当前位置:首页 » python web » 正文
基本开发环境
· Python 3.6
· Pycharm
相关模块使用

目标网页分析
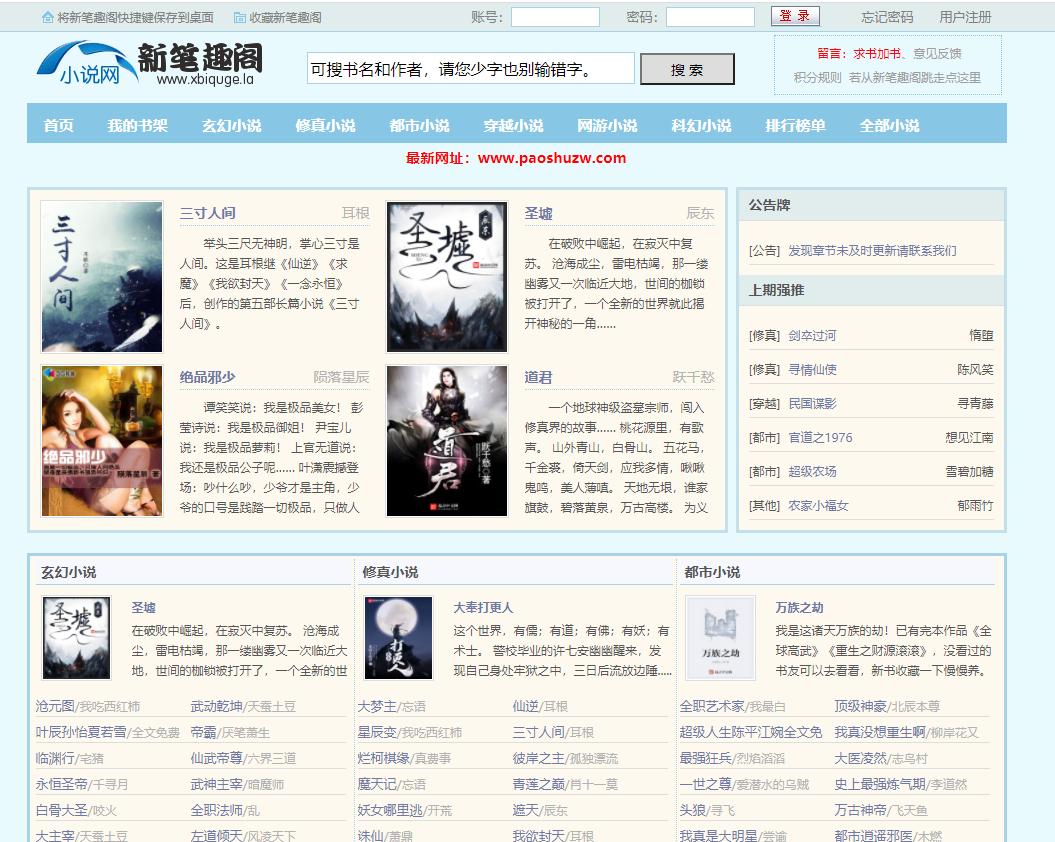
输入想看的小说内容,点击搜索
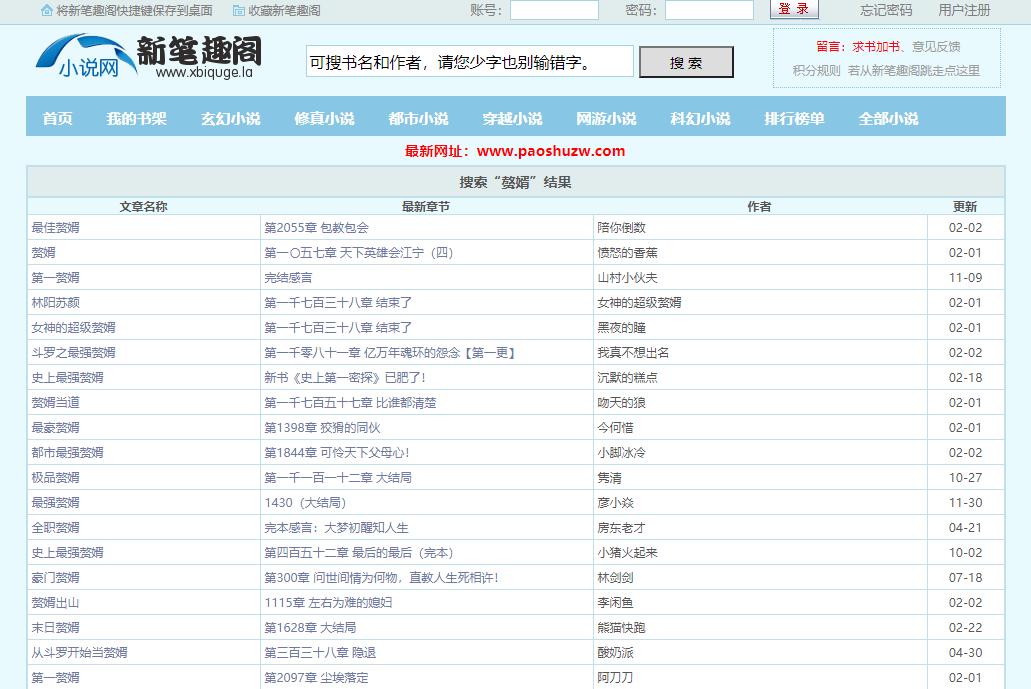
这里会返回很多结果,我只选择第一个
网页数据是静态数据,但是要搜索,是post请求,需要提价data参数,如下图所示:
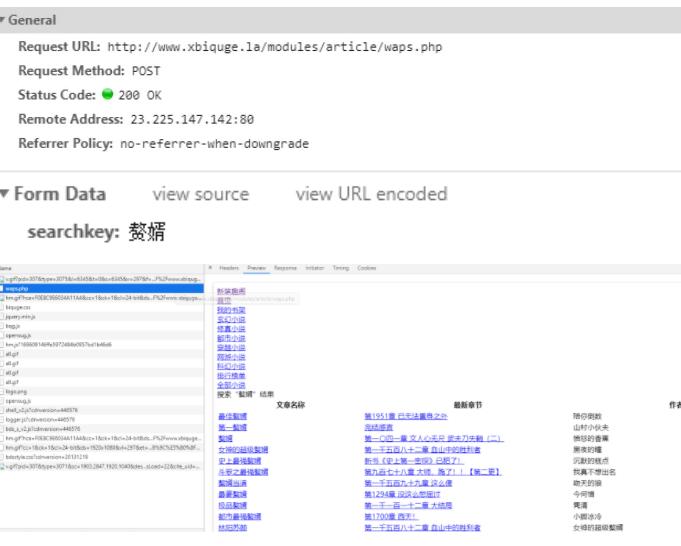
然后通过解析网站数据,获取第一个小说i的详情页url即可
静态网页的获取,难度是不大的。
def search(): search_url = 'http://www.xbiquge.la/modules/article/waps.php' data = { 'searchkey': name } response = requests.post(url=search_url, data=data, headers=headers) selector = get_parsing(response.text) novel_url = selector.css('.even a::attr(href)').extract_first()1、获取每本小说的章节名以及url地址
所有的章节名以及url地址,都包含在dd标签里面

2、获取url后,需要拼接
'/23/23019/11409705.html' # 这是网页获取到的url 'http://www.xbiquge.la/23/23019/11409705.html' # 这是真实的小说章节内容url地址3、小说名字,直接获取即可。
def download_one_book(index_url): response = get_response(index_url) response.encoding = response.apparent_encoding sel = get_parsing(response.text) book_name = sel.css('#info h1::text').get() # 提取了所有章节的下载地址 urls = sel.css('#list dd a::attr(href)').getall() # 不要最新的 12 章放在最前main for url in urls: chapter_url = 'http://www.xbiquge.la' + url print(chapter_url)保存下载每章小说内容
def download_one_chapter(chapter_url, book_name): response = get_response(chapter_url) response.encoding = response.apparent_encoding html = response.text selector = get_parsing(html) h1 = selector.css('.bookname h1::text').get() content = selector.css('#content::text').getall() lines = [] for c in content: lines.append(c.strip()) print(h1) text = '\n'.join(lines) file = open(book_name + '.txt', mode='a', encoding='utf-8') file.write(h1) file.write('\n') file.write(text) file.write('\n') file.close()小说软件界面
root = Tk() root.title('小说下载器') root.geometry('560x450+400+200') label = Label(root, text='请输入下载小说名字:', font=('华文行楷', 20)) label.grid() entry = Entry(root, font=('隶书', 20)) entry.grid(row=0, column=1) text = Listbox(root, font=('隶书', 16), width=50, heigh=15) text.grid(row=2, columnspan=2) button1 = Button(root, text='开始下载', font=('隶书', 15), command=search) button1.grid(row=3, column=0) button2 = Button(root, text='退出程序', font=('隶书', 15), command=root.quit) button2.grid(row=3, column=1) root.mainloop()显示下载内容
def novel_load(title): text.insert(END, '正在保存:{}'.format(title)) # 文本框滚动 text.see(END) # 更新 text.update()实现效果
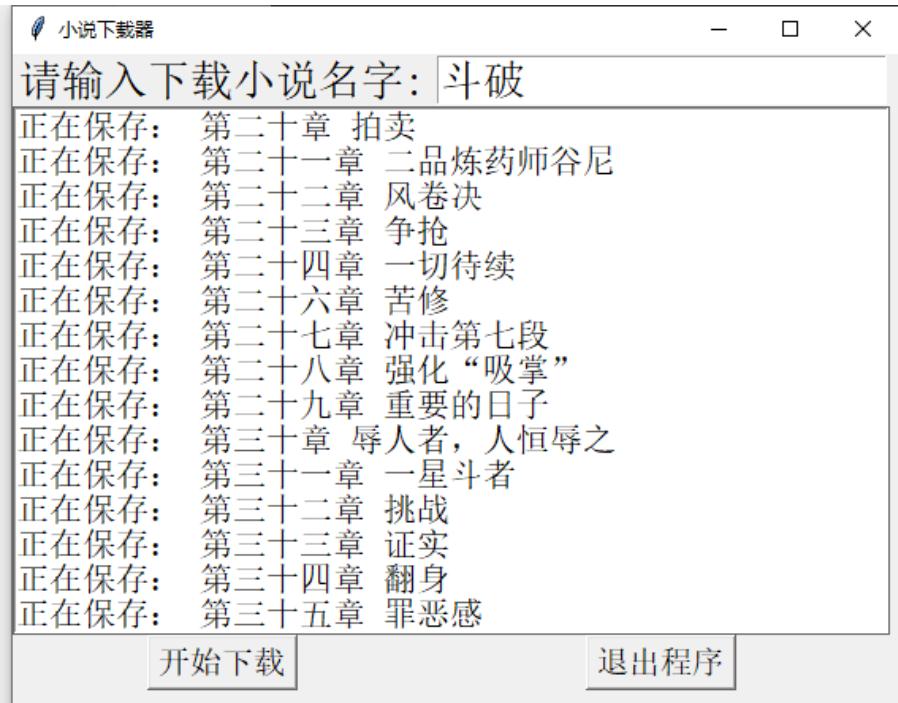
以上就是python 制作网站小说下载器的详细内容,更多关于python 小说下载器的资料请关注python博客其它相关文章!
-
<< 上一篇 下一篇 >>
标签:requests
python 制作网站小说下载器
看: 1972次 时间:2021-04-02 分类 : python web
- 相关文章
- 2021-07-20django学习之ajax post传参的2种格式实例
- 2021-07-20Python djanjo之csrf防跨站攻击实验过程
- 2021-07-20django admin实现动态多选框表单的示例代码
- 2021-07-20Flask登录注册项目的简单实现
- 2021-07-20Flask实现异步执行任务
- 2021-07-20如何使用flask将模型部署为服务
- 2021-07-20Django实现自定义路由转换器
- 2021-07-20python flask框架快速入门
- 2021-07-20Django 聚合函数的具体使用
- 2021-07-20django时区问题的解决
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!