前言
最近每天都有玩微信读书上面的每日一答的答题游戏,完全答对12题后,可以瓜分无限阅读卡。但是从小就不太爱看书的我,很难连续答对12道题,由此,产生了写一个半自动答题小程序的想法。我们先看一张效果图吧(ps 这里主要是我电脑有点卡,点击左边地选项有延迟)
项目GIthub地址:微信读书答题python小程序
觉得对你有帮助的请点个⭐来支持一下吧。
演示图:
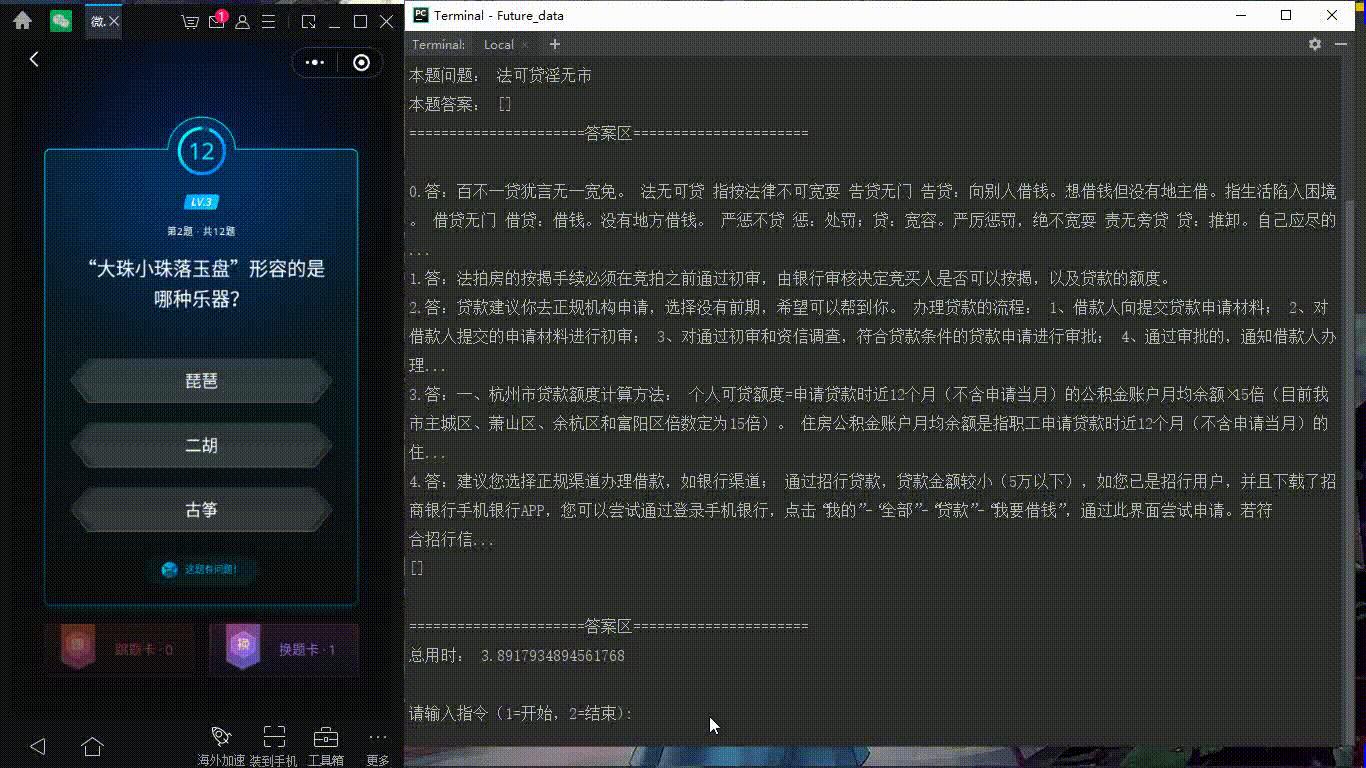
做前准备
- mumu模拟器 因为手边没有安卓手机,所以只能在模拟器上进行模拟,如果手上有安卓手机地,可以适当地修改一下程序。需要安装微信和微信读书这两个软件
- python工具包:BeautifulSoup4、Pillow、urllib、requests、re、base64、time
思路
- 截屏含有题目和答案的图片(范围可以自己指定)
- 使用百度的图片识别技术将图片转化为文字,并进行一系列处理,分别将题目和答案进行存储
- 调动百度知道搜索接口,将题目作为搜索关键字进行答案搜索
- 将搜索出来的内容使用BeautifulSoup4进行答案提取,这里可以设置答案提取数量
- 将搜索结果进行输出显示
附:这里我还加了一个自动推荐答案,利用百度短文本相似接口和选项是否出现在答案中这两种验证方法进行验证,推荐相似度最高的答案。准确度还可以,但是比较耗时间,比正常情况下时间要多上一倍。
开始写代码
1. 导入工具包
import requests #访问网站 import re#正则表达式匹配 import base64#编码 from bs4 import BeautifulSoup #处理页面数据 from urllib import parse #进行url编码 import time #统计时间 from PIL import ImageGrab #处理图片2. 编写类和初始化方法
class autogetanswer(): def __init__(self,StartAutoRecomment=True,answernumber=5): self.StartAutoRecomment=StartAutoRecomment self.APIKEY=['BICrxxxxxxxxNNI','CrHGxxxxxxxx3C'] self.SECRETKEY=['BgL4jxxxxxxxxxGj9','1xo0jxxxxxx90cx'] self.accesstoken=[] self.baiduzhidao='http://zhidao.baidu.com/search?' self.question='' self.answer=[] self.answernumber=answernumber self.searchanswer=[] self.answerscore=[] self.reanswerindex=0 self.imageurl='answer.jpg' self.position=(35,155,355,680) self.titleregular1=r'(10题|共10|12题|共12|翻倍)' self.titleregular2=r'(\?|\?)' self.answerregular1=r'(这题|问题|跳题|换题|题卡|换卡|跳卡|这有)'- self.StartAutoRecomment 是否开启自动推荐答案,默认为True
- self.APIKEY 百度图像转文字、百度短文本相似度分析 这两个接口的apikey
- self.SECRETKEY 百度图像转文字、百度短文本相似度分析 这两个接口的secretkey
这两个key值我就没法提供给大家了,大家可以自己去百度云官方申请,免费额度大概有5万,足够我们使用了。
申请过程大家可以参考这个博客,很简单的如何申请百度文字识别apikey和Secret Key
- self.accesstoken 存储申请使用接口的accesstoken值
- self.baiduzhidao 百度知道搜索接口地址
- self.imageurl 图片地址
- self.position 截图方位信息,依次分别是左间距、上间距、右间距、下间距
- self.titleregular1、.titleregular2、answerregular1 这些是进行题目和答案处理的条件
3. 获得accesstoken值
def GetAccseetoken(self): for i in range(len(self.APIKEY)): host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(self.APIKEY[i],self.SECRETKEY[i]) response = requests.get(host) jsondata = response.json() self.accesstoken.append(jsondata['access_token'])这是官方提供的获取accesstoken的摸板,大家直接使用就行了。
4. 图像转文字以及相关处理
def OCR(self,filename): request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic" # 二进制方式打开图片文件 f = open(filename, 'rb') img = base64.b64encode(f.read()) params = {"image":img} access_token = self.accesstoken[0] request_url = request_url + "?access_token=" + access_token headers = {'content-type': 'application/x-www-form-urlencoded'} response = requests.post(request_url, data=params, headers=headers) #===上面是使用百度图片转文字接口转化,返回格式为json if response: result = response.json() questionstart=0 answerstart=0 self.question='' self.answer=[] #确定题目和答案所在的位置 for i in range(result['words_result_num']): if(re.search(self.titleregular1,result['words_result'][i]['words'])!=None): questionstart=i+1 if(re.search(self.titleregular2,result['words_result'][i]['words'])!=None): answerstart=i+1 #下面是进行题目和答案的处理 if(answerstart!=0): for title in result['words_result'][questionstart:answerstart]: if(re.search(self.answerregular1,title['words'])!=None): pass else: self.question+=title['words'] for answer in result['words_result'][answerstart:]: if(re.search(self.answerregular1,answer['words'])!=None): pass else: if(str(answer['words']).find('.')>0): answer2 = str(answer['words']).split('.')[-1] else: answer2=answer['words'] self.answer.append(answer2) else: for title in result['words_result'][questionstart:]: if(re.search(self.answerregular1,title['words'])!=None): pass else: self.question+=title['words'] print("本题问题:",self.question) print("本题答案:",self.answer) return response.json()#可有可无此方法是将图片转化为文字,进行图片中的文字识别,格式如下:
{ "log_id": 2471272194, "words_result_num": 2, "words_result": [ {"words": " TSINGTAO"}, {"words": "青島睥酒"} ] }下面我们以下面的图为例,我们是如何去除掉干扰信息的:
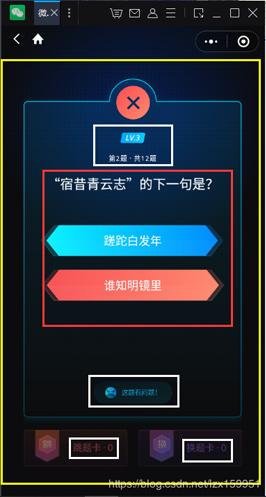
上图就是程序在实际运行中的情况,黄色框内就是程序截取的图像(这个通过初始化方法的参数中的position可以进行设置),
我们需要的是红色框内的信息,这包含题目和答案选项。文字识别后,白色框里面的字也会和红色框里的字一同被识别,并以json形式输出,这些信息对我们就是干扰信息,所以,我通过建立了初始化方法里titleregular1、titleregular2、answerregular1 这三个标准进行判定,白色框里的文字与对应,如果判断包含的话,就不添加到题目中或者答案中。
5. 百度知道进行答案搜索
def BaiduAnswer(self): request = requests.session() headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'} data = {"word":self.question} url=self.baiduzhidao+'lm=0&rn=10&pn=0&fr=search&ie=gbk&'+parse.urlencode(data,encoding='GB2312') ress = request.get(url,headers=headers) ress.encoding='gbk' if ress: soup = BeautifulSoup(ress.text,'lxml') result = soup.find_all("dd",class_="dd answer") if(len(result)!=0 and len(result)>self.answernumber): length=5 else: length=len(result) for i in range(length): self.searchanswer.append(result[i].text)这里是模拟浏览器进行百度知道搜索答案,将返回的文本交给BeautifulSoup进行处理,提取出我们需要的部分。后面最后几句有一个判定,如果查询到的答案数量超过我们设置的答案数,比如是5,那么就将前5个答案放入searchanswer列表中,如果查询到的答案数量要少于我们设置的,返回所有答案。
6. 短文本相似度分析
def CalculateSimilarity(self,text1,text2): access_token = self.accesstoken[1] request_url="https://aip.baidubce.com/rpc/2.0/nlp/v2/simnet" request_url = request_url + "?access_token=" + access_token headers = {'Content-Type': 'application/json'} data={"text_1":text1,"text_2":text2,"model":"GRNN"} response = requests.post(request_url, json=data, headers=headers) response.encoding='gbk' if response: try: result = response.json() return result['score'] except: return 0这里调用的是百度短文本相似度分析的接口,用于分析选项与查询到的答案的相似度,以此来推荐一个参考答案。这个是官方给的摸板,直接调用,更换一下参数即可。
7. 自动给出一个参考答案
def AutoRecomment(self): if(len(self.answer)==0): return for i in range(len(self.answer)): scores=[] flag=0 for j in range(len(self.searchanswer)): if(j!=0and (j%2==0)): time.sleep(0.1) score = tools.CalculateSimilarity(tools.answer[i],tools.searchanswer[j]) if(tools.answer[i] in tools.searchanswer[j]): score=1 scores.append(score) if(score>0.8): flag=1 self.answerscore.append(score) break if(flag==0): self.answerscore.append(max(scores)) self.reanswerindex = self.answerscore.index(max(self.answerscore))这里调用了咱们第六步的CalculateSimilarity()方法,统计每一个选项与搜索到的答案相似度,取最高的存入answerscore列表中。这里我又加了一个操作,我发现这个相似度匹配有时正确率比较低,所以这里加了一个判定,若选项在搜索到的答案中出现,给予一个最大相似值,也就是1,这就大大提高了推荐的准确度。
8. 初始化参数
def IniParam(self): self.accesstoken=[] self.question='' self.answer=[] self.searchanswer=[] self.answerscore=[] self.reanswerindex=0相关参数的初始化,因为每进行完一道题,要对存储题和答案以及相关信息的数组进行清空,否则会对后面题的显示产生影响。
9. 主方法
def MainMethod(self): while(True): try: order = input('请输入指令(1=开始,2=结束):') if(int(order)==1): start = time.time() self.GetAccseetoken() img = ImageGrab.grab(self.position)#左、上、右、下 img.save(self.imageurl) self.OCR(self.imageurl) self.BaiduAnswer() if(self.StartAutoRecomment): self.AutoRecomment() print("======================答案区======================\n") for i in range(len(self.searchanswer)): print("{}.{}".format(i,self.searchanswer[i])) end = time.time() print(self.answerscore) if(self.StartAutoRecomment and len(self.answer)>0): print("\n推荐答案:",self.answer[self.reanswerindex]) print("\n======================答案区======================") print("总用时:",end-start,end="\n\n") self.IniParam() else: break except: print("识别失败,请重新尝试") self.IniParam() pass这里主要是一个while循环,通过输入指定来判断是否结束循环。
这里说一下下面这两个语句:
img = ImageGrab.grab(self.position)#左、上、右、下 img.save(self.imageurl)这两个语句是用来截取我们指定位置的图片,然后进行图片的保存。
总结
上述呢,就是整个项目完成的流程,整体运行是几乎每什么问题,但是还是存在许多可优化的空间。也欢迎大家对此感兴趣的留言,说说你的改进意见,我会非常感谢,并认真考虑进去。期待与大家的讨论!😄
到此这篇关于从0到1使用python开发一个半自动答题小程序的实现的文章就介绍到这了,更多相关python 半自动答题小程序内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
- << 上一篇 下一篇 >>
从0到1使用python开发一个半自动答题小程序的实现
看: 1647次 时间:2020-07-09 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!