常见的协议
http和https
http协议:
超文本传输协议,是一个发布和接受HTML页面的方法,端口是80https 协议:http协议的加密版本,在HTTP下加上了ssl层,端口是443
下面访问的是美团的官网:
可以看到端口是443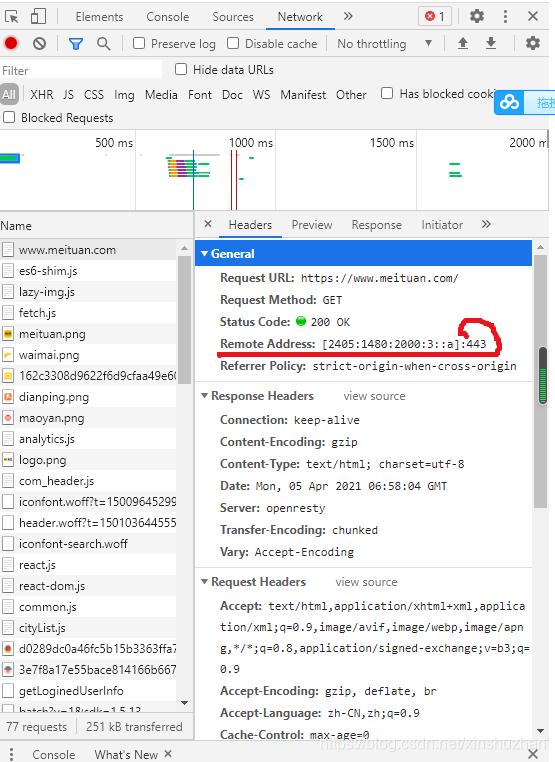
URL和RUI
常见的请求方式
http协议规定了浏览器与服务器进行数据交互过程中必须要选择一种交互方式
在http协议中定义了8中请求方式,常见的是get和post请求get请求: 一般只从服务器获取数据下来,并不会对服务器资源产生任何的影响。
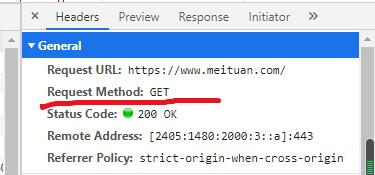
请求的时候关注:url请求方式请求头
post请求: 向服务器发送数据(登陆),上传文件等,会对服务器资源产生影响的时候,会使用post请求。
不过有些网站做了反爬虫机制,你去查看信息,也是使用post请求,所以我们写爬虫的时候,一定要分析网站。
常见的请求头参数:
http协议中,向服务器发送一个请求,数据分为三部分:
- 把数据放在url中
- 数据放在body中,(post请求)
- 数据放在head中
常见的请求头参数:
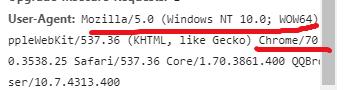
- user-agent :浏览器名称
- referer: 当前这个请求从哪个url过来的
- cookie:http 协议是无状态的,也就是一个人发送了两次请求,服务器没有能力知道这两个请求是否来自同一个人。
常见的相应状态码
- 200 请求正常,服务器正常返回数据
- 301 永久重定向
- 404 请求的url在服务器上找不到
- 418 发送请求遇到服务器端的反爬虫,服务器拒绝相应数据
- 500 服务器内部错误,可能是服务器出现了bug
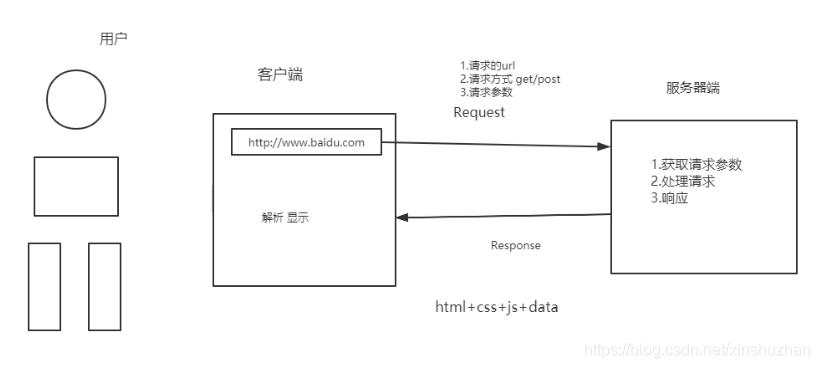
HTTP的请求相应过程
使用浏览器进行网站分析
我们要分析的网站为: movie.douban.com

- Elements: 用于分析网站的结构
在页面上的呈现的内容,在Elements都会有相应的元素。
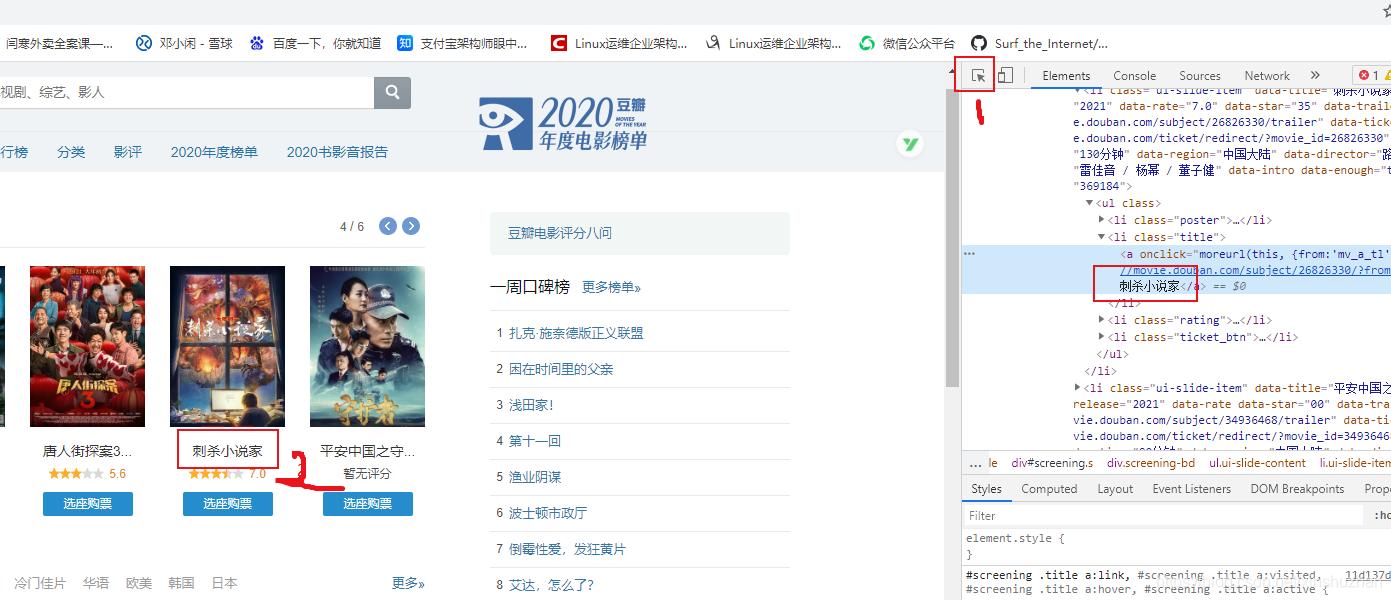
- Console: 这里会打印招聘信息,警告等等。
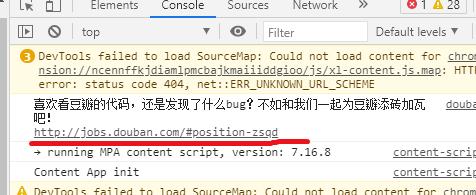
- Sources
- Network : 在显示页面的时候,产生的所有请求
headers 头部信息
session 与cookie
session代表的是服务器和浏览器的一次会话过程
session 是一种服务器端的机制,用来存储特定用户的会话所需要的信息,保存在内存,缓存,或者数据库中。cookie
cooke是由服务器端生成后发送给客户端,cookie是保存在客户端的cookie原理:
1) 创建cookie
2) 设置存储cookie
3) 发送cookie
4) 读取cookie到此这篇关于学习Python爬虫前,需要先掌握哪些知识内容的文章就介绍到这了,更多相关学习Python爬虫掌握知识内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
学习Python爬虫前必掌握知识点
看: 3253次 时间:2021-05-07 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!