机器学习
在吴恩达老师的课程中,有过对机器学习的定义:
ML:
P即performance,T即Task,E即Experience,机器学习是对一个Task,根据Experience,去提升Performance;
在机器学习中,神经网络的地位越来越重要,实践发现,非线性的激活函数有助于神经网络拟合分布,效果明显优于线性分类器:
y=Wx+b
常用激活函数有ReLU,sigmoid,tanh;
sigmoid将值映射到(0,1):
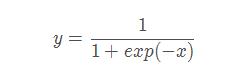
tanh会将输入映射到(-1,1)区间:
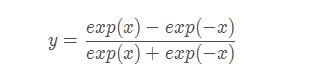
#激活函数tanh %matplotlib inline import matplotlib.pyplot as plt import numpy as np def tanh(x): return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x)) X=np.linspace(-5,5,100) plt.figure(figsize=(8,6)) ax=plt.gca()#get current axis:获取当前坐标系 #将该坐标系的右边缘和上边缘设为透明 ax.spines['right'].set_color('none') ax.spines['top'].set_color('none') #设置bottom是x轴 ax.xaxis.set_ticks_position('bottom') ax.spines['bottom'].set_position(('data',0)) #设置left为y轴 ax.yaxis.set_ticks_position('left') ax.spines['left'].set_position(('data',0)) ax.plot(X,tanh(X),color='blue',linewidth=1.0,linestyle="-") plt.show()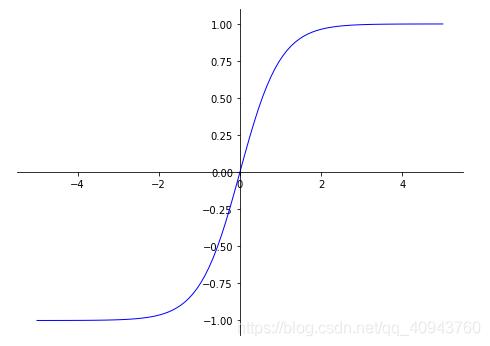
开源框架
当神经网络层数加深,可以加强捕捉分布的效果,可以简单认为深度学习指深层神经网络的学习;
当前有两大主流的深度学习框架:Pytorch和Tensorflow;
Pytorch支持动态计算图,使用起来更接近Python;
Tensorflow是静态计算图,使用起来就像一门新语言,据说简单易用的keras已经无人维护,合并到tensorflow;
一个深度学习项目的运行流程一般是:
v
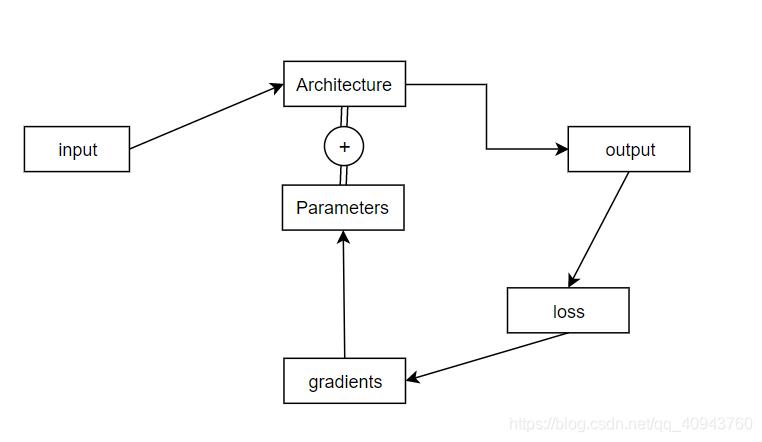
深度学习计算重复且体量巨大,所以需要将模型部署到GPU上,GPU的设计很适合加速深度学习计算,为了便于在GPU上开展深度学习实验,人们开发了CUDA架构,现在大部分DL模型都是基于CUDA加速的
关于CUDA
1.什么是CUDA?
CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
2.什么是CUDNN?
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中。
方向概览
当前计算机视觉的发展相对于自然语言处理更加成熟,NLP的训练比CV更耗费资源,CV模型相对较小;
在CV方向:
1.图像分类(ResNet,DenseNet)
- 目标检测ObjectDetection
- 风格迁移StyleTransfer
- CycleGAN:比如图像中马到斑马,也可以从斑马返回马
- ImageCaptioning:从图像生成描述文本,一般用CNN获得feature,再输入RNN获得文本
2.在NLP方向
- 情感分析:分类影评数据
- QuestionAnswering:一段问题->给出答案
- Translation:可以用OpenNMT-py,OpenNMT-py是开源的seq->seq模型
- ChatBot聊天机器人,基于QuestionAnswering,目前刚起步
另外还有强化学习Deep Reinforcement Learning,从简单的打砖块游戏到著名的阿尔法Go;
以及预训练语言模型:给一段话,让机器继续说下去,比如BERT,GPT2;
迁移学习
在CV中,NN的低层可以提取位置信息(边,角等精细信息),高层提取抽象信息,所以低层的网络可以反复使用,更改高层再训练以适用其他任务
到此这篇关于深度学习简介的文章就结束了,以后还会不断更新深度学习的文章,更多相关深度学习文章请搜索python博客以前的文章或继续浏览下面的相关文章,希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
标签:numpy matplotlib
理解深度学习之深度学习简介
看: 1562次 时间:2021-04-23 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!