使用Python加载最新的Excel读取类库xlwings可以说是Excel数据处理的利器,但使用起来还是有一些注意事项,否则高大上的Python会跑的比老旧的VBA还要慢。
这里我们对比一下,用几种不同的方法,从一个Excel表格中读取一万行数据,然后计算结果,看看他们的耗时。
1. 处理要求:
一个Excel表格中包含了3万条记录,其中B,C两个列记录了某些计算值,读取前一万行记录,将这两个列的差值进行计算,然后汇总得出差的和。
文件是这个样子:Book300s.xlsx 。

2. 处理方式有以下3种,我们对比一下耗时的大小。
处理方式 代码名称 1. 使用Python的xlwings类库,读取Excel文件,然后采用Excel的Sheet和Range的引用方式读取并计算 XLS_READ_SHEET.py 2. 直接使用Excel自带的VBA语言进行计算 VBA 3. 使用Python的xlwings类库,读取Excel文件,然后采用Python的自带数据类型List列表进行数据存储和计算
XLS_READ_LIST.py 3. 首先测试第一种,XLS_READ_SHEET.py
使用Python的xlwings类库,读取Excel文件,然后引用Excel的Sheet和Range的方式来读取并计算
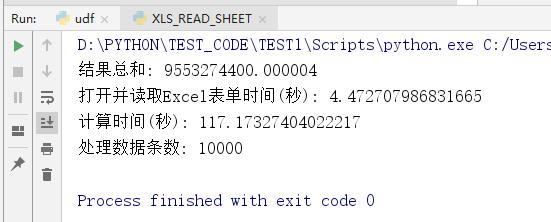
#coding=utf-8 import xlwings as xw import pandas as pd import time start_row = 2 # 处理Excel文件开始行 end_row = 10002 # 处理Excel结束行 #记录打开表单开始时间 start_open_time = time.time() #指定不显示地打开Excel,读取Excel文件 app = xw.App(visible=False, add_book=False) wb = app.books.open('D:/PYTHON/TEST_CODE/Book300s.xlsx') # 打开Excel文件 sheet = wb.sheets[0] # 选择第0个表单 #记录打开Excel表单结束时间 end_open_time = time.time() #记录开始循环计算时间 start_run = time.time() row_content = [] #读取Excel表单前10000行的数据,Python的in range是左闭右开的,到10002结束,但区间只包含2到10001这一万条 for row in range(start_row, end_row): row_str = str(row) #循环中引用Excel的sheet和range的对象,读取B列和C列的每一行的值,对比计算 start_value = sheet.range('B' + row_str).value end_value = sheet.range('C' + row_str).value if start_value <= end_value: values = end_value - start_value #同时测试List数组添加记录 row_content.append(values) #计算和 total_values = sum(row_content) #记录结束循环计算时间 end_run = time.time() sheet.range('E2').value = str(total_values) sheet.range('E3').value = '使用Sheet计算时间(秒):' + str(end_run - start_run) #保存并关闭Excel文件 wb.save() wb.close() print ('结果总和:', total_values) print ('打开并读取Excel表单时间(秒):', end_open_time - start_open_time) print ('计算时间(秒):', end_run - start_run) print ('处理数据条数:' , len(row_content))用Python直接访问Sheet和Range取值的计算结果如下:
读取Excel文件用时 4.47秒
处理Excel 10000 行数据花费了117秒的时间。
4. 然后我们用Excel自带的VBA语言来处理一下相同的计算。也是直接引用Sheet,Range等Excel对象,但VBA的数组功能实在是不好用,就不测试添加数组了。
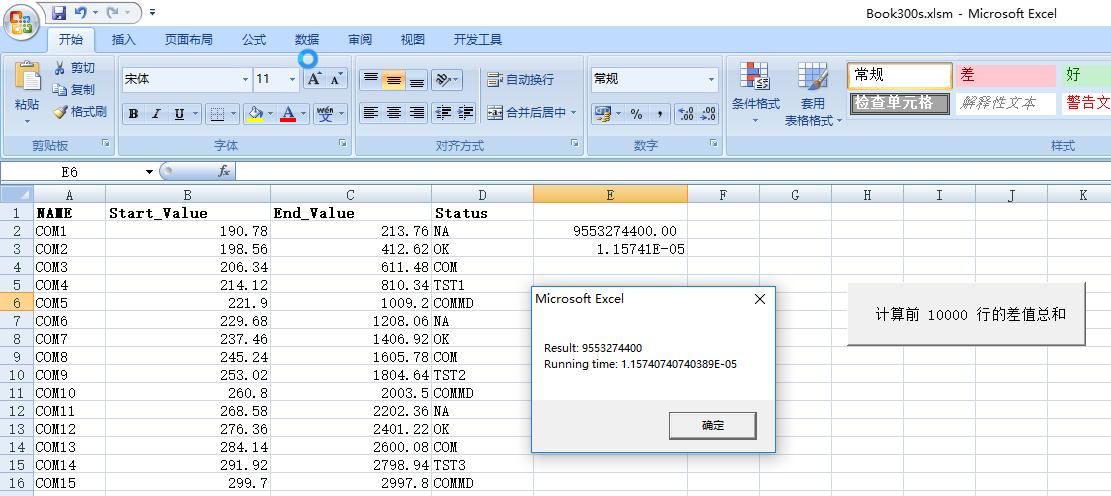
Option Explicit Sub VBA_CAL_Click() Dim i_count As Long Dim offset_value, total_offset_value As Double Dim st, et As Date st = Time() i_count = Sheets("Sheet1").Cells(Rows.Count, 1).End(xlUp).Row i_count = 10001 For i_count = 2 To i_count If Range("C" & i_count).Value > Range("B" & i_count).Value Then offset_value = Range("C" & i_count).Value - Range("B" & i_count).Value total_offset_value = total_offset_value + offset_value End If Next i_count et = Time() Range("E2").Value = total_offset_value Range("E3").Value = et - st MsgBox "Result: " & total_offset_value & Chr(10) & "Running time: " & et - st End SubVBA处理计算结果如下:
保存了3万条数据的Excel文件是通过手工打开的,在电脑上大概花费了8.2秒的时间
处理Excel 前10000行数据花费了1.16秒的时间。
5.使用Python的xlwings类库,读取Excel文件,然后采用Python的自带数据类型List进行数据存储和计算,计算完成后再将结果写到Excel表格中
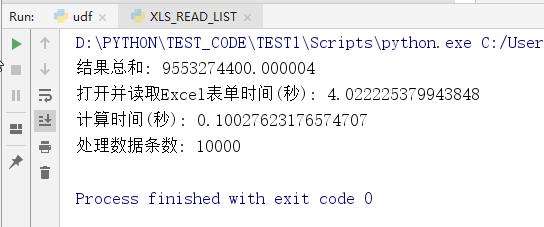
#coding=utf-8 import xlwings as xw import pandas as pd import time #记录打开表单开始时间 start_open_time = time.time() #指定不显示地打开Excel,读取Excel文件 app = xw.App(visible=False, add_book=False) wb = app.books.open('D:/PYTHON/TEST_CODE/Book300s.xlsx') # 打开Excel文件 sheet = wb.sheets[0] # 选择第0个表单 #记录打开Excel表单结束时间 end_open_time = time.time() #记录开始循环计算时间 start_run = time.time() row_content = [] #读取Excel表单前10000行的数据,并计算B列和C列的差值之和 list_value = sheet.range('A2:D10001').value for i in range(len(list_value)): #使用Python的类库直接访问Excel的表单是很缓慢的,不要在Python的循环中引用sheet等Excel表单的单元格, #而是要用List一次性读取Excel里的数据,在List内存中计算好了,然后返回结果 start_value = list_value[i][1] end_value = list_value[i][2] if start_value <= end_value: values = end_value- start_value #同时测试List数组添加记录 row_content.append(values) #计算和 total_values = sum(row_content) #记录结束循环计算时间 end_run = time.time() sheet.range('E2').value = str(total_values) sheet.range('E3').value = '使用List 计算时间(秒):' + str(end_run - start_run) #保存并关闭Excel文件 wb.save() wb.close() print ('结果总和:', total_values) print ('打开并读取Excel表单时间(秒):', end_open_time - start_open_time) print ('计算时间(秒):', end_run - start_run) print ('处理数据条数:' , len(row_content))用Python的LIST在内存中计算结果如下:
读取Excel文件用时 4.02秒
处理Excel 10000 行数据花费了 0.10 秒的时间。
6 结论:
Python操作Excel的类库有以往有 xlrd、xlwt、openpyxl、pyxll等,这些类库有的只支持读取,有的只支持写入,并且有的不支持Excel的xlsx格式等。
所以我们采用了最新的开源免费的xlwings类库,xlwings能够很方便的读写Excel文件中的数据,并支持Excel的单元格格式修改,也可以与pandas等类库集成使用。
VBA是微软Excel的原生二次开发语言,是办公和数据统计的利器,在金融,统计,管理,计算中应用非常广泛,但是VBA计算能力较差,支持的数据结构少,编辑器粗糙。
虽然VBA有很多不足,但是VBA的宿主Office Excel却是天才程序员基于C++开发的作品,稳定,高效,易用 。
有微软加持,VBA虽然数据结构少,运行速度慢,但访问自己Excel的Sheet,Range,Cell等对象却速度飞快,这就是一体化产品的优势。
VBA读取Excel的Range,Cell等操作是通过底层的API直接读取数据的,而不是通过微软统一的外部开发接口。所以Python的各种开源和商用的Excel处理类库如果和VBA来比较读写Excel格子里面的数据,都是处于劣势的(至少是不占优势的),例子2的VBA 花费了1.16秒就能处理完一万条数据。
Python基于开源,语法优美而健壮,支持面向对象开发,最重要的是,Python有丰富而功能强大的类库,支持多种工作场景的开发。
我们应该认识到,Excel对于Python而言,只是数据源文件的一种,当处理大量数据时,Python处理Excel就要把Excel当数据源来处理,一次性地读取数据到Python的数据结构中,而不是大量调用Excel里的对象,不要说频繁地写入Excel,就是频繁地读取Excel里面的某些单元格也是效率较低的。例子1的Python频繁读取Sheet,Range数据,结果花费了117秒才处理完一万条数据。
Python的计算效率和数据结构的操作方便性可比VBA强上太多,和VBA联合起来使用,各取所长是个好主意。
当Excel数据一次性读入Python的内存List数据结构中,然后基于自身的List数据结构在内存中计算,例子3的Python只用了 0.1秒就完成了一万条数据的计算并将结果写回Excel。
总结:
处理方式-计算Excel里的一万条记录的差值的总和 效率 1. 使用Python的xlwings类库,采用Excel的Sheet和Range的引用方式,按行读取Excel文件的记录并计算 差,计算用时 117秒 2. 直接使用Excel自带的VBA语言进行计算,也是采用Excel的Sheet和Range的引用方式,按行读取Excel文件的记录并计算 很高 ,计算用时 1.16秒 3. 使用Python的xlwings类库,一次性读取Excel文件中的数据到Python的List数据结构中,然后在Python的List列表中进行数据存储和计算
最高,计算用时 0.1秒 到此这篇关于浅谈Python xlwings 读取Excel文件的正确姿势的文章就介绍到这了,更多相关Python xlwings 读取Excel内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
标签:pandas
浅谈Python xlwings 读取Excel文件的正确姿势
看: 1663次 时间:2021-03-18 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!