本文实例讲述了Python大数据之使用lxml库解析html网页文件。分享给大家供大家参考,具体如下:
lxml是Python的一个html/xml解析并建立dom的库,lxml的特点是功能强大,性能也不错,xml包含了ElementTree ,html5lib ,beautfulsoup 等库。
使用lxml前注意事项:先确保html经过了utf-8解码,即
code =html.decode('utf-8', 'ignore'),否则会出现解析出错情况。因为中文被编码成utf-8之后变成 '/u2541' 之类的形式,lxml一遇到 "/"就会认为其标签结束。具体用法:元素节点操作
1、 解析HTMl建立DOM
from lxml import etree dom = etree.HTML(html)2、 查看dom中子元素的个数
len(dom)3、 查看某节点的内容:
etree.tostring(dom[0])4、 获取节点的标签名称:
dom[0].tag5、 获取某节点的父节点:
dom[0].getparent()6、 获取某节点的属性节点的内容:
dom[0].get("属性名称")对xpath路径的支持:
XPath即为XML路径语言,是用一种类似目录树的方法来描述在XML文档中的路径。比如用"/"来作为上下层级间的分隔。第一个"/"表示文档的根节点(注意,不是指文档最外层的tag节点,而是指文档本身)。比如对于一个HTML文件来说,最外层的节点应该是"/html"。
xpath选取元素的方式:
1、 绝对路径,如
page.xpath("/html/body/p"),它会找到body这个节点下所有的p标签2、 相对路径,
page.xpath("//p"),它会找到整个html代码里的所有p标签。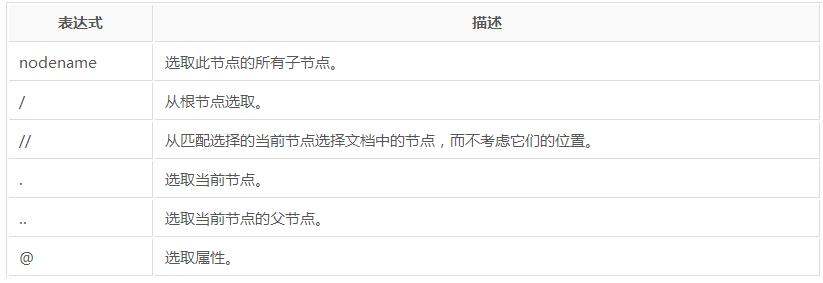
xpath筛选方式:
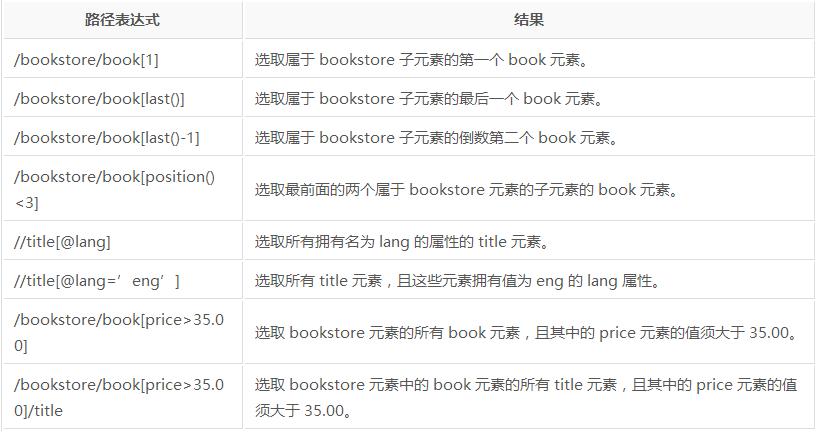
1、 选取元素时一个列表,可通过索引查找[n]
2、 通过属性值筛选元素
p =page.xpath("//p[@style='font-size:200%']")3、 如果没有属性可以通过text()(获取元素中文本)、position()(获取元素位置)、last()等进行筛选
获取属性值
dom.xpath(.//a/@href)获取文本
dom.xpath(".//a/text()")示例代码:
#!/usr/bin/python # -*- coding:utf-8 -*- from scrapy.spiders import Spider from lxml import etree from jredu.items import JreduItem class JreduSpider(Spider): name = 'tt' #爬虫的名字,必须的,唯一的 allowed_domains = ['sohu.com'] start_urls = [ 'http://www.sohu.com' ] def parse(self, response): content = response.body.decode('utf-8') dom = etree.HTML(content) for ul in dom.xpath("//div[@class='focus-news-box']/div[@class='list16']/ul"): lis = ul.xpath("./li") for li in lis: item = JreduItem() #定义对象 if ul.index(li) == 0: strong = li.xpath("./a/strong/text()") li.xpath("./a/@href") item['title']= strong[0] item['href'] = li.xpath("./a/@href")[0] else: la = li.xpath("./a[last()]/text()") item['title'] = la[0] item['href'] = li.xpath("./a[last()]/href")[0] yield item希望本文所述对大家Python程序设计有所帮助。
-
<< 上一篇 下一篇 >>
标签:scrapy
Python大数据之使用lxml库解析html网页文件示例
看: 2080次 时间:2021-02-19 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!