前言
大家好
最近python爬虫有点火啊,啥python爬取马保国视频……我也来凑个热闹,今天我们来试着做个翻译软件……不是不是,说错了,今天我们来试着提交翻译内容并爬取翻译结果
主要内容
材料
1.Python 3.8.4
2.电脑一台(应该不至于有”穷苦人家“连一台电脑都没有吧)
3.Google浏览器(其他的也行,但我是用的Google)
写程序前准备
打开Google浏览器,找的有道词典的翻译网页(http://fanyi.youdao.com/)
打开后摁F12打开开发者模式,找Network选项卡,点击Network选项卡,然后刷新一下网页
然后翻译一段文字,随便啥都行(我用的程序员的传统:hello world),然后点击翻译
在选项卡中找到以translate开头的post文件
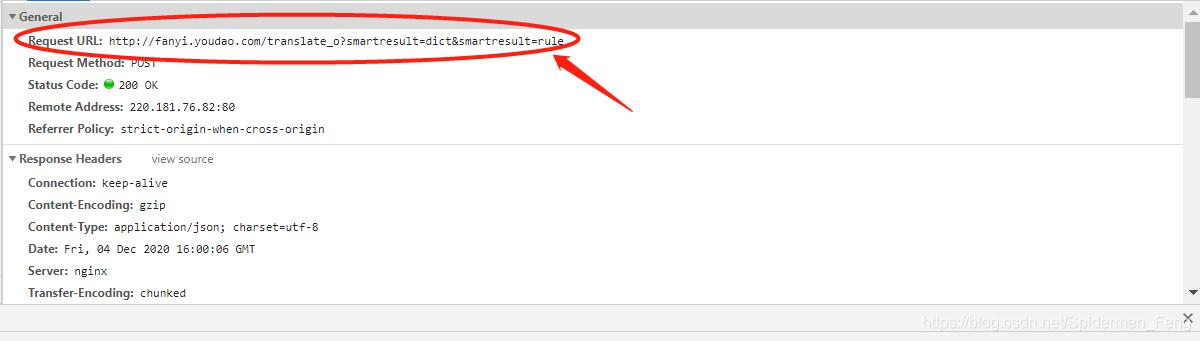
箭头的地方才是真正的提交地址
记住他,写代码时要用
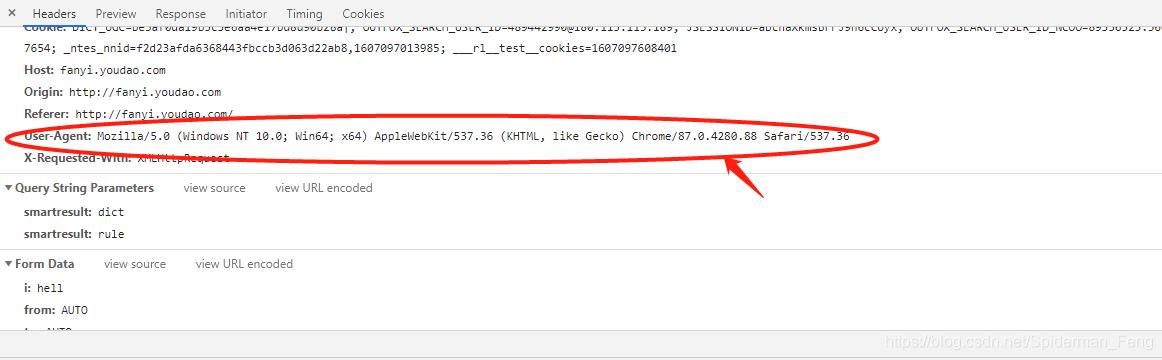
这个是提交电脑的基本信息,记住他,等会儿要用,等会儿伪装成电脑时可以用,因为电脑会有基本信息,而如果是python的话会显示成python3.8.4(因为我的版本是3.8.4),从而容易被服务器禁入
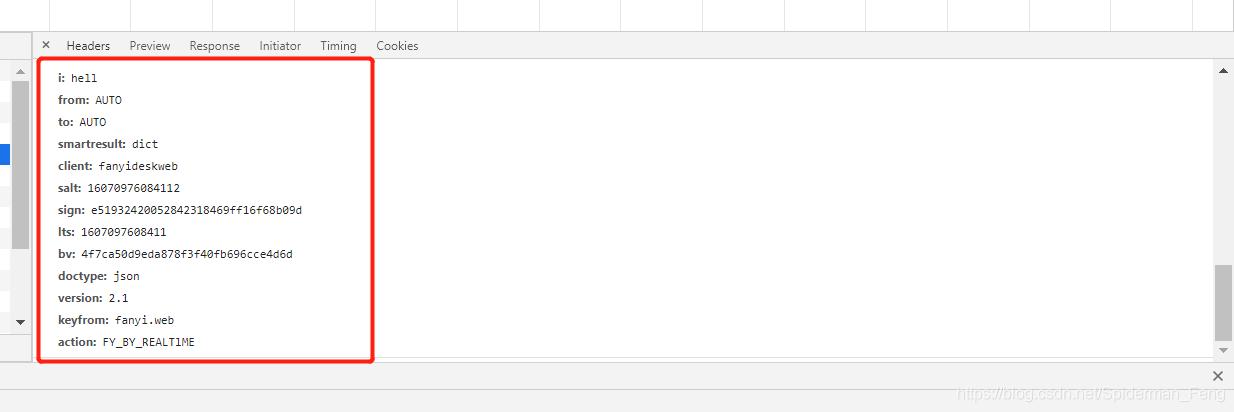
等会儿还要用
好,准备工作做完了,接下来开始干正事了
开始编写爬虫代码
下面是我写的代码,具体我就不细说了
#导入urllib库 import urllib.request import urllib.parse import json while True: #无限循环 content = input("请输入您要翻译的内容(输入 !!! 退出程序): ") #设置退出条件 if content == '!!!': break url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' #选择要爬取的网页,上面找过了 #加上一个帽子,减少被发现的概率(下面head列表的内容就是上面找的) head = {} head['User - Agent'] = '请替换' #伪装计算机提交翻译申请(下面的内容也在在上面有过,最好根据自己的进行修改) data = {} data['type'] = 'AUTO' data['i'] = content data['doctype'] = 'json' data['version'] = '2.1' data['keyfrom:'] = 'fanyi.web' data['ue'] = 'UTF-8' data['typoResult'] = 'true' data = urllib.parse.urlencode(data).encode('utf-8') response = urllib.request.urlopen(url, data) #解码 html = response.read().decode('utf-8') paper = json.loads(html) #打印翻译结果 print("翻译结果: %s" % (paper['translateResult'][0][0]['tgt']))运行结果

到此这篇关于python爬取有道词典的文章就介绍到这了,更多相关python有道词典内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
标签:urllib
利用python爬取有道词典的方法
看: 1569次 时间:2020-12-11 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!