numpy的np.fromfile会出现如下的问题,只能一次性读取文件的内容,不能追加读取,连续两次的np.fromfile读到的东西一样
如果数据文件太大(几个G或以上)不能一次性全读进去,需要追加读取
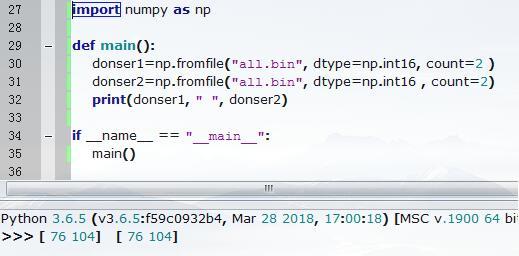
而我希望读到的donser1和donser2是连续的两段
(实际使用时,比如说读取的文件是二进制数据文件,每一块文件都包括包头+数据,希望将这两块分开获取,然后再做进一步处理)
代码:
import numpy as np length=2500 plt_arr=np.linspace(0.0, 0.0, length*2048*16) start=0 tail_size = 40 #40bit num_size=16*1024-40 # 16kb -40b def one_file(f, loop): global tail_size, num_size while loop: num = np.fromfile(f, dtype=np.int16, count=num_size) tail=np.fromfile(f, dtype=np.int16, count=tail_size) loop=loop-1 yield num, tail def main(): file_path="E://1-gl300c.r3f" global length, plt_arr, start loop=length with open(file_path, 'rb') as f: for num, tail in one_file(f, loop): plt_arr[start:start+len(num)]=num[:] start=start+len(num) return plt_arr[0:start] if __name__ == "__main__": donser=main() print(donser)假设数据文件的格式是 数据+包尾,plt_arr存储全部的数据部分,包尾丢弃,该方法实现了多次连续追加读取数据文件的内容plt_arr最好使用先开好大小再逐次赋值,亲测append方法和concatenate方法时间效率极差或者不用numpy也可以,代码:
def read_in_chunks(filePath, chunk_size=16*1024): file_object = open(filePath,'rb') count=0 while True: chunk_data = file_object.read(chunk_size) if not chunk_data: break yield chunk_data[0:16*1024-28] if __name__ == "__main__": num=0 for chunk in read_in_chunks("E:\\1-gl300c.r3f"): #process(chunk) # <do something with chunk> name=str(num)+".bin" num=num+1 if num<303000: continue if num>308001: break file_object = open(name, 'wb') file_object.write(chunk) file_object.close( )补充知识:python每隔一段时间运行一个函数
用python语言每隔两分钟从接口获取一次数据来插入到数据库
看了大佬们的方法感觉最简单就是:
做一个死循环,让函数执行完后休眠两分钟,然后进入下一次执行,除非手动停止或者有错误停止,否则程序会永远运行下去。
以下是代码:
import get_details import time second=2*60 print second while True: get_details.sign_cycle() time.sleep(second)上面的代码就是让get_details模块的sign_cycle()函数每两分钟执行一次。
是不是超简单!!!!!!
以上这篇python numpy实现多次循环读取文件 等间隔过滤数据示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:numpy
python numpy实现多次循环读取文件 等间隔过滤数据示例
看: 1576次 时间:2020-08-02 分类 : 数据分析
- 相关文章
- 2021-12-20python数据挖掘使用Evidently创建机器学习模型仪表板
- 2021-12-20Python多进程共享numpy 数组的方法
- 2021-12-20python数据分析近年比特币价格涨幅趋势分布
- 2021-12-20python调用matlab的方法详解
- 2021-12-20python学习与数据挖掘应知应会的十大终端命令
- 2021-07-20pandas中NaN缺失值的处理方法
- 2021-07-20Python数据分析入门之数据读取与存储
- 2021-07-20Python 如何读取字典的所有键-值对
- 2021-07-20如何获取numpy的第一个非0元素索引
- 2021-07-20Python机器学习之KNN近邻算法
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!