1. 实例描述
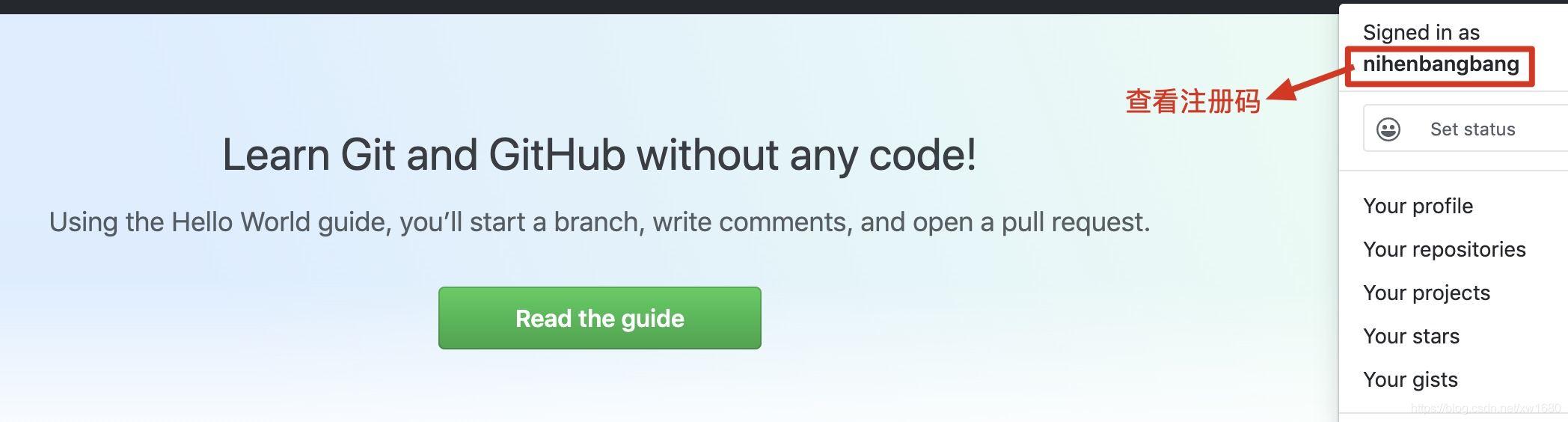
通过爬虫获取网页的信息时,有时需要登录网页后才可以获取网页中的可用数据,例如获取
GitHub网页中的注册号码时,就需要先登录账号才能在登录后的页面中看到该信息,如下图所示。那么该如何实现模拟登录的功能呢?本文实现将通过爬虫实现GitHub网页的模拟登录。
2. 代码实现
在实现
GitHub网页的模拟登录时,首先需要查看提交登录请求时都要哪些请求参数,然后获取登录请求的所有参数,再发送登录请求。如果登录成功的情况下获取页面中的注册号码信息即可。具体步骤如下:(1) 点击 此处 打开
GitHub的登录页面,然后输入账号与密码,如下图所示。

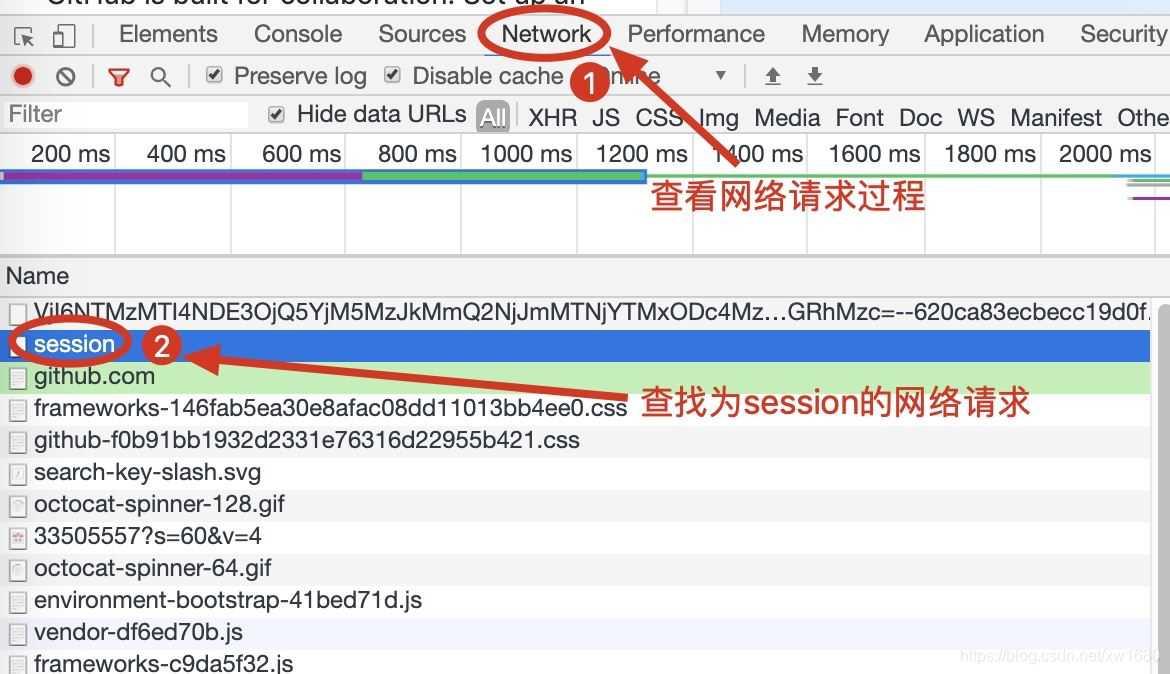
(2) 用
F12或者 鼠标右键单击网页选择检查打开浏览器的开发者工具,选择获取网络请求过程,然后单击登录页面中的Sign in按钮,此时开发者工具中将显示GitHub网页的登录请求过程,重点查找名称为session的网络请求。如下图所示。
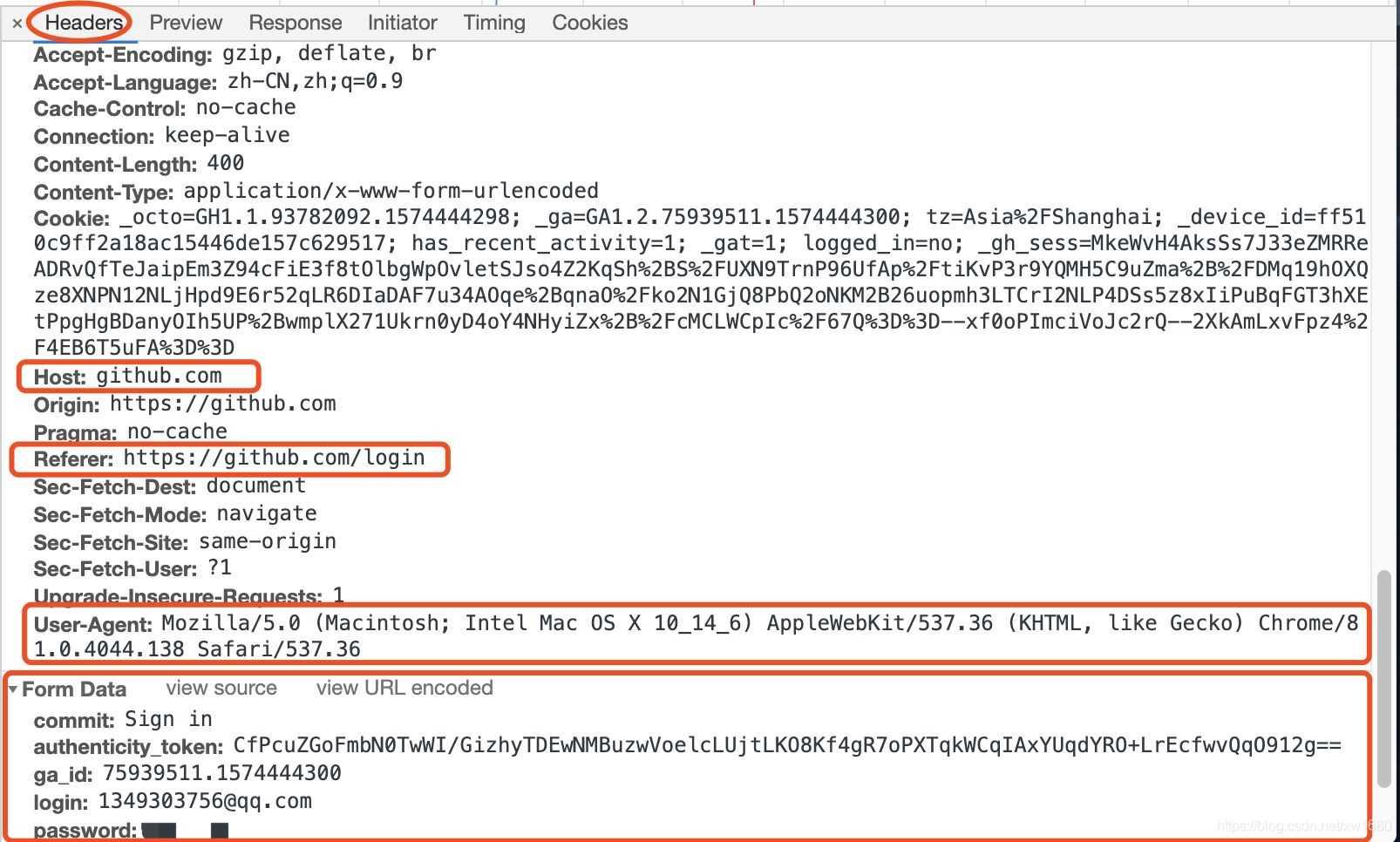
(3) 单击名称为
session的网络请求,然后在Headers请求信息中主要查看Request Headers与Form Data中的各种信息,其中红框内为重要参数与数据。如下图所示。
说明:
Host为主页面地址,Referer为当前请求的来源地址。User-Agent为浏览器的头部信息。Form Data中的所有信息都是登录请求的所用参数,其中动态参数为重要参数,authenticity_token为加密字符串,login为登录的账号,password为密码,其它参数为静态参数。由于动态参数只有authenticity_token、login以及password,而用户名与密码只需要将动态字符串填写对应的位置即可,所以接下来需要获取authenticity_token参数所对应的加密字符串。(4) 在浏览器中退出所登录的
GitHub账号,返回GitHub的登录页面,打开浏览器开发者工具,查看网页的html代码,然后在代码中搜索authenticity_token关键词,标签内value所对应的值为authenticity_token参数的加密字符串。如下图所示。

(5) 实现爬虫代码,首先导入所需模块,然后创建头部信息,再通过
Session会话对象发送网络请求获取authenticity_token信息,最后通过所有的登陆请求参数实现GitHub网页的登陆请求并提取注册号码。具体代码如下:# -*- coding: utf-8 -*- # @Time : 2020/5/10 23:25 # @Author : 我就是任性-Amo # @FileName: 77.通过爬虫实现GitHub网页的模拟登录.py # @Software: PyCharm # @Blog :https://blog.csdn.net/xw1680 import requests # 导入网络请求模块 from lxml import etree # 导入数据解析模块 都是第三方模块需要安装 # pip install requests/lxml如果太慢 可以加上镜像服务器 或者在Pycharm中使用图形化界面进行安装 class GitHubLogin(object): def __init__(self, username, password): # 构造头部信息 self.headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36", "Host": "github.com", "Referer": "https://github.com/login" } self.login_url = "https://github.com/login" # 登录页面地址 self.post_url = "https://github.com/session" # 实现登录的请求地址 self.session = requests.Session() # 创建Session会话对象 self.user_name = username # 用户名 self.password = password # 密码 # 获取authenticity_token信息 def get_token(self): # 发送登录页面的网络请求 response = self.session.get(self.login_url, headers=self.headers) if response.status_code == 200: # 判断请求是否成功 html = etree.HTML(response.text) # 解析html # 提取authenticity_token信息 token = html.xpath("//div[@id='login']/form/input[1]/@value")[0] # print(token) 测试是否能够获取到token return token # 返回信息 # 实现登录 def login(self): # 请求参数 post_data = { "commit": "Sign in", "authenticity_token": self.get_token(), "login": self.user_name, "password": self.password, "webauthn - support": "supported" } # 发送登录请求 response = self.session.post(self.post_url, headers=self.headers, data=post_data) if response.status_code == 200: # 判断请求是否成功 html = etree.HTML(response.text) # 解析html # 获取注册号码 register_number = html.xpath("//div[contains(@class,'Header-item')][last()]//strong")[0] print(f"注册号码为: {register_number.text}") else: print("登录失败") if __name__ == '__main__': user_name = input("请输入您的用户名:") # 获取输入的用户名 password = input("请输入您的密码:") # 获取输入的密码 login = GitHubLogin(user_name, password) # 创建登录类对象并传递输入的用户名与密码 login.login()执行以上代码,输入用户名与密码,即可显示获取的注册号码。如下图所示:

到此这篇关于Python 通过爬虫实现GitHub网页的模拟登录的示例代码的文章就介绍到这了,更多相关Python GitHub模拟登录内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
标签:requests
Python 通过爬虫实现GitHub网页的模拟登录的示例代码
看: 1175次 时间:2020-10-15 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!