首先:文章用到的解析库介绍
BeautifulSoup:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。
你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
爬取小说原因背景:
以前很喜欢看起点网上面的小说,但是很多都要钱,穷学生没多少钱,就发现了笔趣网。
笔趣看是一个小说网站,这里有很多起点中文网的免费小说,而且这个网站只能在线浏览,不支持小说打包下载。
所以本次爬取呢,就是从该网站爬取并保存一个名为《一念永恒》的小说。
另外本次爬取只是做例子演示,请支持正版资源!!!!!!!!!!!
那么简单的爬取开始:
①打开url链接,按F12或者右键- 检查 进入开发者工具
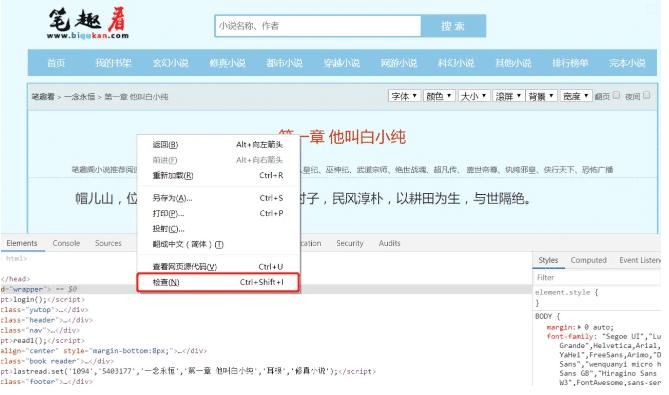
② 在开发者工具中,捕获我们要找到的请求条目信息
选择主文章的一部分内容,选择复制粘贴那一部分,
然后再打开开发者工具栏:
“network—选择放大镜图标sreach—然后再搜索栏粘贴我们要搜索的内容”
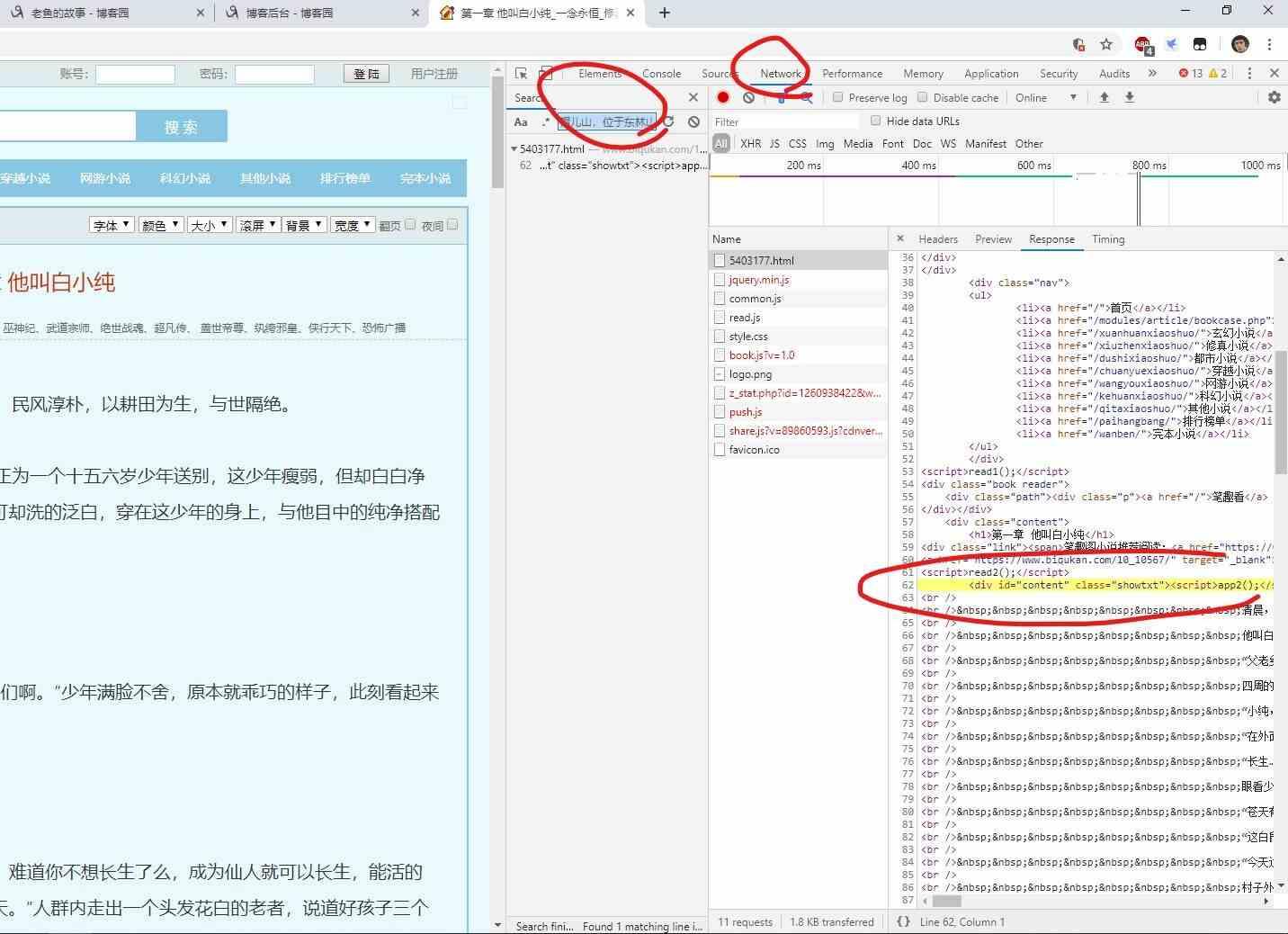
然后会在下方得到条目信息,点击,页面会跳转到加载正文的请求响应条目中。
我们可以看到:
正文部分是处于 id 为 content 和 class 为 showtxt 的 div 中。
③ 构造url请求
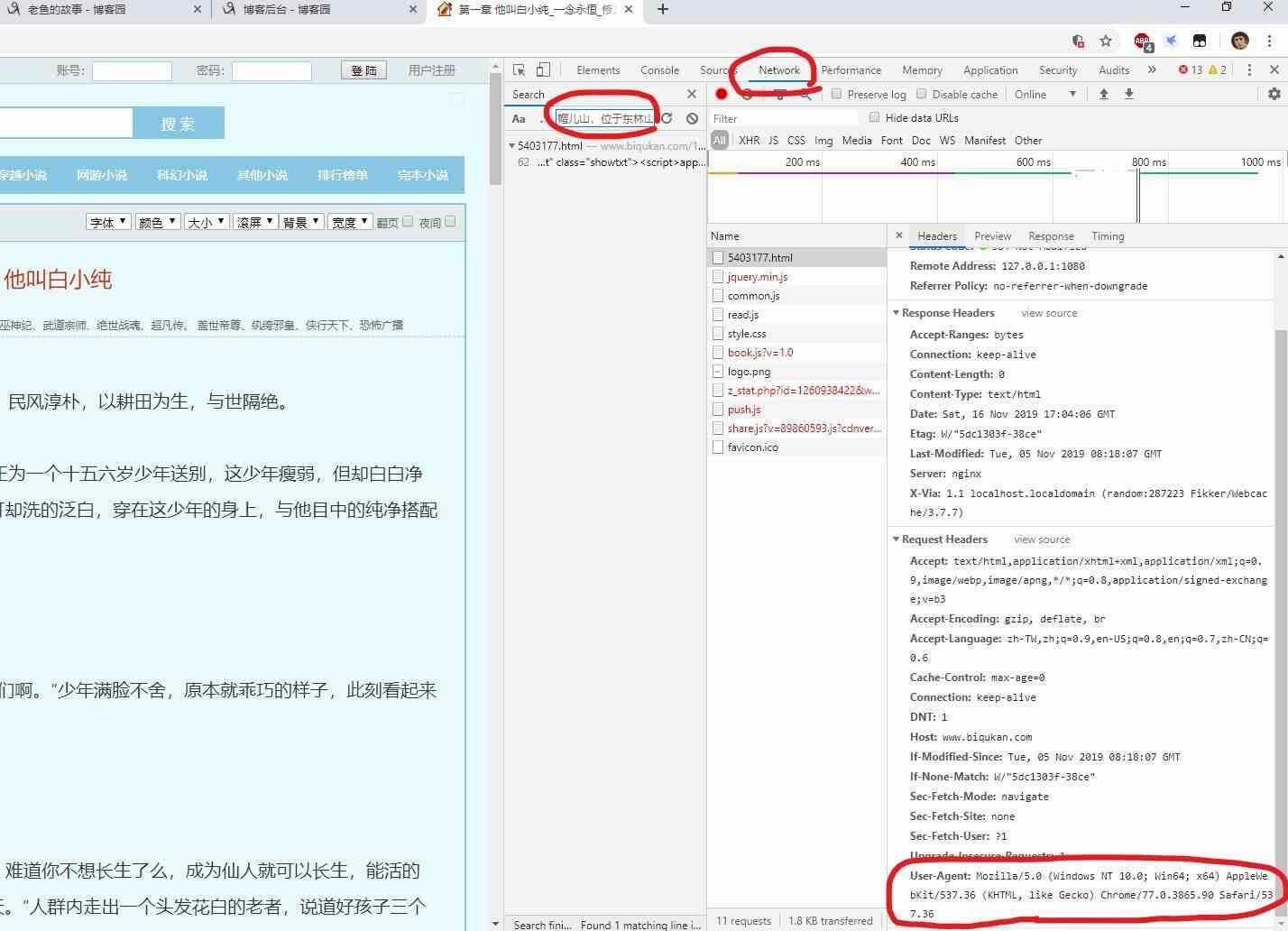
上面的信息是不够的,因为现在的网站都有了反爬能力,我们所需要是模拟一条正常从浏览器中发出的url请求链接。
这里我们会用到: User-Agent(浏览器标识)
还是开发者工具,点击Headers,就可以看到Request-Response条目明细。
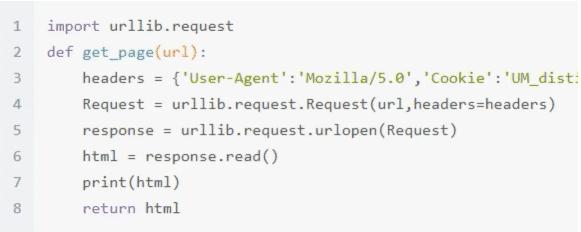
④ 发出请求:
有了字段的详细内容,我们就可以编写出请求网页的代码
⑤ 获得相应内容,然后运行,得到内容如下:
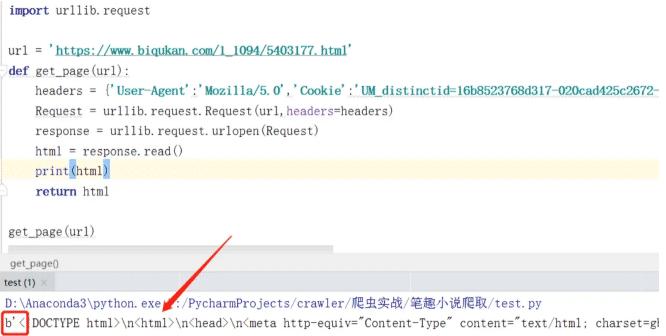
解析响应数据
下面,我们使用BeautifulSoup进行解析 运行….代码结果如图:
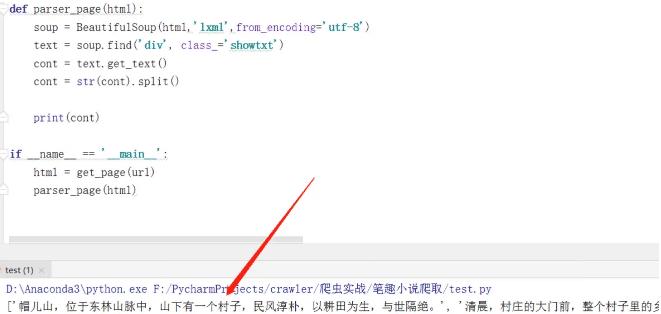
到这里,小说就爬取完成了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:scrapy
python爬虫爬取笔趣网小说网站过程图解
看: 1962次 时间:2021-02-23 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!