博主作为爬虫初学者,本次使用了requests和beautifulsoup库进行数据的爬取
爬取网站:http://datachart.500.com/dlt/history/history.shtml —500彩票网
(分析后发现网站源代码并非是通过页面跳转来查找不同的数据,故可通过F12查找network栏找到真正储存所有历史开奖结果的网页)如图:
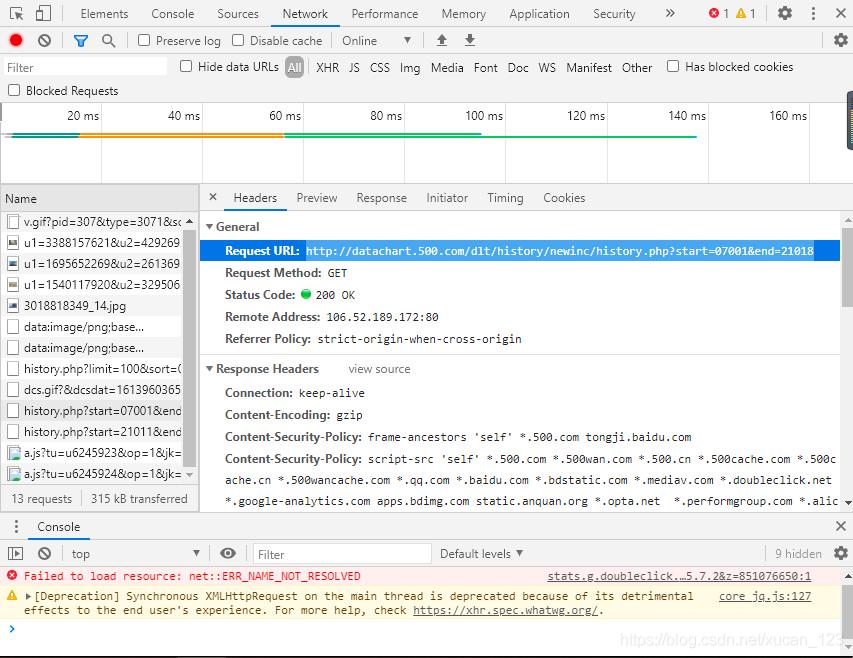
爬虫部分:
from bs4 import BeautifulSoup #引用BeautifulSoup库 import requests #引用requests import os #os import pandas as pd import csv import codecs lst=[] url='http://datachart.500.com/dlt/history/newinc/history.php?start=07001&end=21018' r = requests.get(url) r.encoding='utf-8' text=r.text soup = BeautifulSoup(text, "html.parser") tbody=soup.find('tbody',id="tdata") tr=tbody.find_all('tr') td=tr[0].find_all('td') for page in range(0,14016): td=tr- << 上一篇 下一篇 >>
python爬取分析超级大乐透历史开奖数据第1/2页
看: 2665次 时间:2021-03-21 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!