下面通过实验来探索Pytorch分配显存的方式。
实验显存到主存
我使用VSCode的jupyter来进行实验,首先只导入pytorch,代码如下:
import torch
打开任务管理器查看主存与显存情况。情况分别如下:


在显存中创建1GB的张量,赋值给a,代码如下:
a = torch.zeros([256,1024,1024],device= 'cpu')
查看主存与显存情况:


可以看到主存与显存都变大了,而且显存不止变大了1G,多出来的内存是pytorch运行所需的一些配置变量,我们这里忽略。
再次在显存中创建一个1GB的张量,赋值给b,代码如下:
b = torch.zeros([256,1024,1024],device= 'cpu')
查看主显存情况:


这次主存大小没变,显存变高了1GB,这是合情合理的。然后我们将b移动到主存中,代码如下:
b = b.to('cpu')
查看主显存情况:


发现主存是变高了1GB,显存却只变小了0.1GB,好像只是将显存张量复制到主存一样。实际上,pytorch的确是复制了一份张量到主存中,但它也对显存中这个张量的移动进行了记录。我们接着执行以下代码,再创建1GB的张量赋值给c:
c = torch.zeros([256,1024,1024],device= 'cuda')
查看主显存情况:

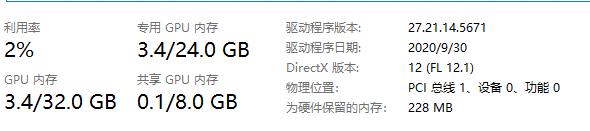
发现只有显存大小变大了0.1GB,这说明,Pytorch的确记录了显存中张量的移动,只是没有立即将显存空间释放,它选择在下一次创建新变量时覆盖这个位置。接下来,我们重复执行上面这行代码:
c = torch.zeros([256,1024,1024],device= 'cuda')
主显存情况如下:


明明我们把张量c给覆盖了,显存内容却变大了,这是为什么呢?实际上,Pytorch在执行这句代码时,是首先找到可使用的显存位置,创建这1GB的张量,然后再赋值给c。但因为在新创建这个张量时,原本的c依然占有1GB的显存,pytorch只能先调取另外1GB显存来创建这个张量,再将这个张量赋值给c。这样一来,原本的那个c所在的显存内容就空出来了,但和前面说的一样,pytorch并不会立即释放这里的显存,而等待下一次的覆盖,所以显存大小并没有减小。
我们再创建1GB的d张量,就可以验证上面的猜想,代码如下:
d = torch.zeros([256,1024,1024],device= 'cuda')
主显存情况如下:


显存大小并没有变,就是因为pytorch将新的张量创建在了上一步c空出来的位置,然后再赋值给了d。另外,删除变量操作也同样不会立即释放显存:
del d
主显存情况:


显存没有变化,同样是等待下一次的覆盖。
主存到显存
接着上面的实验,我们创建直接在主存创建1GB的张量并赋值给e,代码如下:
e = torch.zeros([256,1024,1024],device= 'cpu')
主显存情况如下:


主存变大1GB,合情合理。然后将e移动到显存,代码如下:
e = e.to('cuda')
主显存情况如下:


主存变小1GB,显存没变是因为上面张量d被删除没有被覆盖,合情合理。说明主存的释放是立即执行的。
总结
通过上面的实验,我们了解到,pytorch不会立即释放显存中失效变量的内存,它会以覆盖的方式利用显存中的可用空间。另外,如果要重置显存中的某个规模较大的张量,最好先将它移动到主存中,或是直接删除,再创建新值,否则就需要两倍的内存来实现这个操作,就有可能出现显存不够用的情况。
实验代码汇总如下:
#%% import torch #%% a = torch.zeros([256,1024,1024],device= 'cuda') #%% b = torch.zeros([256,1024,1024],device= 'cuda') #%% b = b.to('cpu') #%% c = torch.zeros([256,1024,1024],device= 'cuda') #%% c = torch.zeros([256,1024,1024],device= 'cuda') #%% d = torch.zeros([256,1024,1024],device= 'cuda') #%% del d #%% e = torch.zeros([256,1024,1024],device= 'cpu') #%% e = e.to('cuda')到此这篇关于Pytorch显存动态分配规律探索的文章就介绍到这了,更多相关Pytorc显存分配规律内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
详解Pytorch显存动态分配规律探索
看: 1410次 时间:2020-11-20 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!