最近在倒腾一个txt文件,因为文件太大,所以给切割成了好几个小的文件,只有第一个文件有标题,从第二个开始就没有标题了。
我的需求是取出指定的列的数据,踩了些坑给研究出来了。
import pandas as pd # 我们的需求是 取出所有的姓名 # test1的内容 ''' id name score 1 张三 100 2 李四 99 3 王五 98 ''' test1 = pd.read_table("test1.txt") # 这个是带有标题的文件 names = test1["name"] # 根据标题来取值 print(names) ''' 张三 李四 王五 ''' # test2的内容 ''' 4 Allen 100 5 Bob 99 6 Candy 98 ''' test2 = pd.read_table("test2.txt", header=None) # 这个是没有标题的文件 names = test2[1] # 根据index来取值 print(names) ''' Allen Bob Candy '''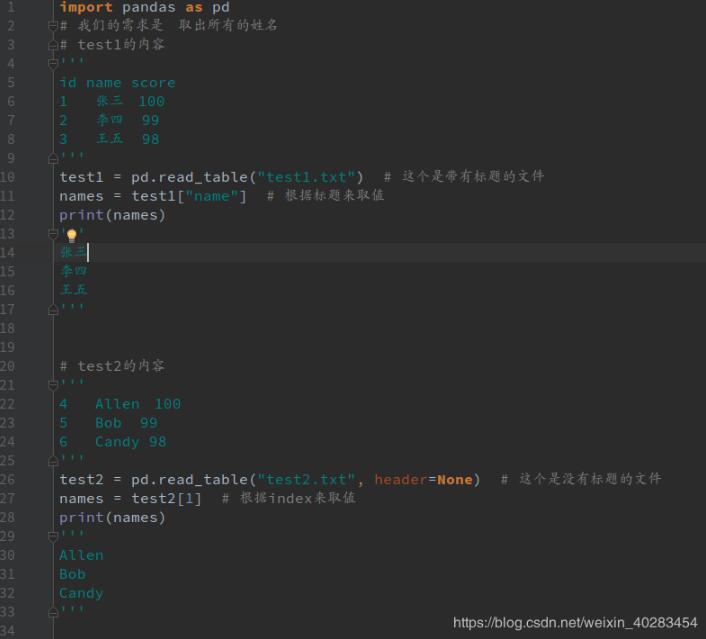
补充知识:关于python中pandas读取txt文件注意事项
语法:pandas.read_table()
参数:
filepath_or_buffer 文件路径或者输入对象
sep 分隔符,默认为制表符
names 读取哪些列以及读取列的顺序,默认按顺序读取所有列
engine 文件路径包含中文的时候,需要设置engine = ‘python'
encoding 文件编码,默认使用计算机操作系统的文字编码
na_values 指定空值,例如可指定null,NULL,NA,None等为空值常见错误:设置不全
import pandas data = pandas.read_table(‘D/anaconda/数据分析/文本.txt', engine=‘python') print(data)输出结果:

补全代码:
import pandas data = pandas.read_table(‘D/anadondas/数据分析/文本.txt', sep = ‘,' ,#指定分隔符‘,',默认为制表符 names = [‘names',‘age'],#设置列名,默认将第一行数据作为列名 engine = ‘python', encoding = ‘utf8'#指定编码格式) print(data)输出结果:

以上这篇如何使用pandas读取txt文件中指定的列(有无标题)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:pandas
如何使用pandas读取txt文件中指定的列(有无标题)
看: 2303次 时间:2020-08-07 分类 : 数据分析
- 相关文章
- 2021-12-20python数据挖掘使用Evidently创建机器学习模型仪表板
- 2021-12-20Python多进程共享numpy 数组的方法
- 2021-12-20python数据分析近年比特币价格涨幅趋势分布
- 2021-12-20python调用matlab的方法详解
- 2021-12-20python学习与数据挖掘应知应会的十大终端命令
- 2021-07-20pandas中NaN缺失值的处理方法
- 2021-07-20Python数据分析入门之数据读取与存储
- 2021-07-20Python 如何读取字典的所有键-值对
- 2021-07-20如何获取numpy的第一个非0元素索引
- 2021-07-20Python机器学习之KNN近邻算法
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!