今日热榜:https://tophub.today/
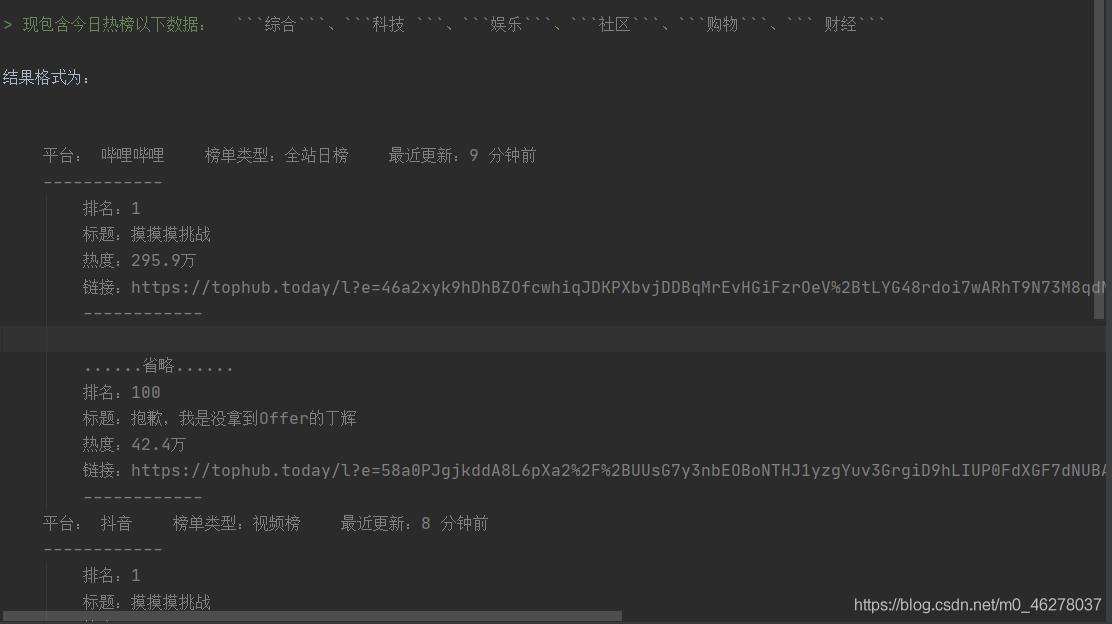
爬取数据及保存格式:
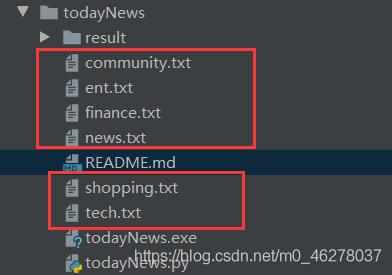
爬取后保存为.txt文件:
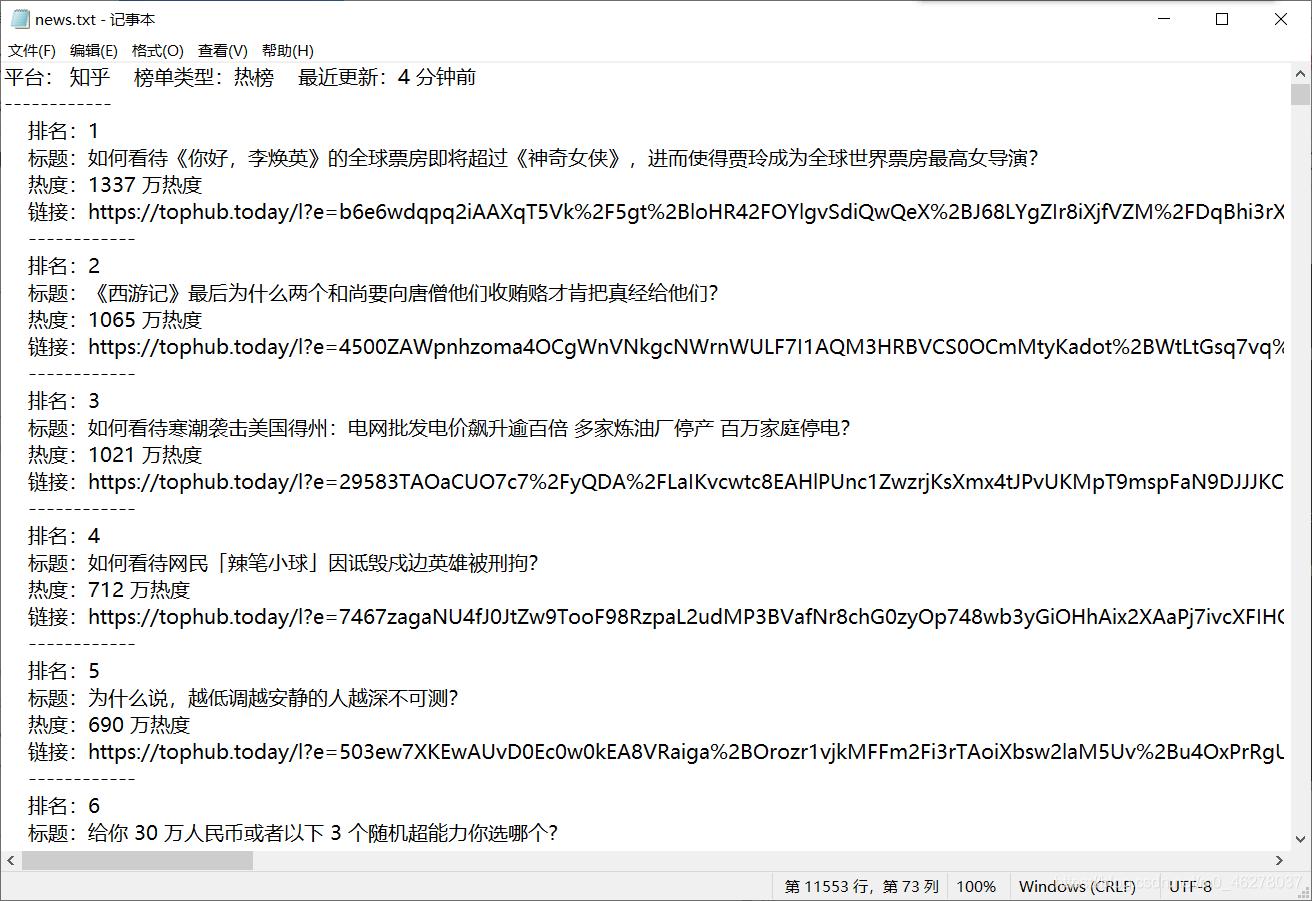
部分内容:
源码及注释:
import requests from bs4 import BeautifulSoup def download_page(url): headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"} try: r = requests.get(url,timeout = 30,headers=headers) return r.text except: return "please inspect your url or setup" def get_content(html,tag): output = """ 排名:{}\n 标题:{} \n 热度:{}\n 链接:{}\n ------------\n""" output2 = """平台:{} 榜单类型:{} 最近更新:{}\n------------\n""" num=[] title=[] hot=[] href=[] soup = BeautifulSoup(html, 'html.parser') con = soup.find('div',attrs={'class':'bc-cc'}) con_list = con.find_all('div', class_="cc-cd") for i in con_list: author = i.find('div', class_='cc-cd-lb').get_text() # 获取平台名字 time = i.find('div', class_='i-h').get_text() # 获取最近更新 link = i.find('div', class_='cc-cd-cb-l').find_all('a') # 获取所有链接 gender = i.find('span', class_='cc-cd-sb-st').get_text() # 获取类型 save_txt(tag,output2.format(author, gender,time)) for k in link: href.append(k['href']) num.append(k.find('span', class_='s').get_text()) title.append(str(k.find('span', class_='t').get_text())) hot.append(str(k.find('span', class_='e').get_text())) for h in range(len(num)): save_txt(tag,output.format(num[h], title[h], hot[h], href[h])) def save_txt(tag,*args): for i in args: with open(tag+'.txt', 'a', encoding='utf-8') as f: f.write(i) def main(): # 综合 科技 娱乐 社区 购物 财经 page=['news','tech','ent','community','shopping','finance'] for tag in page: url = 'https://tophub.today/c/{}'.format(tag) html = download_page(url) get_content(html,tag) if __name__ == '__main__': main()到此这篇关于python爬虫今日热榜数据到txt文件的源码的文章就介绍到这了,更多相关python爬虫今日热榜数据内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
标签:requests
python爬虫今日热榜数据到txt文件的源码
看: 1643次 时间:2021-03-27 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!