目录
我们知道 Pandas 是数据科学社区中流行的 Python 包,它包含许多函数和方法来分析数据。尽管它的功能对于数据分析来说足够有效,但定制的库可以为 Pandas 增加更多的价值。
Sidetable 就是一个开源 Python 库,它是一种可用于数据分析和探索的工具,作为 value_counts 和 crosstab 的功能组合使用的。在本文中,我们将更多地讨论和探索其功能。欢迎收藏学习、点赞支持。
安装
可以使用从 PyPI 安装 Sidetable
pip install sidetable用法
我们将使用从 Kaggle 下载的 Titanic 数据集来实现该库。
sidetable 的思想是减少数据分析所需的代码行数并加快工作流程。对于任何数据集,都需要执行一些数据分析任务,包括可视化特征分布、频率计数、缺失记录计数。
我们将使用 Titanic 数据集详细讨论 Sidetable 库的特性。
1、freq()
Pandas 提供了 value_counts() 函数,用于计算特征的频率计数。Pandas 可以计算分布计数和概率分布,但你可能希望更容易组合这些值。

分布计数和概率分布可以结合使用,但需要大量的输入和代码记忆。
对于 sidetable,使用 freq() 函数在一行Python代码中实现它更简单。你可以获得累计总数、百分比和更大的灵活性。
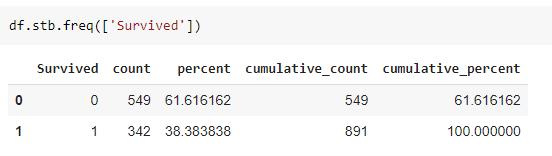
除此之外,还可以对多个列进行分组,以可视化已分组要素的分布。

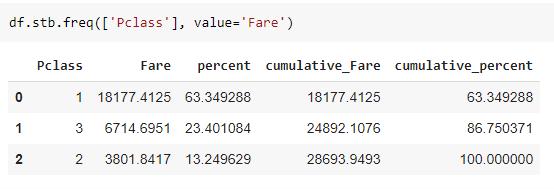
你还可以使用参数 value 指定要素列,以指示分组的数据“sum”应基于特定列。
2、Counts
sidetable 中的 counts() 函数可以生成一个汇总表,该汇总表可用于确定你需要考虑为分类或数值的特征,以便进一步分析和建模。counts() 函数显示特征的唯一值的数量以及最频繁和最不频繁的值。
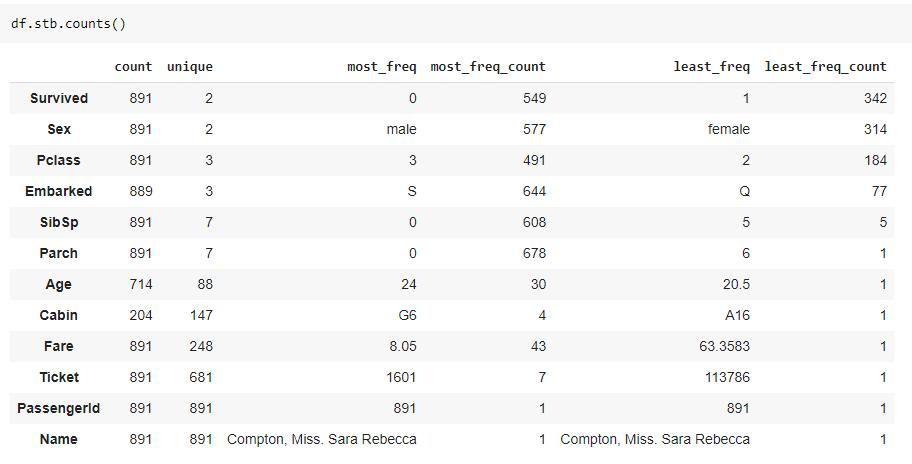
可以使用 exclude 和 include 参数从数据集中排除或包含特定数据类型。
3、missing()
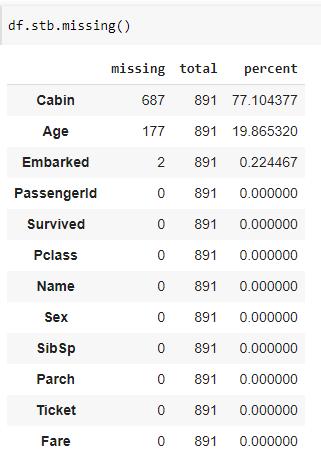
sidetable 中 missing()函数生成一个汇总表,该汇总表按每列的总缺失值的计数和百分比显示缺失记录。
4、subtotal()
Sidetable 中 subtotal() 函数最适合与 Pandas 中的 group by 函数一起使用。它可用于计算数据帧分组的一个或多个级别的小计。
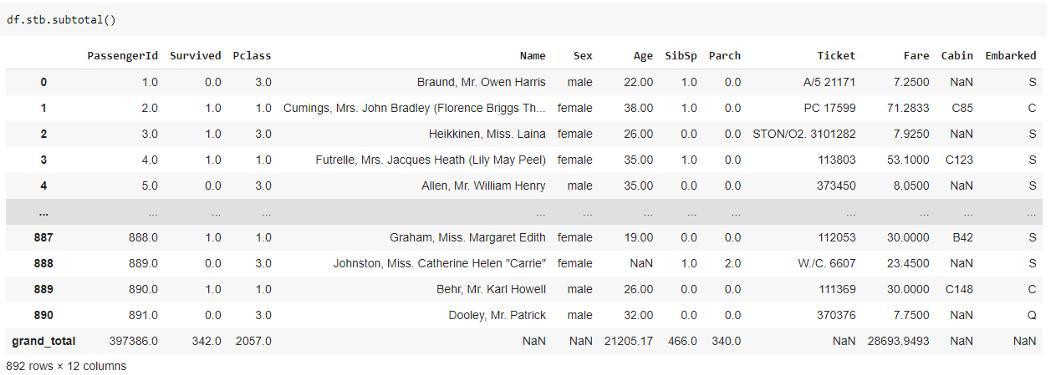
subtotal()函数可以将其添加到分组数据的一个或多个级别。你需要首先使用groupby()函数对数据框进行分组,然后在每个级别添加一个小计。

结论
Sidetable 是一种高效且方便的工具,它结合了 Pandas 的 value_counts 和 crosstab,生成一个可解释且易于理解的汇总表,还可用于提供分析结果。语法的简单性使其成为用于数据分析和探索的更好的库。
以上就是这款高效的python数据框 处理工具Sidetable的详细内容了。
更多python数据框 处理工具Sidetable的内容请关注python博客其他相关文章。
<< 上一篇 下一篇 >>- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!