基本环境配置
- python 3.6
- pycharm
- requests
- parsel
相关模块pip安装即可
目标网页
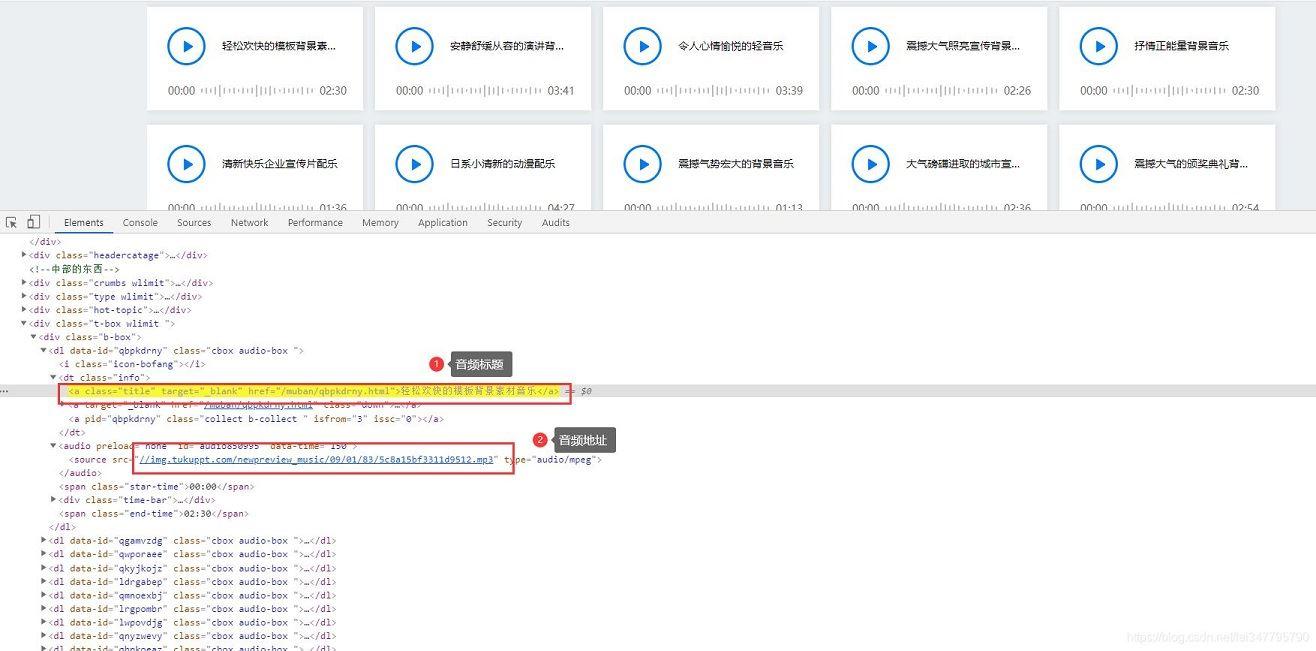
请求网页
import requests url = 'https://www.tukuppt.com/peiyue/zonghe_0_0_0_0_0_0_1.html' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36', } response = requests.get(url=url, headers=headers)解析网页,提取数据
import parsel selector = parsel.Selector(response.text) urls = selector.css('#audio850995 source::attr(src)').getall() titles = selector.css('.b-box .info .title::text').getall() data = zip(urls, titles) for i in data: mp3_url = 'https:' + i[0] title = i[1]保存数据
def download(url, title): response = requests.get(url=url, headers=headers) path = 'D:\\python\\demo\\熊猫办公素材\\背景音乐\\' + title + '.mp3' with open(path, mode='wb') as f: f.write(response.content)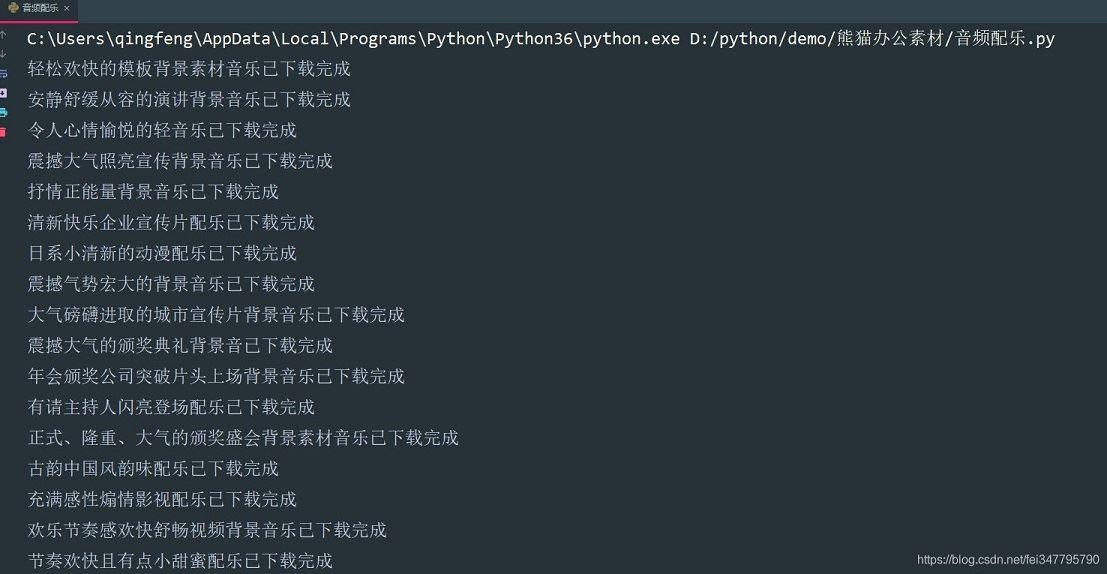

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:requests
基于Python爬取素材网站音频文件
看: 1581次 时间:2020-12-10 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!