1,使用到的第三方库
requests
BeautifulSoup 美味汤
worldcloud 词云
jieba 中文分词
matplotlib 绘图
2,代码实现部分import requests import wordcloud import jieba from bs4 import BeautifulSoup from matplotlib import pyplot as plt from pylab import mpl #设置字体 mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['axes.unicode_minus'] = False url = 'https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6' try: #获取数据 r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding soup = BeautifulSoup(r.text,'html.parser') data = soup.find_all('a') d_list = [] for item in data: d_list.append(item.text) words = d_list[4:-11:] #中文分词 result = list(jieba.cut(words[0])) for word in words[1::]: result.extend(jieba.cut(word)) redata = [] for it in result: if len(it) <= 1: continue else: redata.append(it) result_str = ' '.join(redata) #输出词云图 font = r'C:\Windows\Fonts\simhei.ttf' w = wordcloud.WordCloud(font_path=font,width=600,height=400) w.generate(result_str) w.to_file('微博热搜关键词词云.png') key = list(set(redata)) x,y = [],[] #筛选数据 for st in key: count = redata.count(st) if count <= 1: continue else: x.append(st) y.append(count) x.sort() y.sort() #绘制结果图 plt.plot(x,y) plt.show() except Exception as e: print(e)3,运行结果

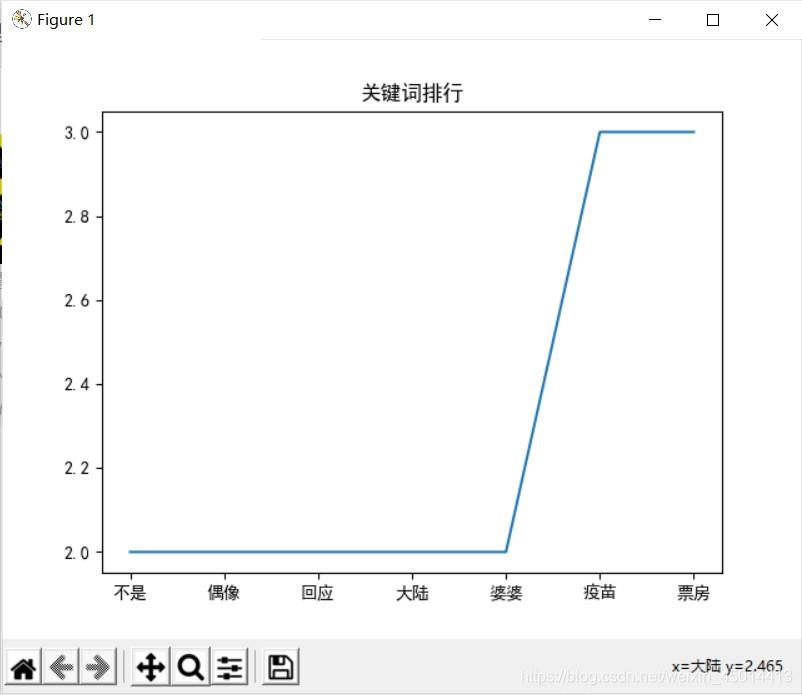
到此这篇关于Python爬虫分析微博热搜关键词的文章就介绍到这了,更多相关Python爬虫微博热搜内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
- << 上一篇 下一篇 >>
Python爬虫分析微博热搜关键词的实现代码
看: 1740次 时间:2021-03-27 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!