使用Tensorflow 构建卷积神经网络,训练手势识别模型,使用opencv DNN 模块加载模型实时手势识别
效果如下: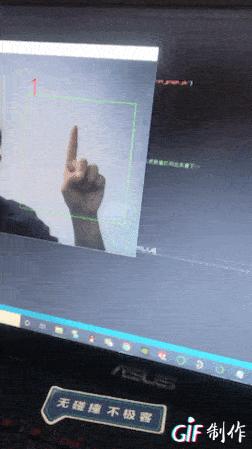
先显示下部分数据集图片(0到9的表示,感觉很怪)

构建模型进行训练
import tensorflow as tf from tensorflow import keras from tensorflow.keras import datasets,layers,optimizers,Sequential,metrics from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2 import os import pathlib import random import matplotlib.pyplot as plt os.environ['TF_CPP_MIN_LOG_LEVEL']='2' def read_data(path): path_root = pathlib.Path(path) # print(path_root) # for item in path_root.iterdir(): # print(item) image_paths = list(path_root.glob('*/*')) image_paths = [str(path) for path in image_paths] random.shuffle(image_paths) image_count = len(image_paths) # print(image_count) # print(image_paths[:10]) label_names = sorted(item.name for item in path_root.glob('*/') if item.is_dir()) # print(label_names) label_name_index = dict((name, index) for index, name in enumerate(label_names)) # print(label_name_index) image_labels = [label_name_index[pathlib.Path(path).parent.name] for path in image_paths] # print("First 10 labels indices: ", image_labels[:10]) return image_paths,image_labels,image_count def preprocess_image(image): image = tf.image.decode_jpeg(image, channels=3) image = tf.image.resize(image, [100, 100]) image /= 255.0 # normalize to [0,1] range # image = tf.reshape(image,[100*100*3]) return image def load_and_preprocess_image(path,label): image = tf.io.read_file(path) return preprocess_image(image),label def creat_dataset(image_paths,image_labels,bitch_size): db = tf.data.Dataset.from_tensor_slices((image_paths, image_labels)) dataset = db.map(load_and_preprocess_image).batch(bitch_size) return dataset def train_model(train_data,test_data): #构建模型 network = keras.Sequential([ keras.layers.Conv2D(32,kernel_size=[5,5],padding="same",activation=tf.nn.relu), keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'), keras.layers.Conv2D(64,kernel_size=[3,3],padding="same",activation=tf.nn.relu), keras.layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'), keras.layers.Conv2D(64,kernel_size=[3,3],padding="same",activation=tf.nn.relu), keras.layers.Flatten(), keras.layers.Dense(512,activation='relu'), keras.layers.Dropout(0.5), keras.layers.Dense(128,activation='relu'), keras.layers.Dense(10)]) network.build(input_shape=(None,100,100,3)) network.summary() network.compile(optimizer=optimizers.SGD(lr=0.001), loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'] ) #模型训练 network.fit(train_data, epochs = 100,validation_data=test_data,validation_freq=2) network.evaluate(test_data) tf.saved_model.save(network,'D:\\code\\PYTHON\\gesture_recognition\\model\\') print("保存模型成功") # Convert Keras model to ConcreteFunction full_model = tf.function(lambda x: network(x)) full_model = full_model.get_concrete_function( tf.TensorSpec(network.inputs[0].shape, network.inputs[0].dtype)) # Get frozen ConcreteFunction frozen_func = convert_variables_to_constants_v2(full_model) frozen_func.graph.as_graph_def() layers = [op.name for op in frozen_func.graph.get_operations()] print("-" * 50) print("Frozen model layers: ") for layer in layers: print(layer) print("-" * 50) print("Frozen model inputs: ") print(frozen_func.inputs) print("Frozen model outputs: ") print(frozen_func.outputs) # Save frozen graph from frozen ConcreteFunction to hard drive tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir="D:\\code\\PYTHON\\gesture_recognition\\model\\frozen_model\\", name="frozen_graph.pb", as_text=False) print("模型转换完成,训练结束") if __name__ == "__main__": print(tf.__version__) train_path = 'D:\\code\\PYTHON\\gesture_recognition\\Dataset' test_path = 'D:\\code\\PYTHON\\gesture_recognition\\testdata' image_paths,image_labels,_ = read_data(train_path) train_data = creat_dataset(image_paths,image_labels,16) image_paths,image_labels,_ = read_data(test_path) test_data = creat_dataset(image_paths,image_labels,16) train_model(train_data,test_data)OpenCV加载模型,实时检测
这里为了简化检测使用了ROI。
import cv2 from cv2 import dnn import numpy as np print(cv2.__version__) class_name = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] net = dnn.readNetFromTensorflow('D:\\code\\PYTHON\\gesture_recognition\\model\\frozen_model\\frozen_graph.pb') cap = cv2.VideoCapture(0) i = 0 while True: _,frame= cap.read() src_image = frame cv2.rectangle(src_image, (300, 100),(600, 400), (0, 255, 0), 1, 4) frame = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB) pic = frame[100:400,300:600] cv2.imshow("pic1", pic) # print(pic.shape) pic = cv2.resize(pic,(100,100)) blob = cv2.dnn.blobFromImage(pic, scalefactor=1.0/225., size=(100, 100), mean=(0, 0, 0), swapRB=False, crop=False) # blob = np.transpose(blob, (0,2,3,1)) net.setInput(blob) out = net.forward() out = out.flatten() classId = np.argmax(out) # print("classId",classId) print("预测结果为:",class_name[classId]) src_image = cv2.putText(src_image,str(classId),(300,100), cv2.FONT_HERSHEY_SIMPLEX, 2,(0,0,255),2,4) # cv.putText(img, text, org, fontFace, fontScale, fontcolor, thickness, lineType) cv2.imshow("pic",src_image) if cv2.waitKey(10) == ord('0'): break小结
这里本质上还是一个图像分类任务。而且,样本数量较少。优化的时候需要做数据增强,还需要防止过拟合。
到此这篇关于TensorFlow2.X结合OpenCV 实现手势识别功能的文章就介绍到这了,更多相关TensorFlow OpenCV 手势识别内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
标签:numpy matplotlib
TensorFlow2.X结合OpenCV 实现手势识别功能
看: 1583次 时间:2020-07-22 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!