本文实例讲述了Python利用Scrapy框架爬取豆瓣电影。分享给大家供大家参考,具体如下:
1、概念
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包
pip install scrapyscrapy的组成结构如下图所示
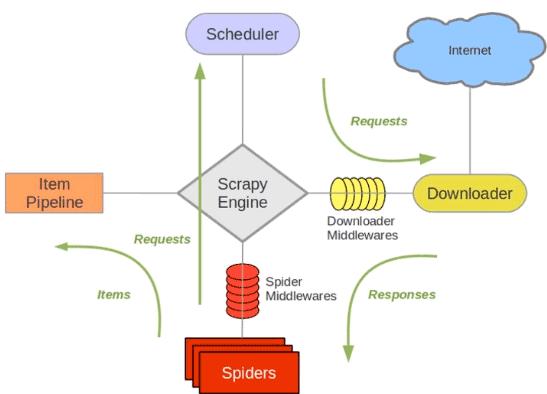
引擎Scrapy Engine,用于中转调度其他部分的信号和数据传递
调度器Scheduler,一个存储Request的队列,引擎将请求的连接发送给Scheduler,它将请求进行排队,但引擎需要时再将队列中的第一个请求发送给引擎
下载器Downloader,引擎将请求Request链接发送给Downloader之后它就从互联网上下载相应的数据,并将返回的数据Responses交给引擎
爬虫Spiders,引擎将下载的Responses数据交给Spiders进行解析,提取我们需要的网页信息。如果在解析中发现有新的所需要的url连接,Spiders会将链接交给引擎存入调度器
管道Item Pipline,爬虫会将页面中的数据通过引擎交给管道做进一步处理,进行过滤、存储等操作
下载中间件Downloader Middlewares,自定义扩展组件,用于在请求页面时封装代理、http请求头等操作
爬虫中间件Spider Middlewares,用于对进入Spiders的Responses和出去的Requests等数据作一些修改
scrapy的工作流程:首先我们将入口url交给spider爬虫,爬虫通过引擎将url放入调度器,经调度器排队之后返回第一个请求Request,引擎再将请求转交给下载器进行下载,下载好的数据交给爬虫进行爬取,爬取的数据一部分是我们需要的数据交给管道进行数据清洗和存储,还有一部分是新的url连接会再次交给调度器,之后再循环进行数据爬取
2、新建Scrapy项目
首先在存放项目的文件夹内打开命令行,在命令行下输入scrapy startproject 项目名称,就会在当前文件夹自动创建项目所需的python文件,例如创建一个爬取豆瓣电影的项目douban,其目录结构如下:
Db_Project/ scrapy.cfg --项目的配置文件 douban/ --该项目的python模块目录,在其中编写python代码 __init__.py --python包的初始化文件 items.py --用于定义item数据结构 pipelines.py --项目中的pipelines文件 settings.py --定义项目的全局设置,例如下载延迟、并发量 spiders/ --存放爬虫代码的包目录 __init__.py ...之后进入spiders目录下输入scrapy genspider 爬虫名 域名,就会生成爬虫文件douban.py文件,用于之后定义爬虫的爬取逻辑和正则表达式等内容
scrapy genspider douban movie.douban.com3、定义数据
要爬取的豆瓣电影网址为 https://movie.douban.com/top250,其中的每个电影如下

我们要爬取其中的序号、名称、介绍、星级、评论数、描述这几个关键信息,因此需要在管道文件items.py中先定义这几个对象,类似于ORM,通过scrapy.Field()方法为每个字段定义一个数据类型
import scrapy class DoubanItem(scrapy.Item): ranking = scrapy.Field() # 排名 name = scrapy.Field() # 电影名 introduce = scrapy.Field() # 简介 star = scrapy.Field() # 星级 comments = scrapy.Field() # 评论数 describe = scrapy.Field() # 描述4、数据爬取
打开之前在spiders文件夹下创建的爬虫文件movie.py如下所示,以及自动创建了三个变量和一个方法,在parse方法中进行返回数据response的处理,我们需要在start_urls提供爬虫的入口地址。注意爬虫会自动过滤掉allowed_domains之外的域名,因此需要注意这个变量的赋值
# spiders/movie.py import scrapy class MovieSpider(scrapy.Spider): # 爬虫名 name = 'movie' # 允许爬取的域名 allowed_domains = ['movie.douban.com'] # 入口url start_urls = ['https://movie.douban.com/top250'] def parse(self, response): pass在进行数据爬取之前首先要设置一些网络代理,在settings.py文件内找到USER_AGENT变量修改如下:
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0'可以在命令行通过如下命令启动名为douban的爬虫:scrapy crawl douban,也可以编写一个启动文件run.py文件如下,运行即可
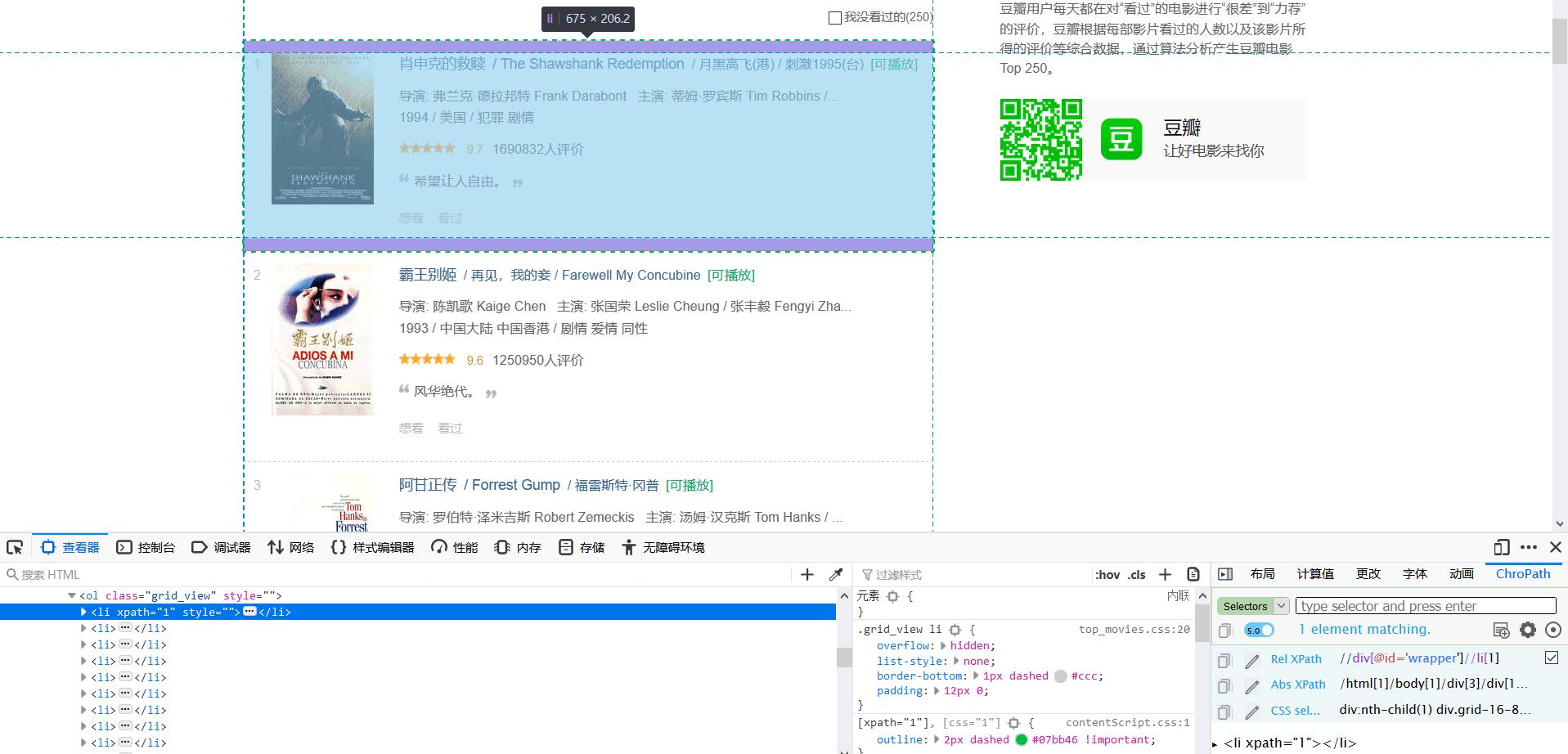
from scrapy import cmdline cmdline.execute('scrapy crawl movie'.split())接下来要对爬取到的数据进行过滤,通过Xpath规则可以使我们便捷地选中网页中的指定元素,如下图所示,每个电影条目都包裹在
- 下的一个
- 标签,因此通过xpath://ol[@class='grid_view']/li 就选中了本页面所有的电影条目。可以通过谷歌浏览器的Xpath插件或者火狐浏览器的ChroPath获得xpath值,在浏览器右键查看元素,弹出如下图所示的开发者工具,其中最右边就是ChroPath插件,它直观地显示了元素的Xpath值: //div[@id='wrapper']//li
爬虫response对象的xpath()方法可以直接处理xpath规则字符串并返回对应的页面内容,这些内容都是选择器对象Selector,可以进一步作细化的内容选取,通过xpath选择出其中的电影名字、简介、评价、星级等内容,即之前在items.py文件中所定义的数据结构DoubanItem。循环遍历每个电影列表从其中爬取到准确的电影信息,并保存为DoubanItem对象item,最后通过yield将item对象从Spiders返回到Item管道。
爬虫除了从页面提取Item数据之外还会爬取url链接从而形成下一页的Request请求,如下图所示为豆瓣页面底部的下一页信息,第二页的参数为"?start=25&filter=",与网站地址https://movie.douban.com/top250拼接起来就可以得到下一页面的地址。和上面一样通过xpath提取该内容,如果不为空,则拼接得到的Request请求yield提交给调度器

最终的爬虫movie.py文件如下
# -*- coding: utf-8 -*- import scrapy from items import DoubanItem class MovieSpider(scrapy.Spider): # 爬虫名 name = 'movie' # 爬取网站的域名 allowed_domains = ['movie.douban.com'] # 入口url start_urls = ['https://movie.douban.com/top250'] def parse(self, response): # 首先抓取电影列表 movie_list = response.xpath("//ol[@class='grid_view']/li") for selector in movie_list: # 遍历每个电影列表,从其中精准抓取所需要的信息并保存为item对象 item = DoubanItem() item['ranking'] = selector.xpath(".//div[@class='pic']/em/text()").extract_first() item['name'] = selector.xpath(".//span[@class='title']/text()").extract_first() text = selector.xpath(".//div[@class='bd']/p[1]/text()").extract() intro = "" for s in text: # 将简介放到一个字符串 intro += "".join(s.split()) # 去掉空格 item['introduce'] = intro item['star'] = selector.css('.rating_num::text').extract_first() item['comments'] = selector.xpath(".//div[@class='star']/span[4]/text()").extract_first() item['describe'] = selector.xpath(".//span[@class='inq']/text()").extract_first() # print(item) yield item # 将结果item对象返回给Item管道 # 爬取网页中的下一个页面url信息 next_link = response.xpath("//span[@class='next']/a[1]/@href").extract_first() if next_link: next_link = "https://movie.douban.com/top250" + next_link print(next_link) # 将Request请求提交给调度器 yield scrapy.Request(next_link, callback=self.parse)xpath选择器
/表示从当前位置的下一级目录进行寻找,//表示从当前位置的任意一级子目录进行寻找,
默认从根目录开始查找,. 代表从当前目录开始查找,@后跟标签属性,text()函数代表取出文字内容
//div[@id='wrapper']//li 代表先从根目录开始查找id为wrapper的div标签,然后取出其下的所有li标签
.//div[@class='pic']/em[1]/text() 代表从当前选择器目录开始查找所有class为pic的div之下的第一个em标签,取出文字内容
string(//div[@id='endText']/p[position()>1]) 代表选取id为endText的div下第二个p标签之后的所有文字内容
/bookstore/book[last()-2] 选取属于 bookstore 子元素的倒数第3个 book 元素。
CSS选择器
还可以使用css选择器来选择页面内的元素,其通过CSS伪类的方式表达选择的元素,使用如下
# 选择类名为left的div下的p标签中的文字 response.css('div.left p::text').extract_first() # 选取id为tag的元素下类名为star元素中的文字 response.css('#tag .star::text').extract_first()5、数据保存
在运行爬虫文件时通过参数-o指定文件保存的位置即可,可以根据文件后缀名选择保存为json或者csv文件,例如
scrapy crawl movie -o data.csv还可以piplines.py文件中对取得的Item数据作进一步操作从而通过python操作将其保存到数据库中
6、中间件设置
有时为了应对网站的反爬虫机制,需要对下载中间件进行一些伪装设置,包括使用IP代理和代理user-agent方式,在middlewares.py文件中新建一个user_agent类用于为请求头添加用户列表,从网上查一些常用的用户代理放入USER_AGENT_LIST列表,然后通过random函数从中随机抽取一个作为代理,设置为reques请求头的User_Agent字段
class user_agent(object): def process_request(self, request, spider): # user agent 列表 USER_AGENT_LIST = [ 'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23', 'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)', 'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)', 'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)', 'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)', 'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0', 'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)', 'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)' ] agent = random.choice(USER_AGENT_LIST) # 从上面列表中随机抽取一个代理 request.headers['User_Agent'] = agent # 设置请求头的用户代理希望本文所述对大家Python程序设计有所帮助。
- 标签,因此通过xpath://ol[@class='grid_view']/li 就选中了本页面所有的电影条目。可以通过谷歌浏览器的Xpath插件或者火狐浏览器的ChroPath获得xpath值,在浏览器右键查看元素,弹出如下图所示的开发者工具,其中最右边就是ChroPath插件,它直观地显示了元素的Xpath值: //div[@id='wrapper']//li
- << 上一篇 下一篇 >>
Python利用Scrapy框架爬取豆瓣电影示例
看: 2150次 时间:2020-11-05 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!