这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法。
下面说说流程:
一、网站分析
首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主。可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜到这个网站是动态加载页面。
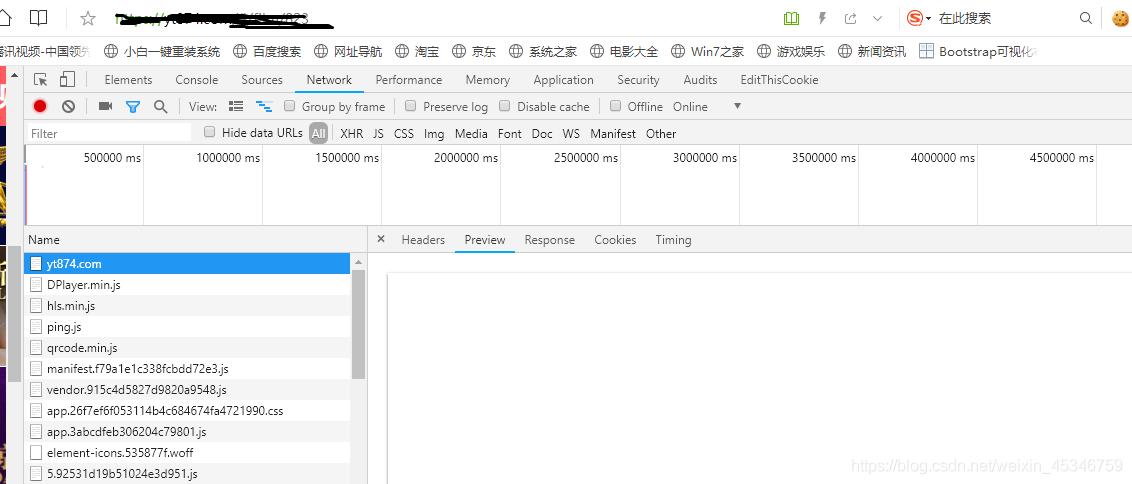
目前我知道的动态网页爬取的方法只有这两种:1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium对网页进行模拟访问。源代码问题好解决,重要的是我获取的源代码中有没有我需要的东西。我再一次进入网站进行F12检查源代码,点击左上角然后在页面点击一个视频获取一个元素的代码,结果里面没有嵌入的原视频链接(看来我真的是把别人想的太笨了)。
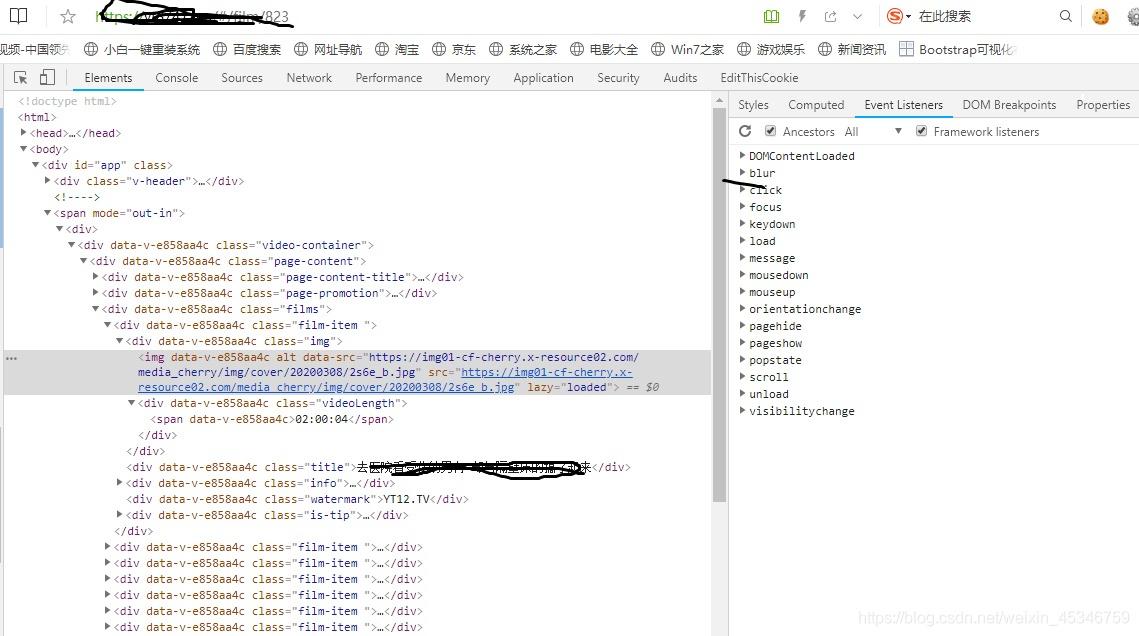
没办法只有进行抓包,去找js请求的接口。再一次F12打开网页调试工具,点击单独的一个视频进行播放,然后在Network中筛选一下,只看HXR响应(HXR全称是XMLHTTPRequest,HMLHTTP是AJAX网页开发技术的重要组成部分。除XML之外,XMLHTTP还能用于获取其它格式的数据,如JSON或者甚至纯文本。)。
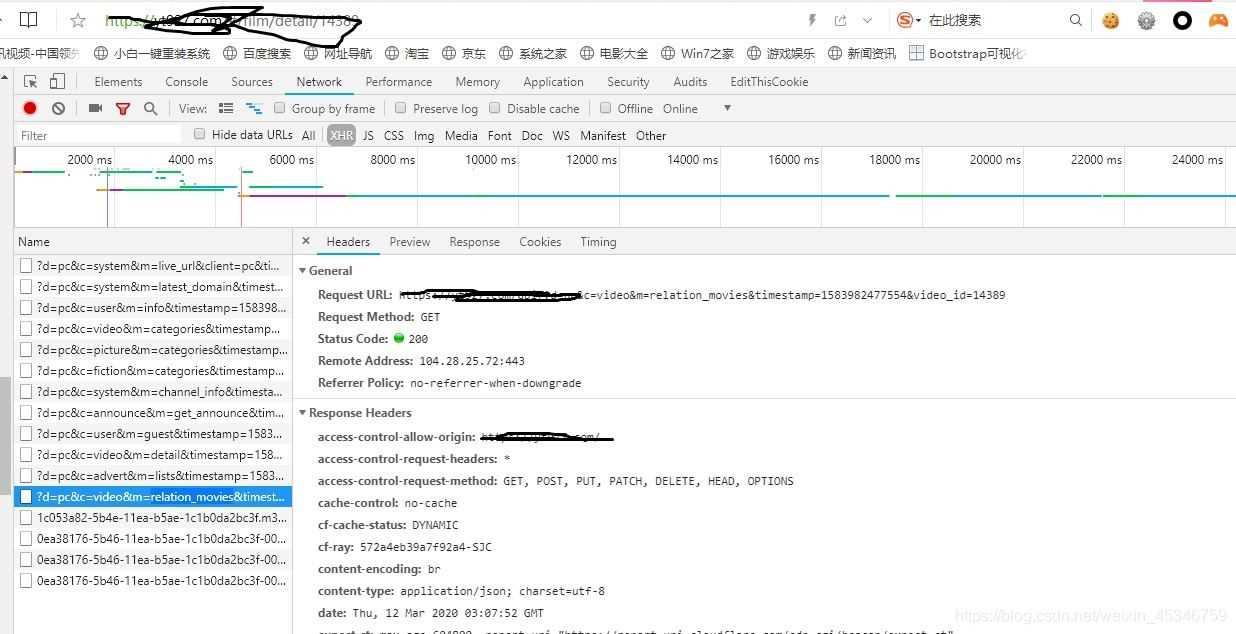
然后我一项一项的去检查返回的响应信息,发现当我点击播放的时候有后缀为.m3u8的链接,随后就不断刷新.ts文件的链接。
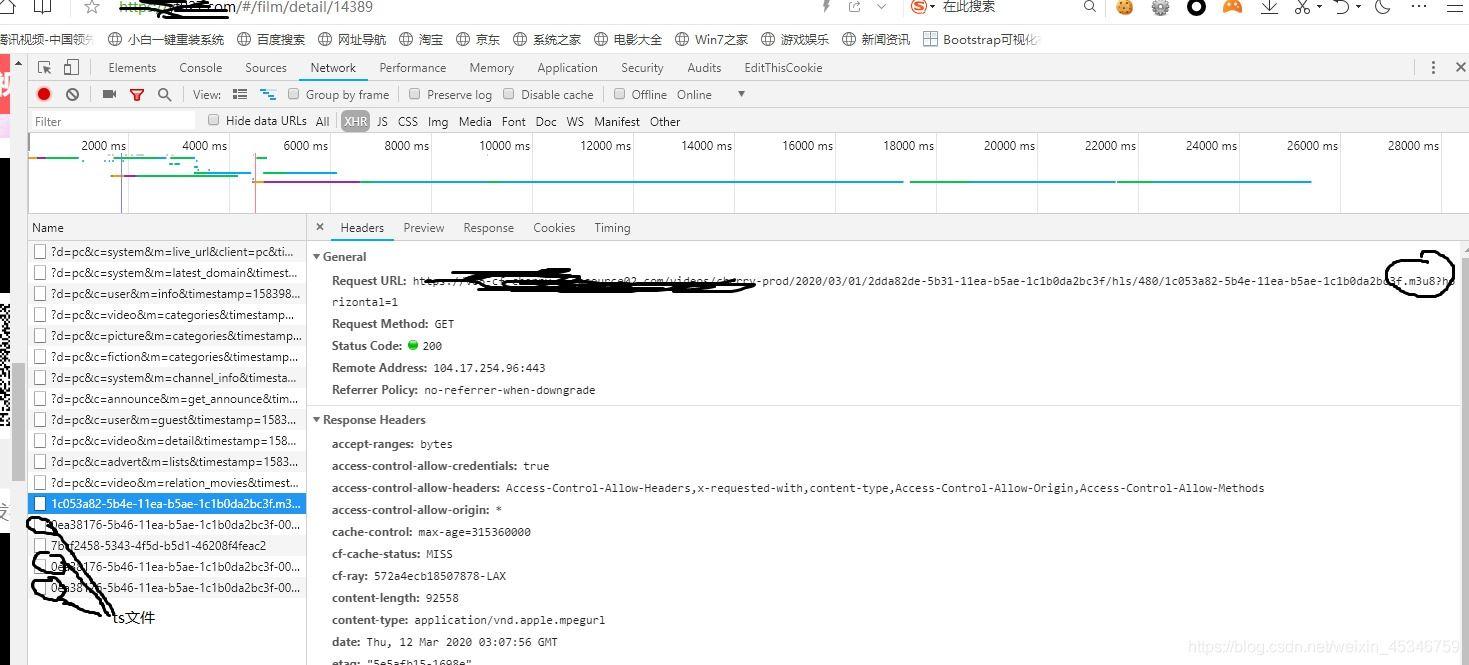
本来以为这就是原视频的地址,我傻傻的直接从这个m3u8文件的headers中的URL直接进入网站看看,结果傻眼了,获取的是一串串.ts的文件名。

没办法只能百度君了。 科普了一下,也就说我们必须把ts文件都下载下来进行合并之后才能转成视频。
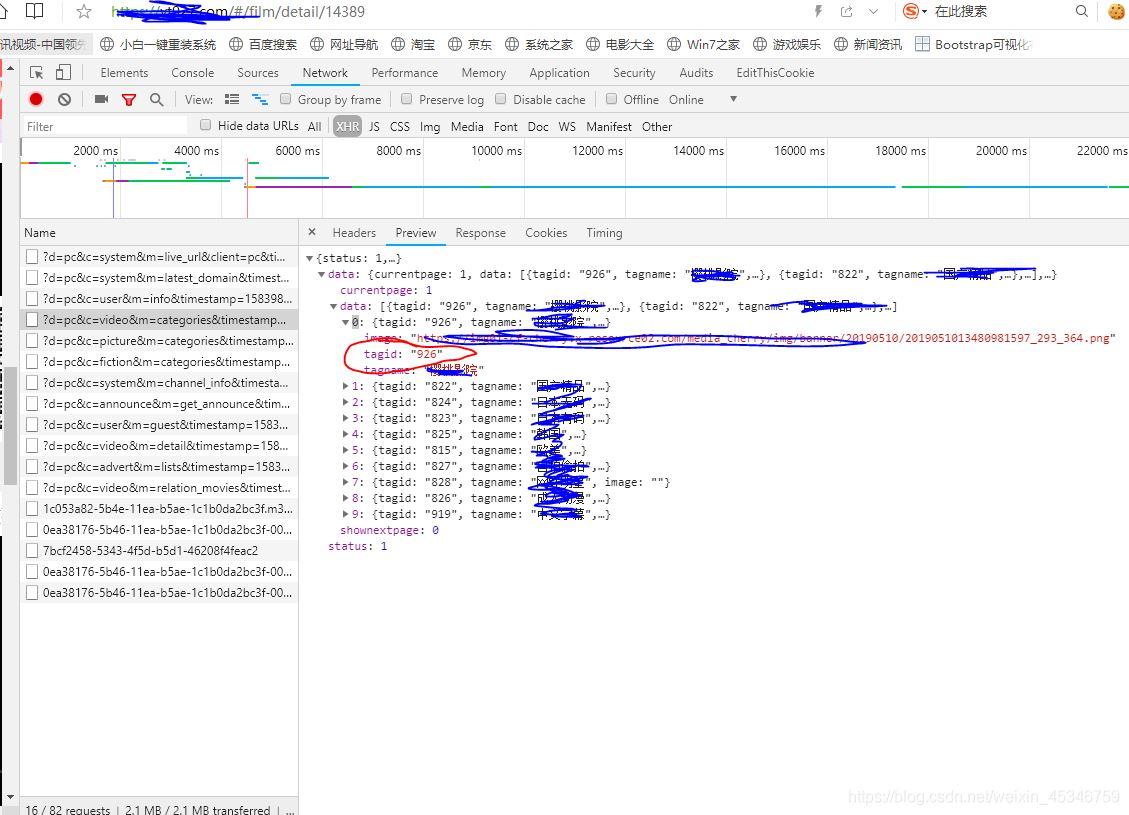
好了,视频原地址弄清楚了,现在我们开始从一个视频扩展到首页的整个页面的视频。再一次进行抓包分析,发现一个API中包含了首页的分类列表,然而里面并没有进入分类的URL地址,只有一个tagid值和图片的地址。

于是我又在主页点一个分类,再次进行抓包,发现了一个API中包含了一个分类的单页所有视频的信息,通过他们的headers中的URL对比发现,关于视频的前一部分都是https:xxxxxxx&c=video,然后m=categories,通过字面意思我们都可以知道是分类,而每个tagid值对应不同的分类。并且还发现每个URL中都追加了时间戳timestamp(这是web主为了确保请求不会在它第一次被发送后即缓存,看来还是有小心机啊)。当m=lists,则是每个分类下的视频列表,这里面我们就可以找到每个视频对应的ID了。
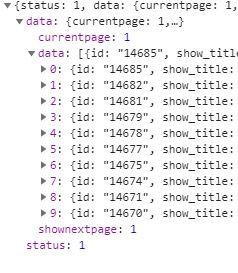
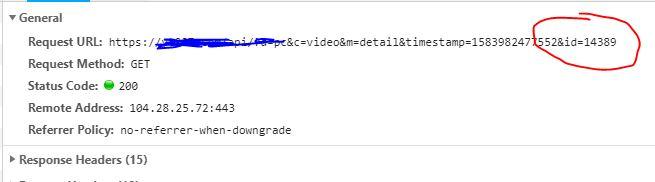
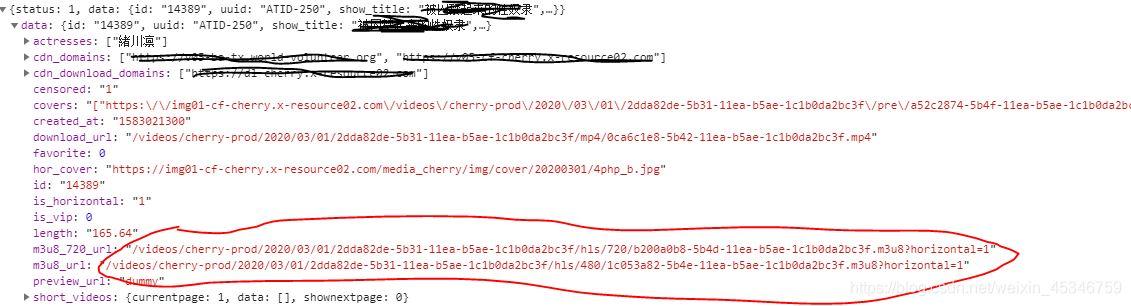
通过id我们可以获取到视频的详细信息,并且还有m3u8文件URL地址的后面一部分。
好了,网站我们解析清楚了,现在开始堆码了。
二、写代码
导入相关模块
import requests from datetime import datetime import re #import json import time import os #视频分类和视频列表URL的前一段 url = "http://xxxxxxx/api/?d=pc&c=video&" #m3u8文件和ts文件的URL前一段 m3u8_url ='https://xxxxxxxxxxxxx/videos/cherry-prod/2020/03/01/2dda82de-5b31-11ea-b5ae-1c1b0da2bc3f/hls/480/' #构造请求头信息 header = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2"} #创建空列表存放视频信息 vediomassag='' #返回当前时间戳 TimeStamp = int(datetime.timestamp(datetime.now()))2.定义函数,获取网站首页分类列表信息
#自定义函数获取分类 def get_vediocategory(url, TimeStamp): cgURL = url + "m=categories×tamp=" + str(TimeStamp) + '&' response = requests.get(cgURL, headers=header) category = response.text # strrr='"%s"'%category # return strrr return category3.定义函数,通过上一个函数返回的分类信息,根据分类对应的id,输入id并传输到当前URL中以便获取分类下的视频列表信息
#获取分类后的视频列表 def get_vedioList(url, TimeStamp, tagID): listURL = url + "m=lists×tamp=" + str(TimeStamp) + '&' + "page=1&tag_id=" + str(tagID) + "&sort_type=&is_vip=0" response = requests.get(listURL, headers=header) vedioLists = response.text return vedioLists4.在视频列表信息中获取视频对应的id,获取单个视频详细信息的URL
#获取单个视频的详细信息 def get_vediomassages(url, TimeStamp, vedioID): videoURL = url + "m=detail×tamp=" + str(TimeStamp) + '&' + "&id=" + str(vedioID) response = requests.get(videoURL, headers=header) vediomassag = response.text return vediomassag5.在视频详细信息中找到m3u8文件的下载地址,并将文件保存到创建的文件中
#将下载的m3u8文件放进创建的ts列表文件中 def get_m3u8List(m3u8_url,vediomassag): lasturl = r'"m3u8_720_url":"(.*?)","download_url' last_url =re.findall(lasturl,vediomassag) lastURL=m3u8_url+str(last_url) response = requests.get(lastURL, headers=header) tsList = response.text cur_path='E:\\files' #在指定路径建立文件夹 try: if not os.path.isdir(cur_path): #确认文件夹是否存在 os.makedirs(cur_path) #不存在则新建 except: print("文件夹存在") filename=cur_path+'\\t2.txt' #在文件夹中存放txt文件 f = open(filename,'a', encoding="utf-8") f.write(tsList) f.close print('创建%s文件成功'%(filename)) return filename6.将m3u8文件中的ts单个提取出来放进列表中。
# 提取ts列表文件的内容,逐个拼接ts的url,形成list def get_tsList(filename): ls = [] with open(filename, "r") as file: line = f.readlines() for line in lines: if line.endswith(".ts\n"): ls.append(line[:-1]) return ls7.遍历列表获取单个ts地址,请求下载ts文件放进创建的文件夹中
# 批量下载ts文件 def DownloadTs(ls): length = len(ls) root='E:\\mp4' try: if not os.path.exists(root): os.mkdir(root) except: print("文件夹创建失败") try: for i in range(length): tsname = ls[i][:-3] ts_URL=url+ls[i] print(ts_URL) r = requests.get(ts_URL) with open(root, 'a') as f: f.write(r.content) f.close() print('\r' + tsname + " -->OK ({}/{}){:.2f}%".format(i, length, i * 100 / length), end='') print("下载完毕") except: print("下载失败")代码整合
import requests from datetime import datetime import re #import json import time import os url = "http://xxxxxxxx/api/?d=pc&c=video&" m3u8_url ='https://xxxxxxxxxxxxxxx/videos/cherry-prod/2020/03/01/2dda82de-5b31-11ea-b5ae-1c1b0da2bc3f/hls/480/' header = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2"} vediomassag='' TimeStamp = int(datetime.timestamp(datetime.now())) #自定义函数获取分类 def get_vediocategory(url, TimeStamp): cgURL = url + "m=categories×tamp=" + str(TimeStamp) + '&' response = requests.get(cgURL, headers=header) category = response.text # strrr='"%s"'%category # return strrr return category #获取分类后的视频列表 def get_vedioList(url, TimeStamp, tagID): listURL = url + "m=lists×tamp=" + str(TimeStamp) + '&' + "page=1&tag_id=" + str(tagID) + "&sort_type=&is_vip=0" response = requests.get(listURL, headers=header) vedioLists = response.text return vedioLists #获取单个视频的详细信息 def get_vediomassages(url, TimeStamp, vedioID): videoURL = url + "m=detail×tamp=" + str(TimeStamp) + '&' + "&id=" + str(vedioID) response = requests.get(videoURL, headers=header) vediomassag = response.text return vediomassag #将下载的m3u8文件放进创建的ts列表文件中 def get_m3u8List(m3u8_url,vediomassag): lasturl = r'"m3u8_720_url":"(.*?)","download_url' last_url =re.findall(lasturl,vediomassag) lastURL=m3u8_url+str(last_url) response = requests.get(lastURL, headers=header) tsList = response.text cur_path='E:\\files' #在指定路径建立文件夹 try: if not os.path.isdir(cur_path): #确认文件夹是否存在 os.makedirs(cur_path) #不存在则新建 except: print("文件夹存在") filename=cur_path+'\\t2.txt' #在文件夹中存放txt文件 f = open(filename,'a', encoding="utf-8") f.write(tsList) f.close print('创建%s文件成功'%(filename)) return filename # 提取ts列表文件的内容,逐个拼接ts的url,形成list def get_tsList(filename): ls = [] with open(filename, "r") as file: line = f.readlines() for line in lines: if line.endswith(".ts\n"): ls.append(line[:-1]) return ls # 批量下载ts文件 def DownloadTs(ls): length = len(ls) root='E:\\mp4' try: if not os.path.exists(root): os.mkdir(root) except: print("文件夹创建失败") try: for i in range(length): tsname = ls[i][:-3] ts_URL=url+ls[i] print(ts_URL) r = requests.get(ts_URL) with open(root, 'a') as f: f.write(r.content) f.close() print('\r' + tsname + " -->OK ({}/{}){:.2f}%".format(i, length, i * 100 / length), end='') print("下载完毕") except: print("下载失败") '''# 整合所有ts文件,保存为mp4格式(此处函数复制而来未做实验,本人直接在根目录 命令行输入copy/b*.ts 文件名.mp4,意思是将所有ts文件合并转换成自己命名的MP4格式 文件。) def MergeMp4(): print("开始合并") path = "E://mp4//" outdir = "output" os.chdir(root) if not os.path.exists(outdir): os.mkdir(outdir) os.system("copy /b *.ts new.mp4") os.system("move new.mp4 {}".format(outdir)) print("结束合并")''' if __name__ == '__main__': # 将获取的分类信息解码显示出来 # print(json.loads(get_vediocategory(url, TimeStamp))) print(get_vediocategory(url, TimeStamp)) tagID = input("请输入分类对应的id") print(get_vedioList(url, TimeStamp, tagID)) vedioID = input("请输入视频对应的id") get_vediomassages(url, TimeStamp, vedioID) get_m3u8List(m3u8_url,vediomassag) get_tsList(filename) DownloadTs(ls) # MergeMp4()此时正在下载

三、问题:
首先对于这种网站采取的爬取方法有很多,而我的方法相对来说有点太低端了,并且我也 是第一次写博客,第一次写爬虫这类程序,在格式上命名上存在着很多问题,函数的用法不全面。并且在运行的时候效率低速度太慢。在获取分类列表和视频列表时,因为是JSON文件,需要转码,过程太多加上程序不够稳定我就注释掉了。还有就是对于这种动态网页了解不够,所以学爬虫的小伙伴一定要把网页的基础搞好。希望各位大佬多指正多批评,让我们这些小白一起努力学好Python。
注意:里面所有的链接我的给打码了,怕被和谐了哈哈
到此这篇关于Python爬虫进阶之爬取某视频并下载的实现的文章就介绍到这了,更多相关Python 爬取某视频并下载内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
- << 上一篇 下一篇 >>
Python爬虫进阶之爬取某视频并下载的实现
看: 1878次 时间:2020-12-11 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!