查看字符编码:
import chardet response = chardet.detect(b'\xe5\xbd\x93\xe5\x89\x8d\xe7\x9b\xae\xe5\xbd\x95\xe4\xb8\x8b\xe6\x89\x80\xe6\x9c\x89\xe6\x96\x87\xe4\xbb\xb6\xe5\x90\x8d\xe6\xb1\x87\xe6\x80\xbb\xe5\x88\x97\xe8\xa1\xa8') print(response) {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}乱码字符转换:
response = b'\xe5\xbd\x93\xe5\x89\x8d\xe7\x9b\xae\xe5\xbd\x95\xe4\xb8\x8b\xe6\x89\x80\xe6\x9c\x89\xe6\x96\x87\xe4\xbb\xb6\xe5\x90\x8d\xe6\xb1\x87\xe6\x80\xbb\xe5\x88\x97\xe8\xa1\xa8' print(response.decode('utf8'))# def decode_char(*args): # response = args[0] # print(response.decode('utf8')) # # c = b'\a8\xe5\x90\xa7\xef\xbc\x81' # # decode_char(c)补充知识:python3 中怎么把类似这样的'\xe5\xae\x9d\xe9\xb8\xa1\xe5\xb8\x82'转换成汉字输出
在编程的过程中遇到了类似的困扰,网上查了很多解决思路,终于算是明白了一些,这里和大家分享 一下。
python3相对于python2最重要的新特性之一就是对字符串(文本)和二进制数据流做了明确的区分,文本总是Unicode,由字符类型表示,而二进制数据则由bytes类型表示,python3不会以任意隐式方式混用字节型和字符型,也不能拼接字符串和字节流(python2中可以,会自动进行转换),也不能在字节流中搜索字符串,也不能将字符串传入参数为字节流的函数。
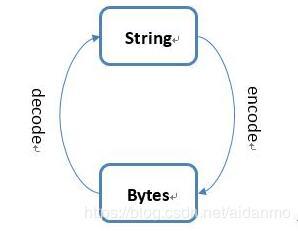
str和bytes类型之间的相互转换
字符串类str有一个encode()方法,它是字符串向比特流的编码过程。
bytes类则有一个decode()方法,它是比特流向字符串的解码过程
encode过程
s = '绝地求生' ss = s.encode() print(type(ss)) print(ss)运行结果:

decode过程
s = b'\xe7\xbb\x9d\xe5\x9c\xb0\xe6\xb1\x82\xe7\x94\x9f' ss = s.decode() print(type(ss)) print(ss)运行结果:

了解过基本的转化过程,下面回到主题,如何将'\xe7\xbb\x9d\xe5\x9c\xb0\xe6\xb1\x82\xe7\x94\x9f'转换成汉字输出呢?
要解决的问题是将bytes类型的内容以汉字的形式输出,但是该部分内容是字符串类型。因此首先需要将该str转换成bytes类型,再decode解码为str输出。这里需要用到的方法是encode(‘raw_unicode_escape')。当然,也可以使用decode(‘raw_unicode_escape')方法输出内容为bytes形式的字符串
s = '\xe7\xbb\x9d\xe5\x9c\xb0\xe6\xb1\x82\xe7\x94\x9f' ss = s.encode('raw_unicode_escape') print(type(ss)) print(ss) sss = ss.decode() print(sss)结果:

方法补充:如果我们直接定义bytes类型的变量,也可以直接使用str(s, ‘utf8')的方式输出汉字
s = b'\xe7\xbb\x9d\xe5\x9c\xb0\xe6\xb1\x82\xe7\x94\x9f' print(type(s)) print(s) ss = str(s, 'utf8') print(ss)结果:

第二种方法可以输出从网络上直接抓取的网页中包含的中文字符。
我们使用如下代码,抓取网页www.baidu.com。
import urllib.request response = urllib.request.urlopen('http://www.baidu.com') html = response.read() print(html)显示的结果中,中文部分会以\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80代替,这里可以使用方法二进行转换。
import urllib.request response = urllib.request.urlopen('http://www.baidu.com') html =str(response.read(),'utf-8') print(html)结果如下:
以上这篇Python3之乱码\xe6\x97\xa0\xe6\xb3\x95处理方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:urllib
Python3之乱码\xe6\x97\xa0\xe6\xb3\x95处理方式
看: 2867次 时间:2020-07-10 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!