1.pyspider介绍
一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
- 用Python编写脚本
- 功能强大的WebUI,包含脚本编辑器,任务监视器,项目管理器和结果查看器
- MySQL,MongoDB,Redis,SQLite,Elasticsearch ; PostgreSQL与SQLAlchemy作为数据库后端
- RabbitMQ,Beanstalk,Redis和Kombu作为消息队列
- 任务优先级,重试,定期,按年龄重新抓取等...
- 分布式架构,抓取JavaScript页面,Python 2和3等...
2.pyspider文档
1>中文文档:http://www.pyspider.cn/
2>英文文档:http://docs.pyspider.org/
3.pyspider安装
打开cmd命令行工具,执行命令
pip install pyspider
出现下图则安装成功

4.pyspider启动服务,进入WebUI界面
安装pyspider后,打开cmd命令工具,执行命令来启动服务器
pyspider
出现下图则启动服务成功,默认地址端口为127.0.0.1:5000

输入地址127.0.0.1:5000,打开WebUI界面
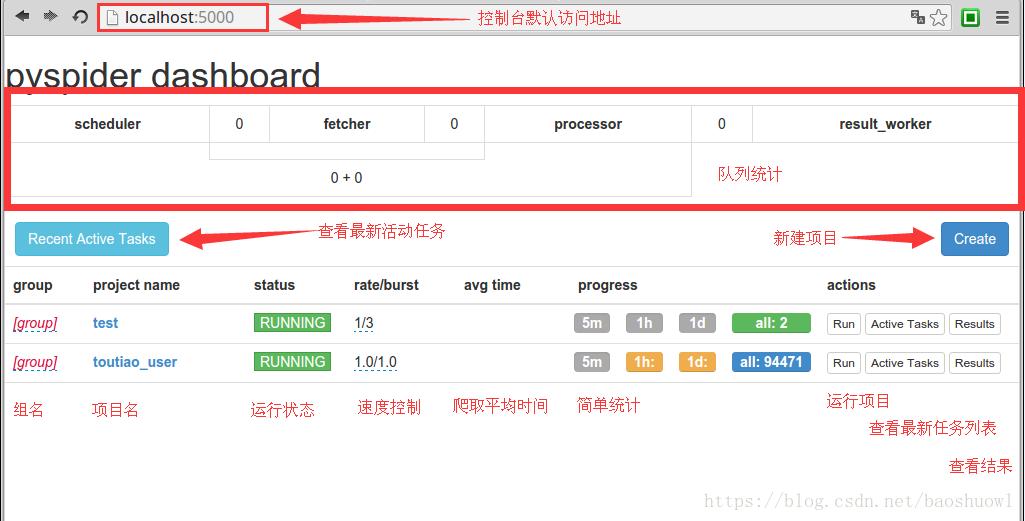
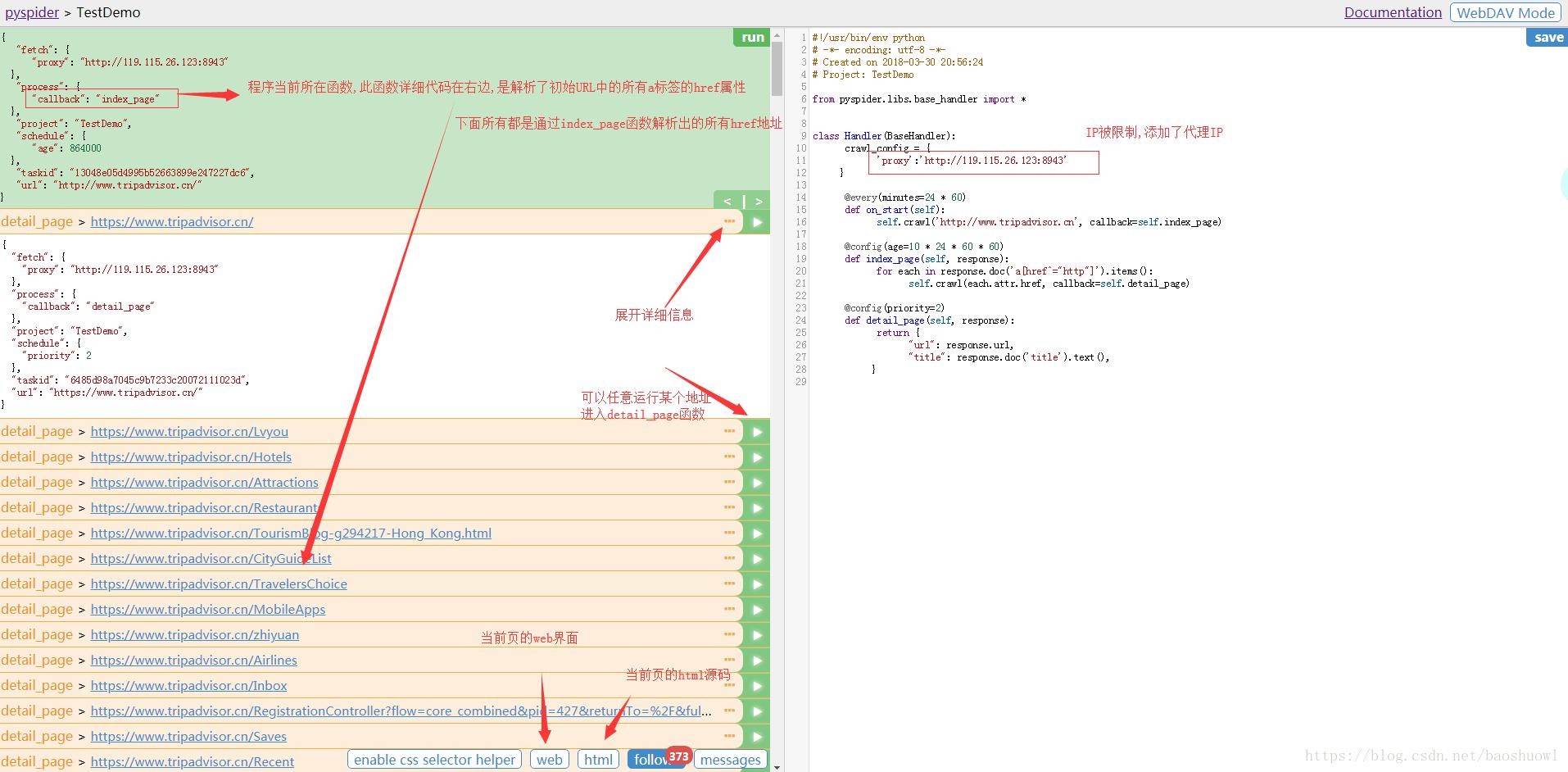
队列统计是为了方便查看爬虫状态,优化爬虫爬取速度新增的状态统计.每个组件之间的数字就是对应不同队列的排队数量.通常来是0或是个位数.如果达到了几十甚至一百说明下游组件出现了瓶颈或错误,需要分析处理.
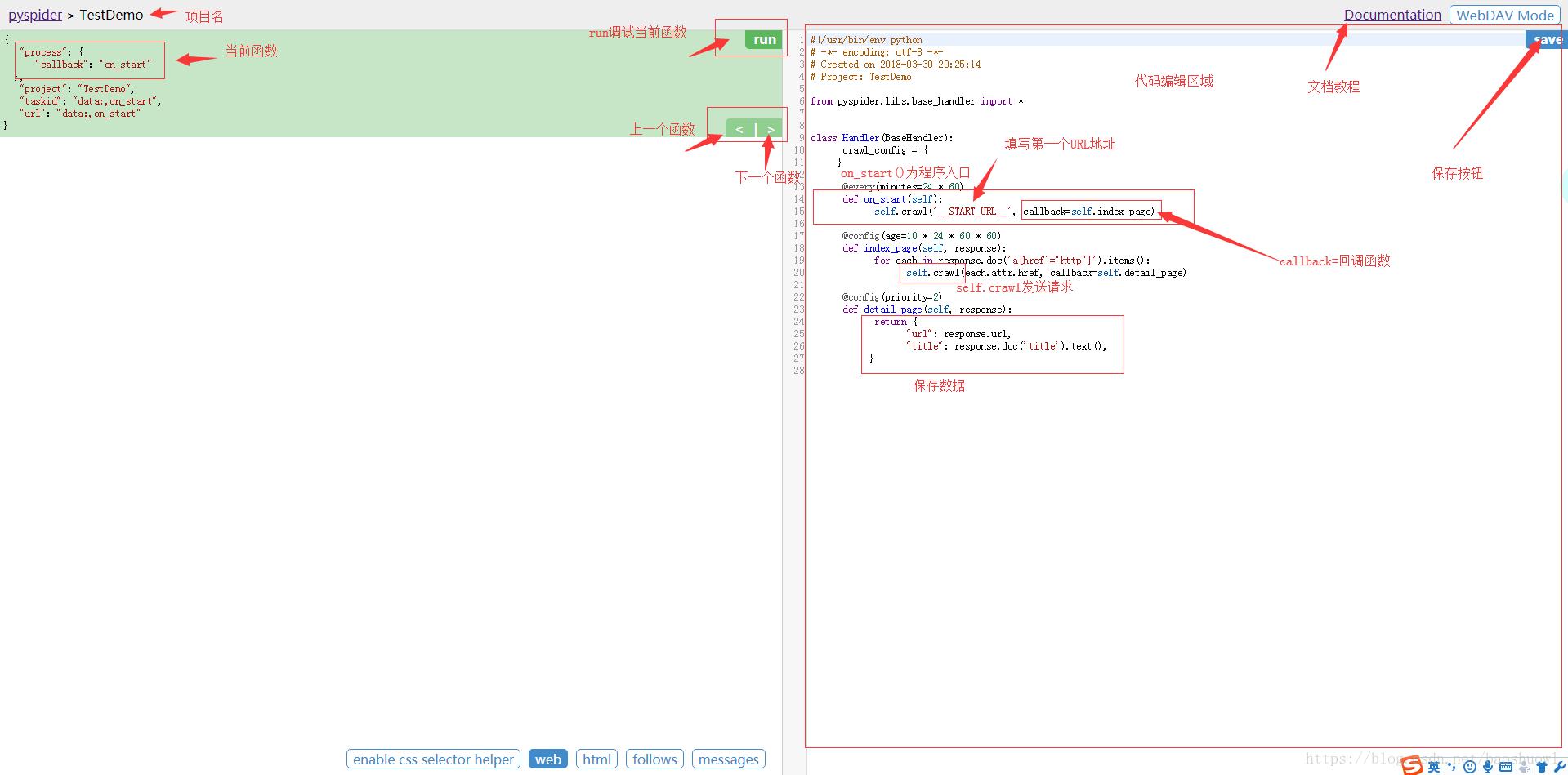
新建项目:pyspider与scrapy最大的区别就在这,pyspider新建项目调试项目完全在web下进行,而scrapy是在命令行下开发并运行测试.
组名:项目新建后一般来说是不能修改项目名的,如果需要特殊标记可修改组名.直接在组名上点鼠标左键进行修改.注意:组名改为delete后如果状态为stop状态,24小时后项目会被系统删除.
运行状态:这一栏显示的是当前项目的运行状态.每个项目的运行状态都是单独设置的.直接在每个项目的运行状态上点鼠标左键进行修改.运行分为五个状态:TODO,STOP,CHECKING,DEBUG,RUNNING.各状态说明:TODO是新建项目后的默认状态,不会运行项目.STOP状态是停止状态,也不会运行.CHECHING是修改项目代码后自动变的状态.DEBUG是调试模式,遇到错误信息会停止继续运行,RUNNING是运行状态,遇到错误会自动尝试,如果还是错误会跳过错误的任务继续运行.
速度控制:很多朋友安装好用说爬的慢,多数情况是速度被限制了.这个功能就是速度设置项.rate是每秒爬取页面数,burst是并发数.如1/3是三个并发,每秒爬取一个页面.
简单统计:这个功能只是简单的做的运行状态统计,5m是五分钟内任务执行情况,1h是一小时内运行任务统计,1d是一天内运行统计,all是所有的任务统计.
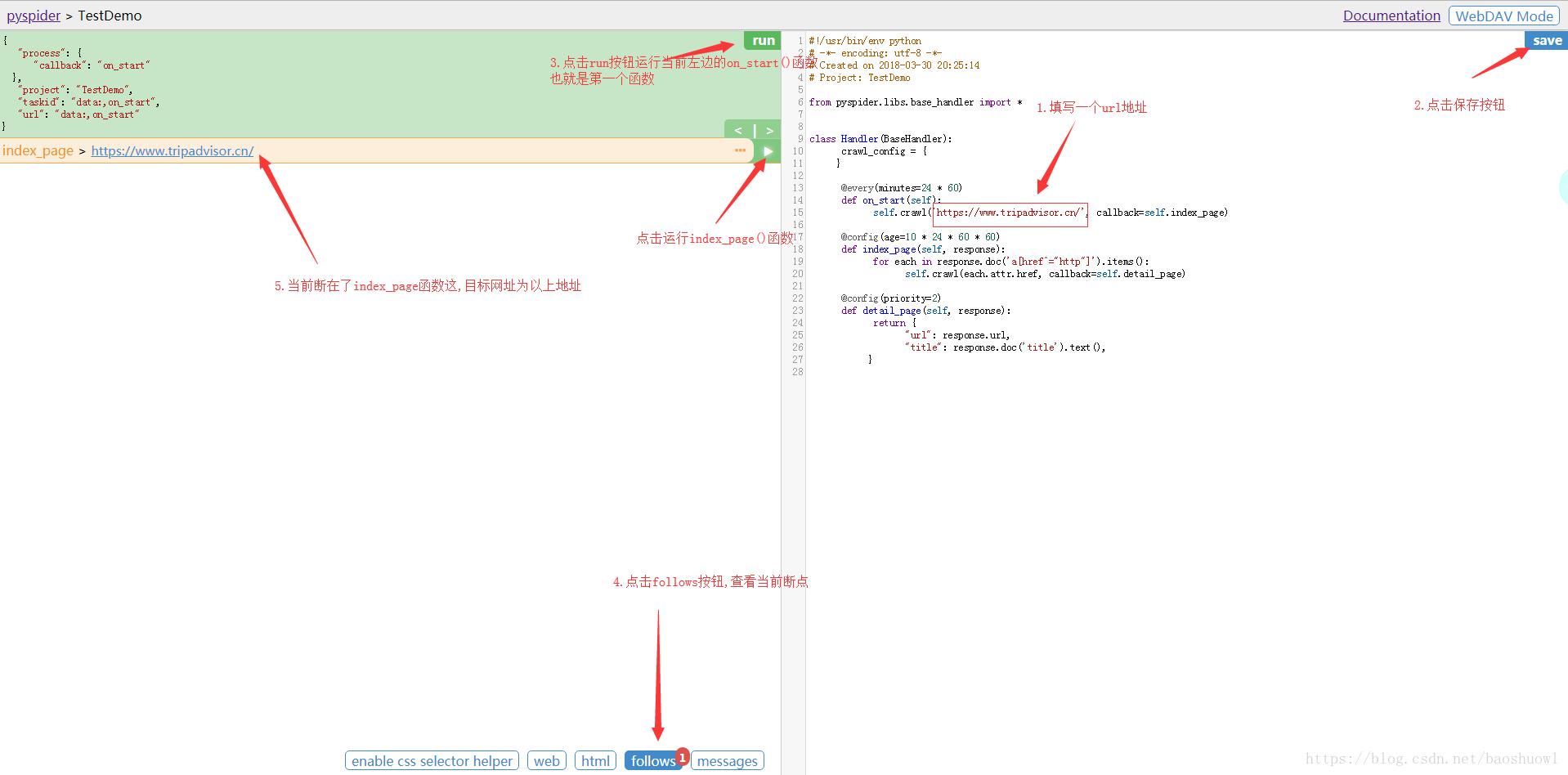
运行:run按钮是项目初次运行需要点的按钮,这个功能会运行项目的on_start方法来生成入口任务.
任务列表:显示最新任务列表,方便查看状态,查看错误等
结果查看:查看项目爬取的结果.
5.创建pyspider项目
点击上图中的新建项目按钮
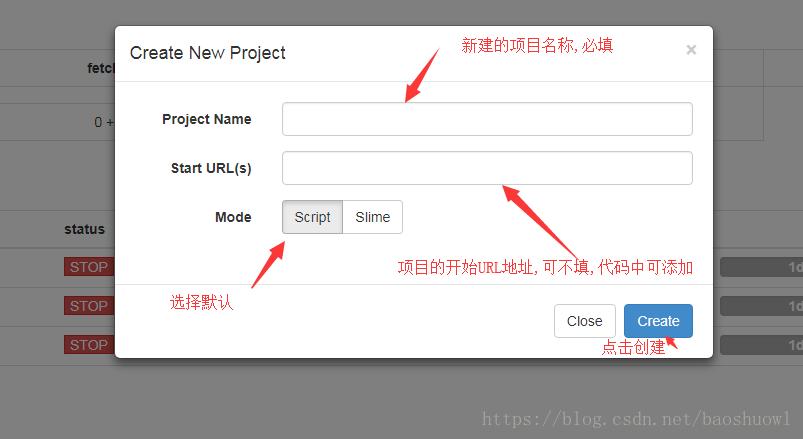
6.创建后的pyspider项目
到此这篇关于Python中Pyspider爬虫框架的基本使用详解的文章就介绍到这了,更多相关Pyspider爬虫框架使用内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
标签:scrapy
Python中Pyspider爬虫框架的基本使用详解
看: 2021次 时间:2021-03-09 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!