代码
import requests import time from tqdm import tqdm from bs4 import BeautifulSoup """ Author: Jack Cui Wechat: https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA """ def get_content(target): req = requests.get(url = target) req.encoding = 'utf-8' html = req.text bf = BeautifulSoup(html, 'lxml') texts = bf.find('div', id='content') content = texts.text.strip().split('\xa0'*4) return content if __name__ == '__main__': server = 'https://www.xsbiquge.com' book_name = '诡秘之主.txt' target = 'https://www.xsbiquge.com/15_15338/' req = requests.get(url = target) req.encoding = 'utf-8' html = req.text chapter_bs = BeautifulSoup(html, 'lxml') chapters = chapter_bs.find('div', id='list') chapters = chapters.find_all('a') for chapter in tqdm(chapters): chapter_name = chapter.string url = server + chapter.get('href') content = get_content(url) with open(book_name, 'a', encoding='utf-8') as f: f.write(chapter_name) f.write('\n') f.write('\n'.join(content)) f.write('\n')下载效果:
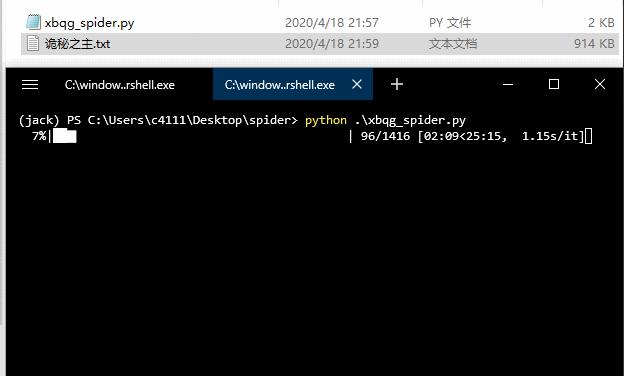
可以看到,小说内容保存到“诡秘之主.txt”中,小说一共 1416 章,下载需要大约 20 分钟,每秒钟大约下载 1 个章节。
下载完成,实际花费了 27 分钟。
20 多分钟下载一本小说,你可能感觉太慢了。想提速,可以使用多进程,大幅提高下载速度。如果使用分布式,甚至可以1秒钟内下载完毕。
但是,我不建议这样做。
我们要做一个友好的爬虫,如果我们去提速,那么我们访问的服务器也会面临更大的压力。
以我们这次下载小说的代码为例,每秒钟下载 1 个章节,服务器承受的压力大约 1qps,意思就是,一秒钟请求一次。
如果我们 1 秒同时下载 1416 个章节,那么服务器将承受大约 1416 qps 的压力,这还是仅仅你发出的并发请求数,再算上其他的用户的请求,并发量可能更多。
如果服务器资源不足,这个并发量足以一瞬间将服务器“打死”,特别是一些小网站,都很脆弱。
过大并发量的爬虫程序,相当于发起了一次 CC 攻击,并不是所有网站都能承受百万级别并发量的。
所以,写爬虫,一定要谨慎,勿给服务器增加过多的压力,满足我们的获取数据的需求,这就够了。
你好,我也好,大家好才是真的好。
以上就是python 爬取小说并下载的示例的详细内容,更多关于python 爬取小说下载的资料请关注python博客其它相关文章!
- << 上一篇 下一篇 >>
python 爬取小说并下载的示例
看: 2876次 时间:2020-12-11 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!