一、我们对XML的读取进行一波演示
import xml.dom.minidom #负责解析xml文件的包 from xml.dom.minidom import parse #使用minidom打开xml文件 DOMTree = xml.dom.minidom.parse("D30_1_XmlNameSpace.xml") print(DOMTree)#将该XML文件定义为一个对象 #得到文档对象 doc = DOMTree.documentElement#打印出了带有根目录的名字的对象 print(doc) #显示子元素 for ele in doc.childNodes: if ele.nodeName == "student:Name": print("=======Node:{0}=======".format(ele.nodeName)) print(doc.childNodes) if ele.nodeName == "Age": print(ele.getAttribute("jio"))#获取某一节点的属性值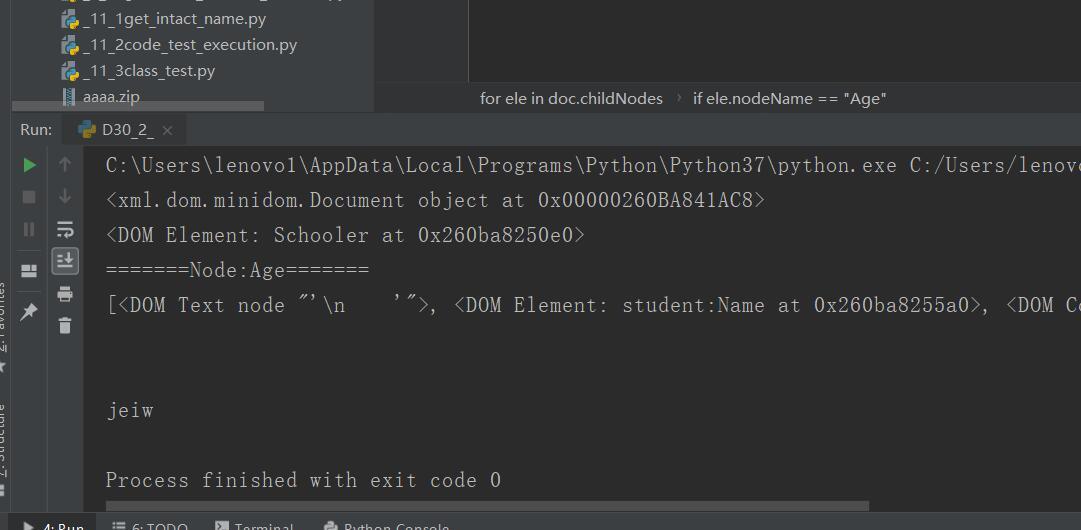
二、同时我们还可以使用xml.DOM.etree这种方式来进行解析
我们提供方法:
(1)以树形结构来表示xml;
(2)root.getiterator:得到相应的可迭代的node集合
(3)root.iter
(4)find(node_name):查找指定node_name的节点,返回一个node
(5)root.findall(node_name):返回多个node_name的节点
(6)node.tag:node对应的tagename
(7)node.text:node的文本值
(8)node.attrib:是node的属性的字典类型的内容
mport xml.etree.ElementTree root = xml.etree.ElementTree.parse("D30_1_XmlNameSpace.xml") nodes = root.getiterator() for node in nodes: print("{0}---{1}".format(node.tag,node.text)) print("===========================================") ele_room_name = root.find("Location") print(type(ele_room_name)) print("{0}----{1}".format(ele_room_name.tag,ele_room_name.text)) print("===========================================") ele_room_name2 = root.findall("{http://my_room}Name")#这里如果使用“room:Name”是解析不出来的 print(ele_room_name2) for ele in ele_room_name2: print("{0}----{1}".format(ele.tag,ele.text)) ele_room_name2 = root.findall("room:Name") print(ele_room_name2) for ele in ele_room_name2: print("{0}----{1}".format(ele.tag,ele.text))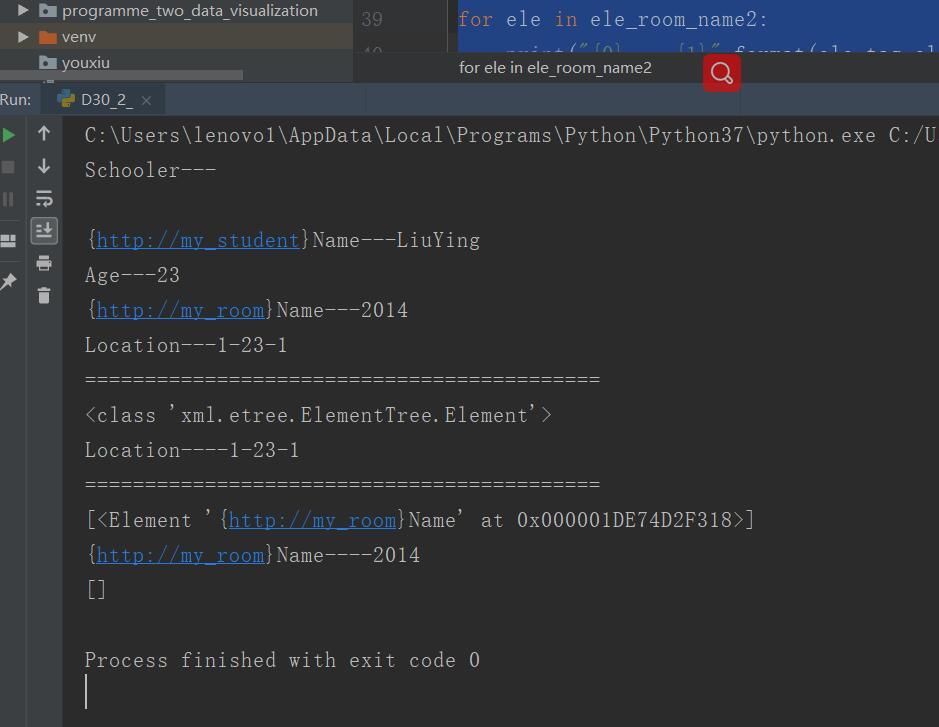
三、源码
D30_2_XmlAnalysis.py
https://github.com/ruigege66/Python_learning/blob/master/D30_2_XmlAnalysis.py
以上就是python 如何对xml解析的详细内容,更多关于python 对xml解析的资料请关注python博客其它相关文章!
-
<< 上一篇 下一篇 >>
python 对xml解析的示例
看: 1249次 时间:2021-03-16 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!