一、Tensor
Tensor(张量是一个统称,其中包括很多类型):
0阶张量:标量、常数、0-D Tensor;1阶张量:向量、1-D Tensor;2阶张量:矩阵、2-D Tensor;……二、Pytorch如何创建张量
2.1 创建张量
import torch t = torch.Tensor([1, 2, 3]) print(t)
2.2 tensor与ndarray的关系
两者之间可以相互转化
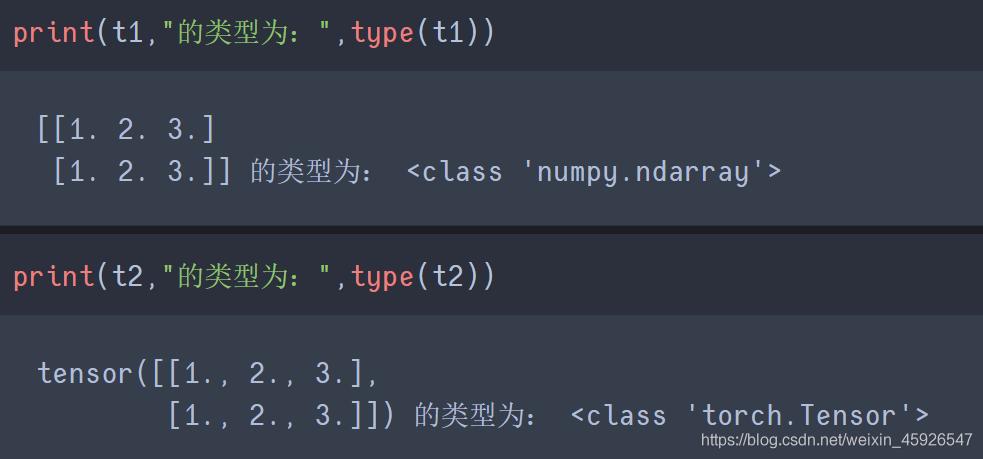
import torch import numpy as np t1 = np.array(torch.Tensor([[1, 2, 3], [1, 2, 3]])) t2 = torch.Tensor(np.array([[1, 2, 3], [1, 2, 3]]))运行结果:
2.3 常用api
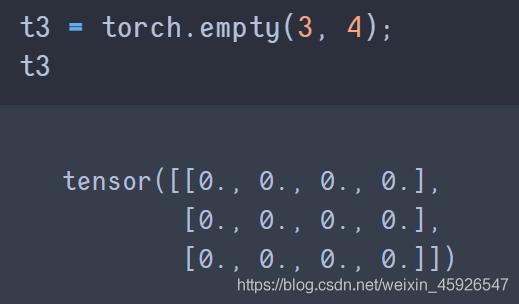
torch.empty(x,y)
创建x行y列为空的tensor。
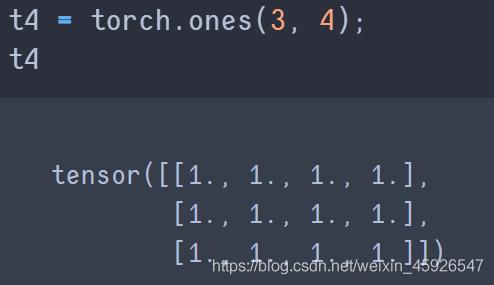
torch.ones([x, y])
创建x行y列全为1的tensor。
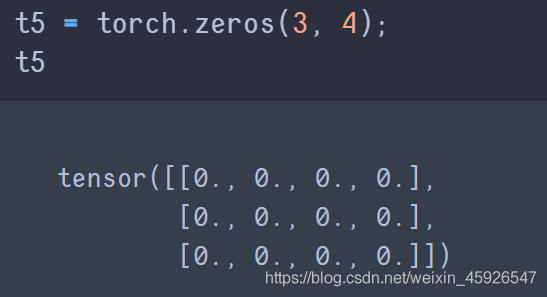
torch.zeros([x,y])
创建x行y列全为0的temsor。
zeros与empty的区别
后者的数据类型是不固定的。
torch.rand(x, y)
创建3行4列的随机数,随机数是0-1。
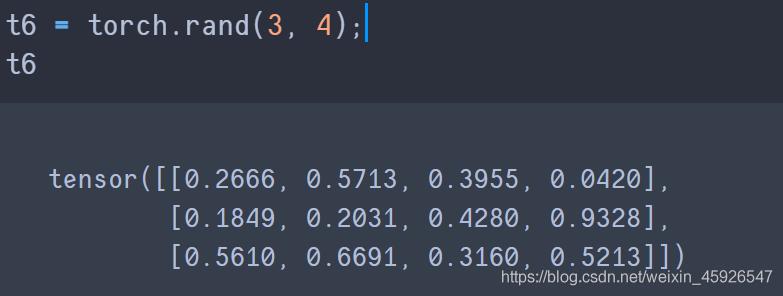
torch.randint(low, high, size)
创建一个size的tensor,随机数为low到high之间。

torch.randn([x, y])
创建一个x行y列的tensor,随机数的分布式均值为0,方差1。
2.4 常用方法
item():
获取tensor中的元素,注意只有
一个元素的时候才可以用。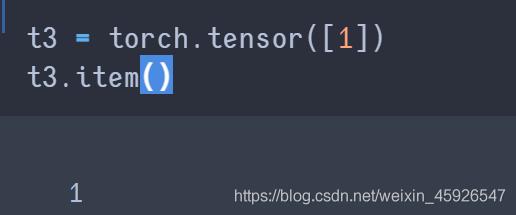
numpy():
转化成
ndarray类型。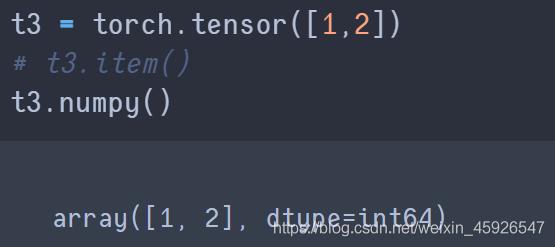
size()
获取tensor的
形状。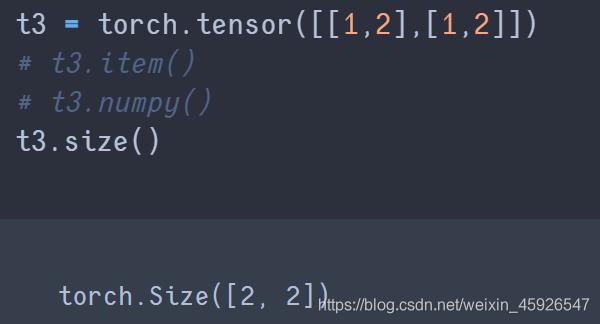
view()
可以传参,表示获取第几个。若参数为-1,表示不确定,与另一个参数的乘积等于原始形状的乘积。 例如:原始形状为8,则浅拷贝,tensor的形状改变。view(-1,2)⇒view(4, 2); 参数只有-1,表示一维。
dim()
获取维度。

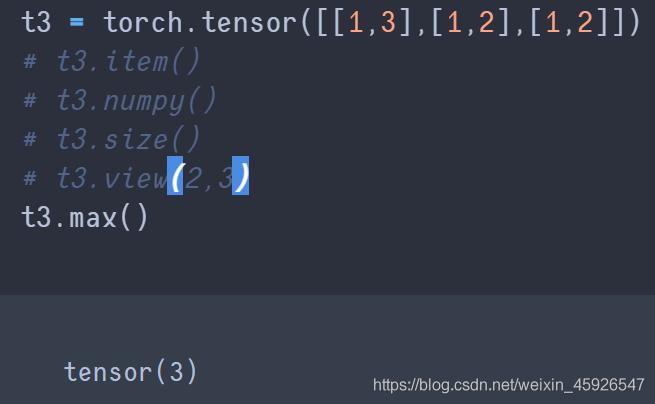
max()
获取最大值。
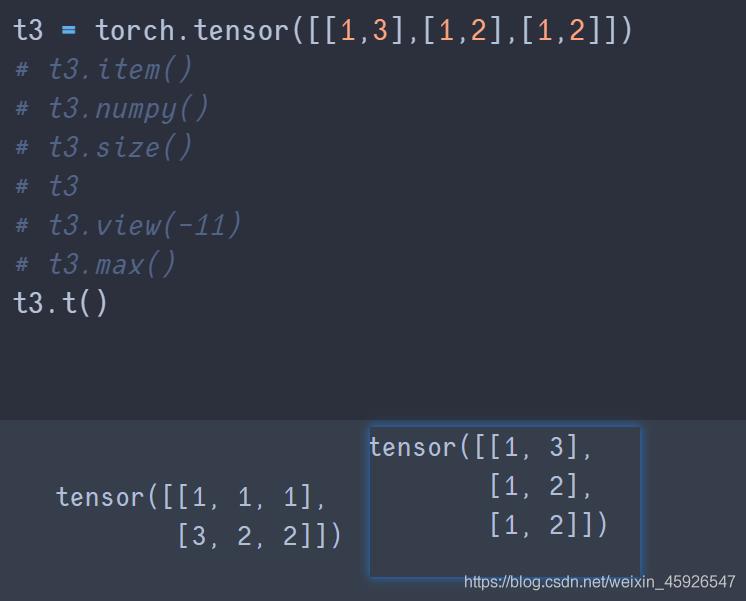
t()
转置。
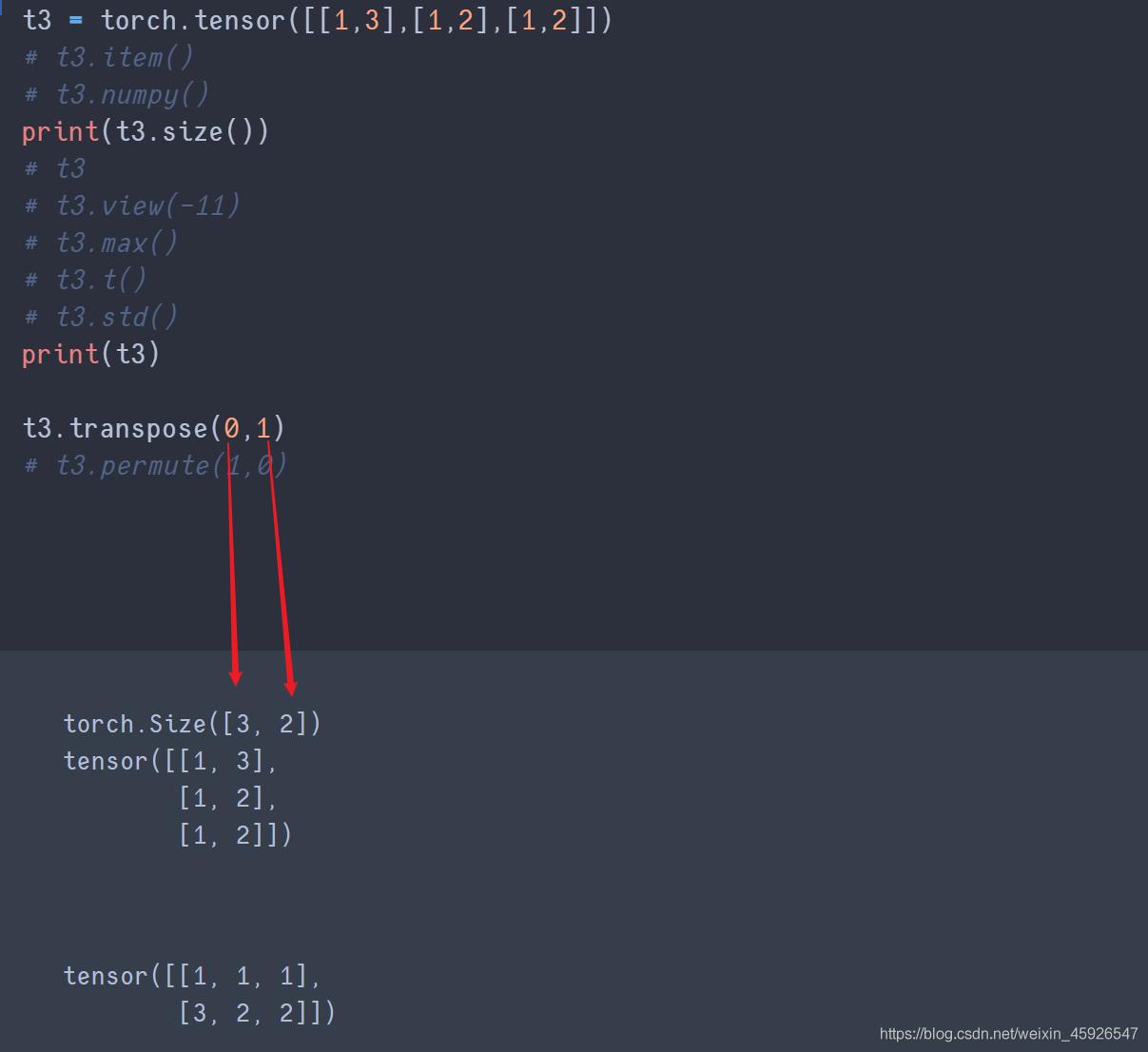
transpose(x,y)
x,y是size里面返回的形状相换。
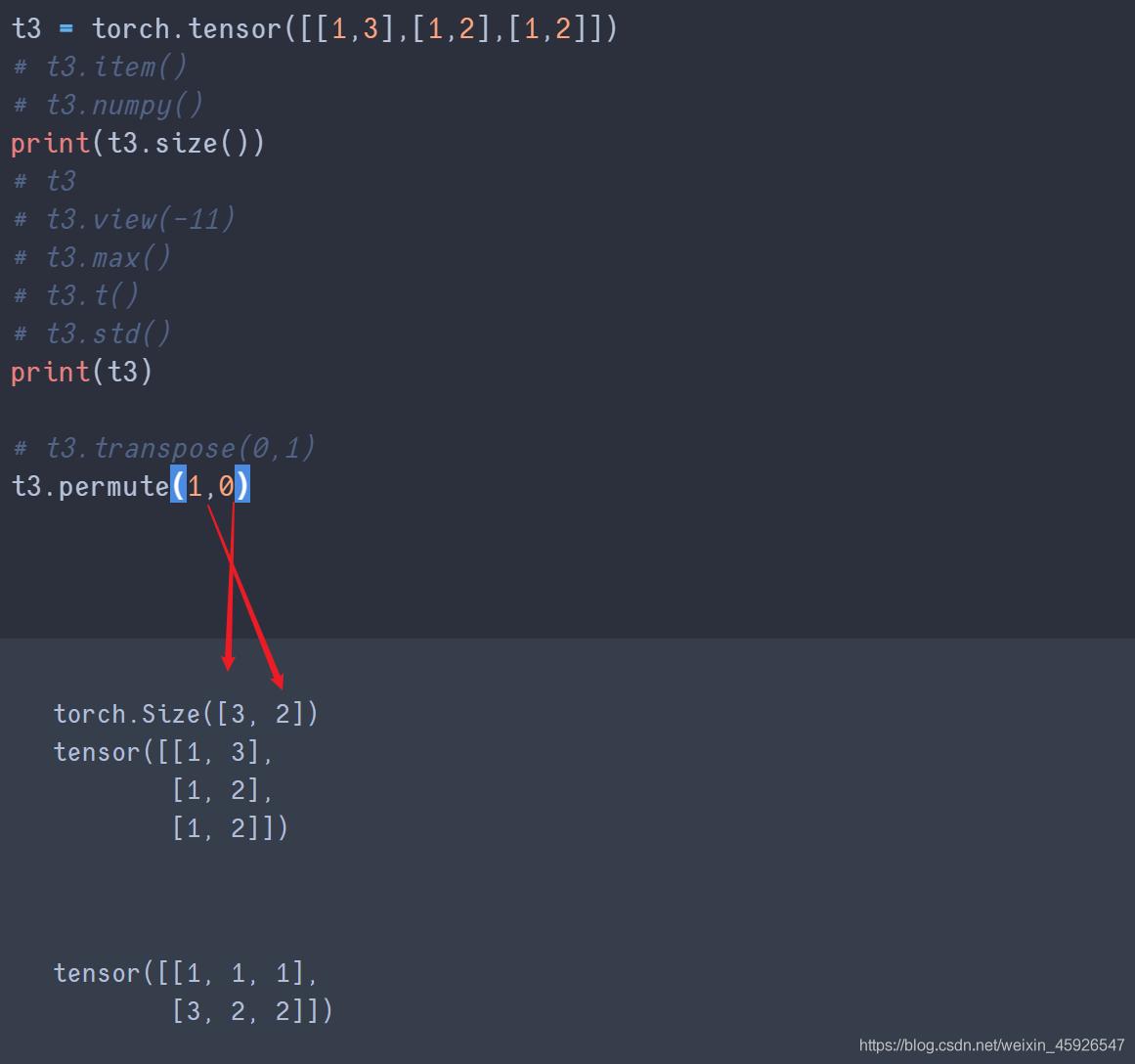
permute()
传入size()返回的形状的顺序。
transpose与permute的区别
前者传入列即可相互交换;后者传入列会根据传入的顺序来进行转化,且需要传入所有列数的索引。
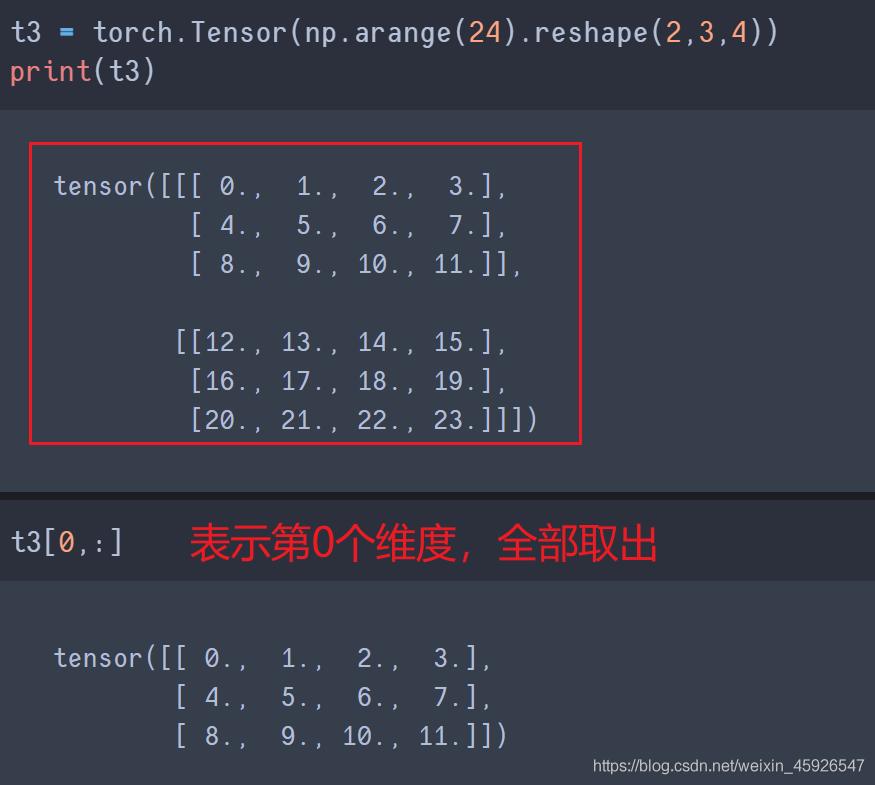
取值[第一阶, 第二阶,……]
一个逗号隔开代表一个阶乘冒号代表全取
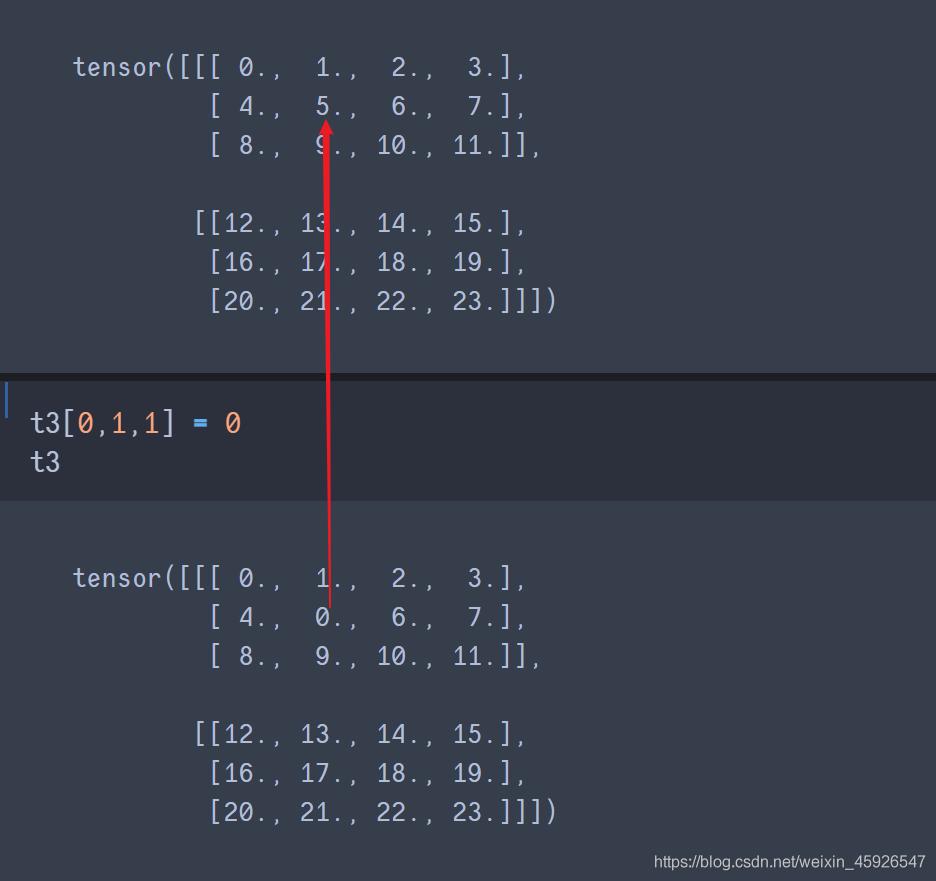
赋值[第一阶, 第二阶,……]
直接赋值即可
三、数据类型
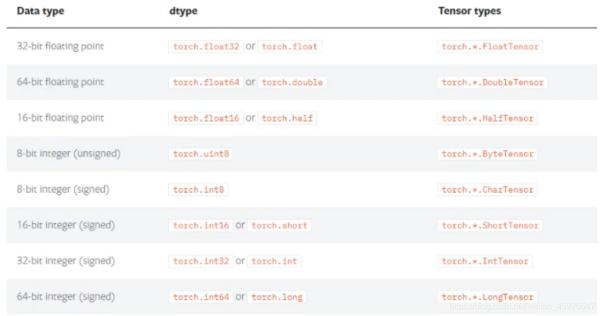
3.1 获取数据类型
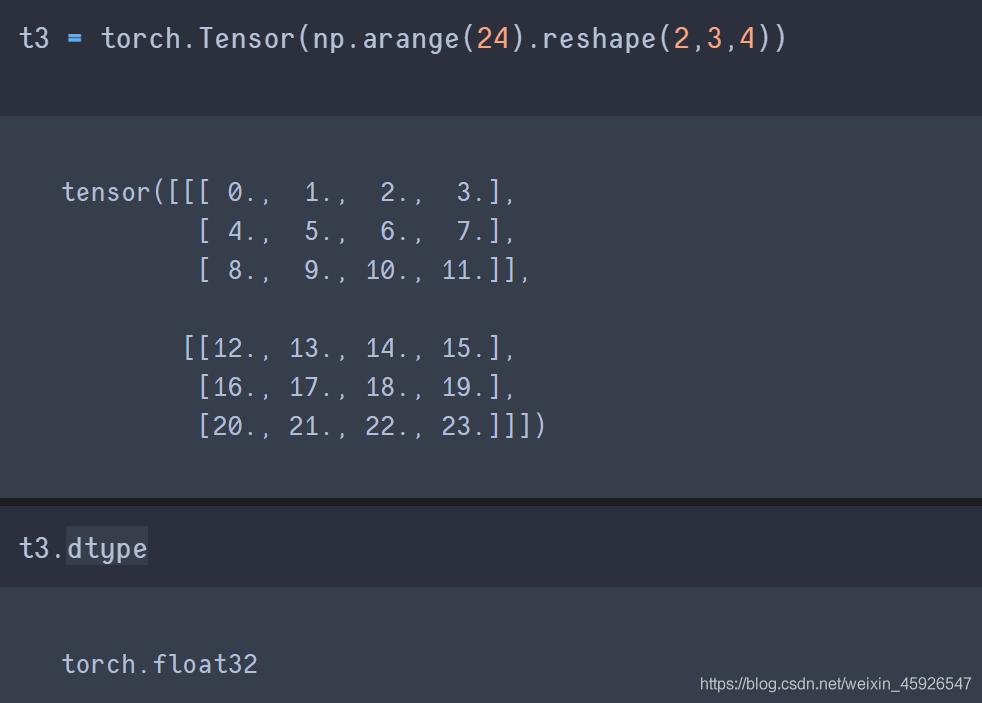
tensor.dtype
获取数据类型
设置数据类型
注意使用
Tensor()不能指定数据类型。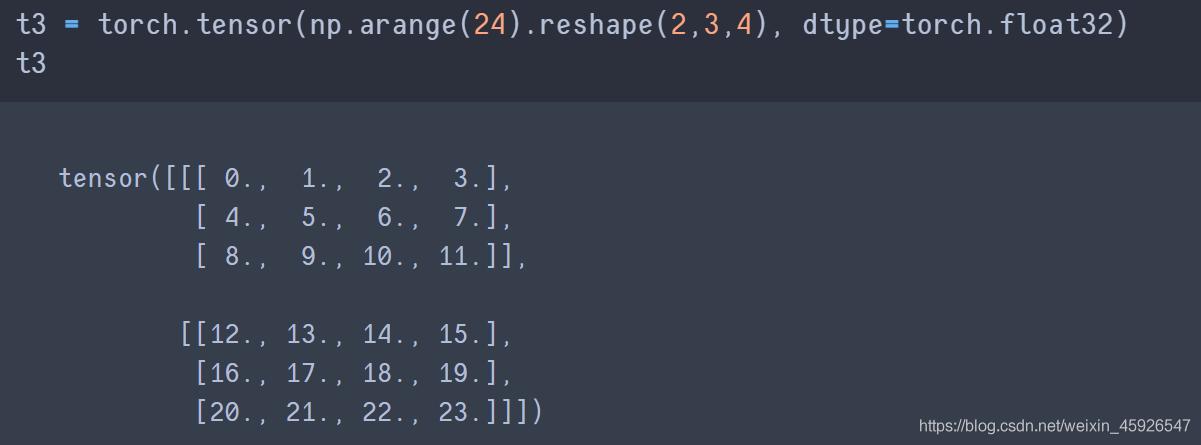
type()
修改数据类型。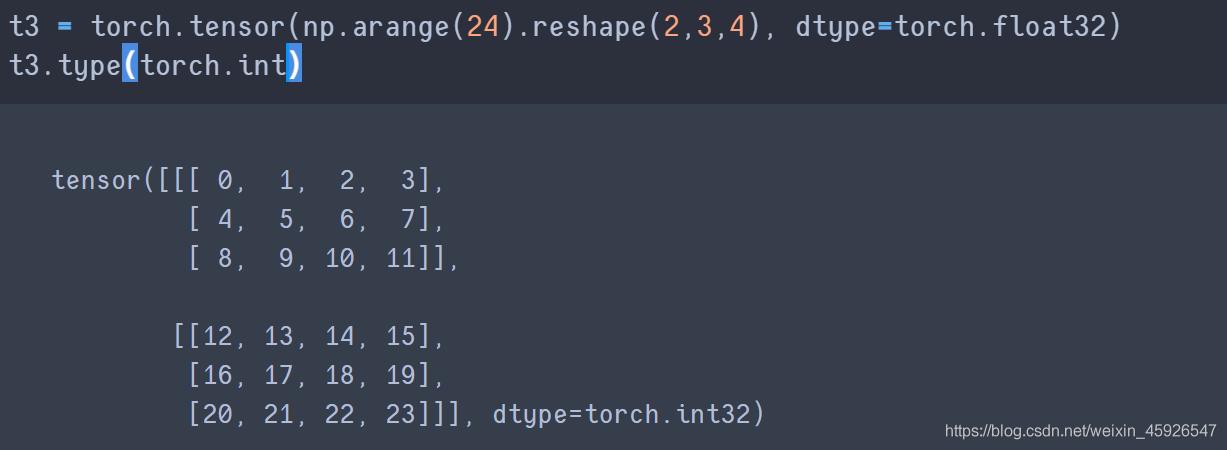
四、tensor的其他操作
4.1 相加
torch.add(x, y)
将x和y
相加。
直接相加
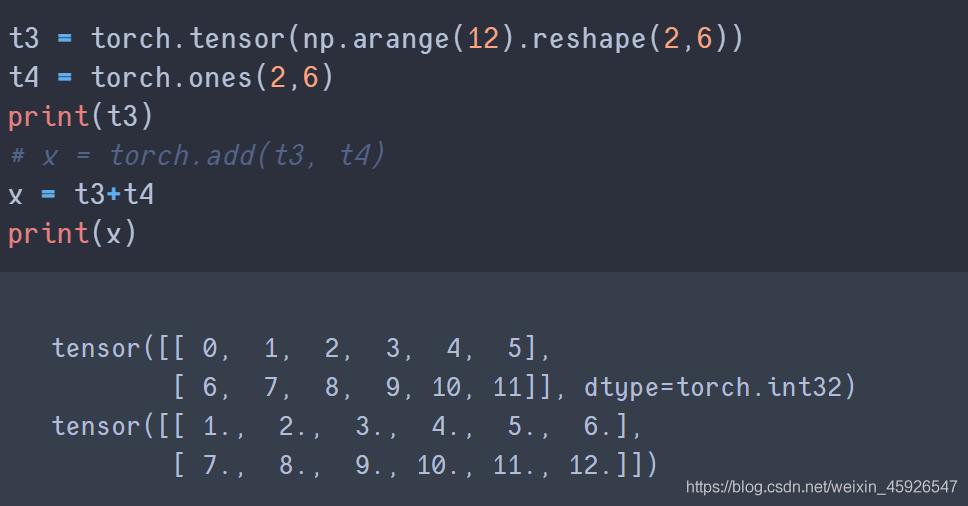
tensor.add()
使用
add_()可相加后直接保存在tensor中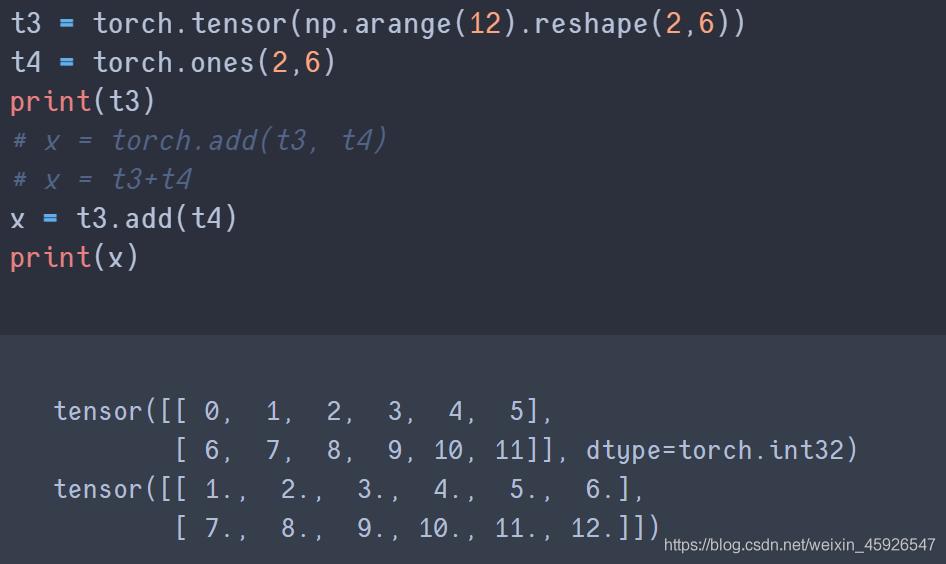
4.2 tensor与数字的操作
tensor + 数值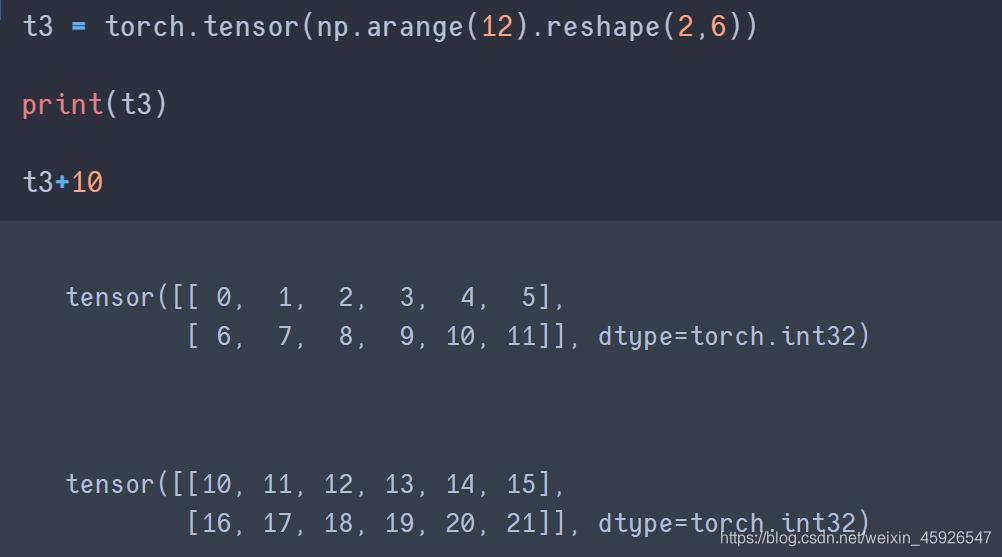
五、CUDA中的tensor
CUDA(Compute Unified Device Architecture),是NVIDIA推出的运算平台。CUDATM是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
torch.cuda这个模块增加了对CUDA tensor的支持,能够在cpu和gpu上使用相同的方法操作tensor通过.to方法能够把一个tensor转移到另外一个设备(比如从CPU转到GPU)可以使用
torch.cuda.is_available()判断电脑是否支持GPU到此这篇关于Python深度学习之Pytorch初步使用的文章就介绍到这了,更多相关Pytorch初步使用内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
标签:numpy
Python深度学习之Pytorch初步使用
看: 1488次 时间:2021-06-21 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!