目录
一、首先我们要找到目标
找到目标先分析一下网页(url:https://list.iqiyi.com/www/1/-------------11-1-1-iqiyi–.html),很幸运这个只有一个网页,不需要翻页。
二、F12查看网页源代码
找到目标,分析如何获取需要的数据。找到href与电影名称
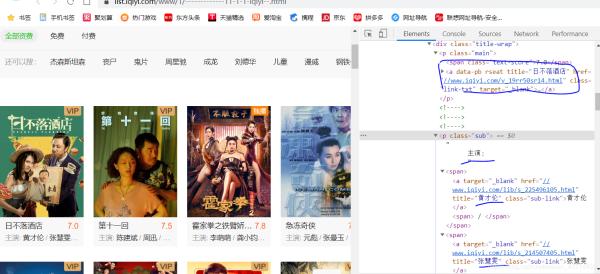
三、进行代码实现,获取想要资源。
''' 爬取爱奇艺电影与地址路径 操作步骤 1,获取到url内容 2,css选择其选择内容 3,保存自己需要数据 ''' #导入爬虫需要的包 import requests from bs4 import BeautifulSoup #requests与BeautifulSoup用来解析网页的 import time #设置访问网页时间,防止自己IP访问多了被限制拒绝访问 import re class Position(): def __init__(self,position_name,position_require,):#构建对象属性 self.position_name=position_name self.position_require=position_require def __str__(self): return '%s%s/n'%(self.position_name,self.position_require)#重载方法将输入变量改成字符串形式 class Aiqiyi(): def iqiyi(self,url): head= { 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47" } #模拟的服务器头 html = requests.get(url,headers=head) #headers=hard 让脚本以浏览器的方式去访问,有一些网址禁止以python的反爬机制,这就是其中一个 soup = BeautifulSoup(html.content, 'lxml', from_encoding='utf-8') # BeautifulSoup打看网页 soupl = soup.select(".qy-list-wrap") # 查找标签,用css选择器,选择自己需要数据 进行选择页面第一次内容(标签要找到唯一的,找id好,如果没有考虑其他标签如class) results = [] # 创建一个列表用来存储数据 for e in soupl: biao = e.select('.qy-mod-li') # 进行二次筛选 for h in biao: p=Position(h.select_one('.qy-mod-link-wrap').get_text(strip=True), h.select_one('.title-wrap').get_text(strip=True))#调用类转换(继续三次筛选选择自己需要内容) results.append(p) return results # 返回内容 def address(self,url): #保存网址 head = { 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47" } # 模拟的服务器头 html = requests.get(url, headers=head) soup = BeautifulSoup(html.content, 'lxml', from_encoding='utf-8') # BeautifulSoup打看网页 alist = soup.find('div', class_='qy-list-wrap').find_all("a") # 查找div块模块下的 a标签 ls=[] for i in alist: ls.append(i.get('href')) return ls if __name__ == '__main__': time.sleep(2) #设置2秒访问一次 a=Aiqiyi() url = "https://list.iqiyi.com/www/1/-------------11-1-1-iqiyi--.html" with open(file='e:/练习.txt ', mode='a+') as f: # e:/练习.txt 为我电脑新建的文件,a+为给内容进行添加,但不进行覆盖原内容。 for item in a.iqiyi(url): line = f'{item.position_name}\t{item.position_require}\n' f.write(line) # 采用方法 print("下载完成") with open(file='e:/地址.txt ', mode='a+') as f: # e:/练习.txt 为我电脑新建的文件,a+为给内容进行添加,但不进行覆盖原内容。 for item in a.address(url): line=f'https{item}\n' f.write(line) # 采用方法 print("下载完成")四、查看现象
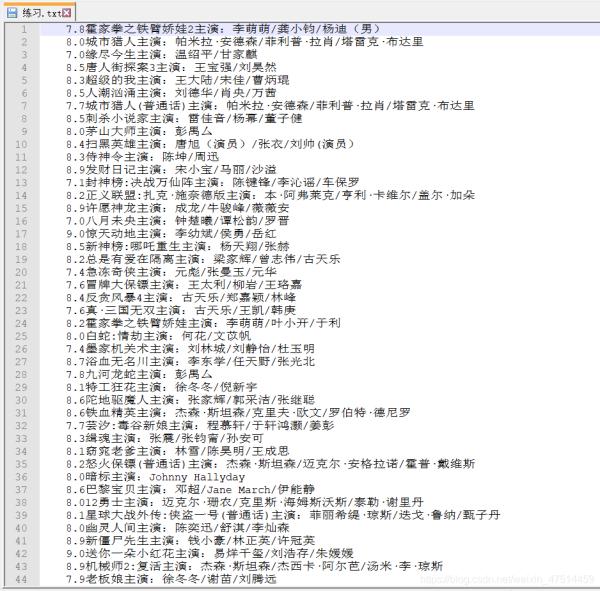
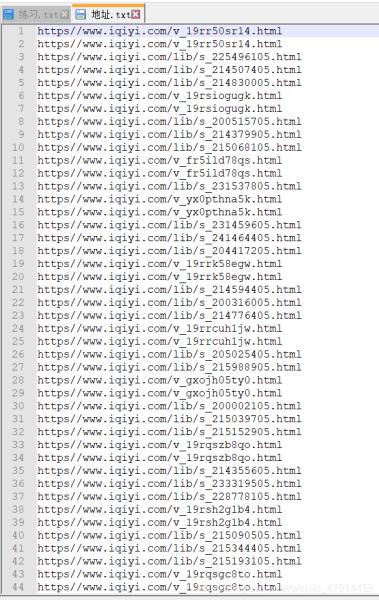
到此这篇关于教你怎么用python爬取爱奇艺热门电影的文章就介绍到这了,更多相关python爬取电影内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
<< 上一篇 下一篇 >>标签:requests
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!