介绍
在操作数据帧时,初学者有时甚至是更高级的数据科学家会对如何在pandas中使用inplace参数感到困惑。
更有趣的是,我看到的解释这个概念的文章或教程并不多。它似乎被假定为知识或自我解释的概念。不幸的是,这对每个人来说都不是那么简单,因此本文试图解释什么是inplace参数以及如何正确使用它。
让我们来看看一些使用inplace的函数的例子:
- fillna()
- dropna()
- sort_values()
- reset_index()
- sort_index()
- rename()
我已经创建了这个列表,可能还有更多的函数使用inplace作为参数。我没有记住所有这些函数,但是作为参数的几乎所有pandas DataFrame函数都将以类似的方式运行。这意味着在处理它们时,您将能够应用本文将介绍的相同逻辑。
创建一个示例DataFrame
为了说明inplace的用法,我们将创建一个示例DataFrame。
import pandas as pd import numpy as np client_dictionary = {'name': ['Michael', 'Ana', 'Sean', 'Carl', 'Bob'], 'second name': [None, 'Angel', 'Ben', 'Frank', 'Daniel'], 'birth place': ['New York', 'New York', 'Los Angeles', 'New York', 'New York'], 'age': [10, 35, 56, None, 28], 'number of children': [0, None, 2, 1, 1]} df = pd.DataFrame(client_dictionary) df.head()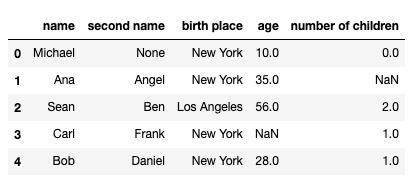
我们创建了一个数据框架,该数据框架有5行,列如下: name, second name, birthplace,age,number of children。注意,age、second name和children列中有一些缺失值(nan)。
现在我们将演示dropna()函数如何使用inplace参数工作。因为我们想要检查两个不同的变体,所以我们将创建原始数据框架的两个副本。
df_1 = df.copy() df_2 = df.copy()下面的代码将删除所有缺少值的行。
df_1.dropna(inplace=True)如果您在Jupyter notebook中运行此操作,您将看到单元格没有输出。这是因为inplace=True函数不返回任何内容。它用所需的操作修改现有的数据帧,并在原始数据帧上“就地”(inplace)执行。
如果在数据帧上运行head()函数,应该会看到有两行被删除。
df_1.dropna(inplace=True)现在我们用inplace = False运行相同的代码。注意,这次我们将使用df_2版本的df
df_2.dropna(inplace=False)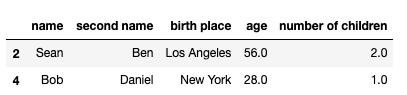
如果您在Jupyter notebook中运行此代码,您将看到有一个输出(上面的屏幕截图)。inplace = False函数将返回包含删除行的数据。
记住,当inplace被设置为True时,不会返回任何东西,但是原始数据被修改了。
那么这一次原始数据会发生什么呢?让我们调用head()函数进行检查。
df_2.head()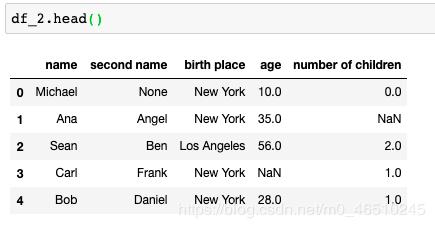
原始数据不变!那么发生了什么?
当您使用inplace=True时,将创建并更改新对象,而不是原始数据。如果您希望更新原始数据以反映已删除的行,则必须将结果重新分配到原始数据中,如下面的代码所示。
df_2 = df_2.dropna(inplace=False)这正是我们在使用inplace=True时所做的。是的,最后一行代码等价于下面一行:
df_2.dropna(inplace=True)后者更优雅,并且不创建中间对象,然后将其重新分配给原始变量。它直接改变原始数据框架,因此,如果需要改变原始数据,那么inplace=True是首选。
那么,为什么会有在使用inplace=True产生错误呢?我不太确定,可能是因为有些人还不知道如何正确使用这个参数。让我们看看一些常见的错误。
常见错误
使用
inplace = True处理一个片段如果我们只是想去掉第二个name和age列中的NaN,而保留number of children列不变,我们该怎么办?
我见过有人这样做:
df[['second name', 'age']].dropna(inplace=True)这会抛出以下警告。

这个警告之所以出现是因为Pandas设计师很好,他们实际上是在警告你不要做你可能不想做的事情。该代码正在更改只有两列的dataframe,而不是原始数据框架。这样做的原因是,您选择了dataframe的一个片段,并将dropna()应用到这个片段,而不是原始dataframe。
为了纠正它,可以这样使用
df.dropna(inplace=True, subset=['second name', 'age']) df.head()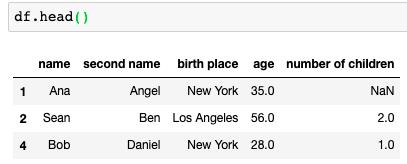
这将导致从dataframe中删除第二个name和age列中值为空的行。
将变量值赋给inplace= True的结果
df = df.dropna(inplace=True)这又是你永远不应该做的事情!你只需要将None重新赋值给df。记住,当你使用inplace=True时,什么也不会返回。因此,这段代码的结果是将把None分配给df。
总结
我希望本文为您揭开inplace参数的神秘面纱,您将能够在您的代码中正确地使用它。
到此这篇关于快速解释如何使用pandas的inplace参数的使用的文章就介绍到这了,更多相关pandas inplace参数内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
- << 上一篇 下一篇 >>
快速解释如何使用pandas的inplace参数的使用
看: 1783次 时间:2020-08-24 分类 : 数据分析
- 相关文章
- 2021-12-20python数据挖掘使用Evidently创建机器学习模型仪表板
- 2021-12-20Python多进程共享numpy 数组的方法
- 2021-12-20python数据分析近年比特币价格涨幅趋势分布
- 2021-12-20python调用matlab的方法详解
- 2021-12-20python学习与数据挖掘应知应会的十大终端命令
- 2021-07-20pandas中NaN缺失值的处理方法
- 2021-07-20Python数据分析入门之数据读取与存储
- 2021-07-20Python 如何读取字典的所有键-值对
- 2021-07-20如何获取numpy的第一个非0元素索引
- 2021-07-20Python机器学习之KNN近邻算法
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!