及读者参考。
我们模拟的数据如下:
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']其中y_true为真实数据,y_pred为多分类后的模拟数据。使用sklearn.metrics中的classification_report即可实现对多分类的每个类别进行指标评价。
示例的Python代码如下:
# -*- coding: utf-8 -*- from sklearn.metrics import classification_report y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海'] y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海'] t = classification_report(y_true, y_pred, target_names=['北京', '上海', '成都']) print(t)输出结果如下:
precision recall f1-score support 北京 0.75 0.75 0.75 4 上海 1.00 0.67 0.80 3 成都 0.50 0.67 0.57 3 accuracy 0.70 10 macro avg 0.75 0.69 0.71 10 weighted avg 0.75 0.70 0.71 10需要注意的是,输出的结果数据类型为str,如果需要使用该输出结果,则可将该方法中的output_dict参数设置为True,此时输出的结果如下:
{‘北京': {‘precision': 0.75, ‘recall': 0.75, ‘f1-score': 0.75, ‘support': 4}, ‘上海': {‘precision': 1.0, ‘recall': 0.6666666666666666, ‘f1-score': 0.8, ‘support': 3}, ‘成都': {‘precision': 0.5, ‘recall': 0.6666666666666666, ‘f1-score': 0.5714285714285715, ‘support': 3}, ‘accuracy': 0.7, ‘macro avg': {‘precision': 0.75, ‘recall': 0.6944444444444443, ‘f1-score': 0.7071428571428572, ‘support': 10}, ‘weighted avg': {‘precision': 0.75, ‘recall': 0.7, ‘f1-score': 0.7114285714285715, ‘support': 10}}使用confusion_matrix方法可以输出该多分类问题的混淆矩阵,代码如下:
from sklearn.metrics import confusion_matrix y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海'] y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海'] print(confusion_matrix(y_true, y_pred, labels = ['北京', '上海', '成都']))输出结果如下:
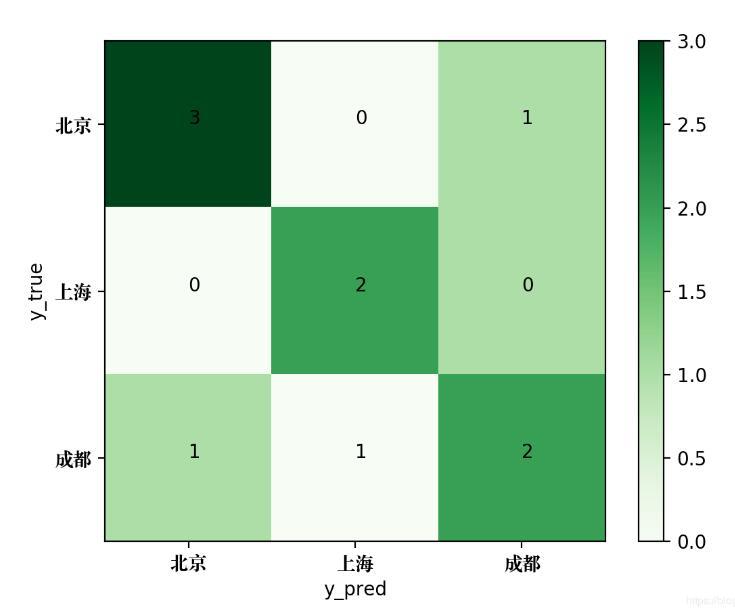
[[2 0 1] [0 3 1] [0 1 2]]为了将该混淆矩阵绘制成图片,可使用如下的Python代码:
# -*- coding: utf-8 -*- # author: Jclian91 # place: Daxing Beijing # time: 2019-11-14 21:52 from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt import matplotlib as mpl # 支持中文字体显示, 使用于Mac系统 zhfont=mpl.font_manager.FontProperties(fname="/Library/Fonts/Songti.ttc") y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海'] y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海'] classes = ['北京', '上海', '成都'] confusion = confusion_matrix(y_true, y_pred) # 绘制热度图 plt.imshow(confusion, cmap=plt.cm.Greens) indices = range(len(confusion)) plt.xticks(indices, classes, fontproperties=zhfont) plt.yticks(indices, classes, fontproperties=zhfont) plt.colorbar() plt.xlabel('y_pred') plt.ylabel('y_true') # 显示数据 for first_index in range(len(confusion)): for second_index in range(len(confusion[first_index])): plt.text(first_index, second_index, confusion[first_index][second_index]) # 显示图片 plt.show()生成的混淆矩阵图片如下:
补充知识:python Sklearn实现xgboost的二分类和多分类
二分类:
train2.txt的格式如下:

import numpy as np import pandas as pd import sklearn from sklearn.cross_validation import train_test_split,cross_val_score from xgboost.sklearn import XGBClassifier from sklearn.metrics import precision_score,roc_auc_score min_max_scaler = sklearn.preprocessing.MinMaxScaler(feature_range=(-1,1)) resultX = [] resultY = [] with open("./train_data/train2.txt",'r') as rf: train_lines = rf.readlines() for train_line in train_lines: train_line_temp = train_line.split(",") train_line_temp = map(float, train_line_temp) line_x = train_line_temp[1:-1] line_y = train_line_temp[-1] resultX.append(line_x) resultY.append(line_y) X = np.array(resultX) Y = np.array(resultY) X = min_max_scaler.fit_transform(X) X_train,X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.3) xgbc = XGBClassifier() xgbc.fit(X_train,Y_train) pre_test = xgbc.predict(X_test) auc_score = roc_auc_score(Y_test,pre_test) pre_score = precision_score(Y_test,pre_test) print("xgb_auc_score:",auc_score) print("xgb_pre_score:",pre_score)多分类:有19种分类其中正常0,异常1~18种。数据格式如下:

# -*- coding:utf-8 -*- from sklearn import datasets from sklearn.multiclass import OneVsRestClassifier from sklearn.svm import LinearSVC from sklearn.cross_validation import train_test_split,cross_val_score from sklearn.svm import SVC from sklearn.linear_model import LogisticRegression from xgboost.sklearn import XGBClassifier import sklearn import numpy as np from sklearn.preprocessing import OneHotEncoder from sklearn.metrics import precision_score,roc_auc_score min_max_scaler = sklearn.preprocessing.MinMaxScaler(feature_range=(-1,1)) resultX = [] resultY = [] with open("../train_data/train_multi_class.txt",'r') as rf: train_lines = rf.readlines() for train_line in train_lines: train_line_temp = train_line.split(",") train_line_temp = map(float, train_line_temp) # 转化为浮点数 line_x = train_line_temp[1:-1] line_y = train_line_temp[-1] resultX.append(line_x) resultY.append(line_y) X = np.array(resultX) Y = np.array(resultY) #fit_transform(partData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该partData进行转换transform,从而实现数据的标准化、归一化等等。。 X = min_max_scaler.fit_transform(X) #通过OneHotEncoder函数将Y值离散化成19维,例如3离散成000000···100 Y = OneHotEncoder(sparse = False).fit_transform(Y.reshape(-1,1)) X_train,X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.2) model = OneVsRestClassifier(XGBClassifier(),n_jobs=2) clf = model.fit(X_train, Y_train) pre_Y = clf.predict(X_test) test_auc2 = roc_auc_score(Y_test,pre_Y)#验证集上的auc值 print ("xgb_muliclass_auc:",test_auc2)以上这篇使用sklearn对多分类的每个类别进行指标评价操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
- << 上一篇 下一篇 >>
- 相关文章
- 2021-12-20python数据挖掘使用Evidently创建机器学习模型仪表板
- 2021-12-20Python多进程共享numpy 数组的方法
- 2021-12-20python数据分析近年比特币价格涨幅趋势分布
- 2021-12-20python调用matlab的方法详解
- 2021-12-20python学习与数据挖掘应知应会的十大终端命令
- 2021-07-20pandas中NaN缺失值的处理方法
- 2021-07-20Python数据分析入门之数据读取与存储
- 2021-07-20Python 如何读取字典的所有键-值对
- 2021-07-20如何获取numpy的第一个非0元素索引
- 2021-07-20Python机器学习之KNN近邻算法
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!