requests模块:
python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。
作用:模拟浏览器发请求。
提示:老版使用 urllib模块,但requests比urllib模块要简单好用,现在学习requests模块即可!
requests模块编码流程
指定url
1.1 UA伪装
1.2 请求参数的处理
2.发起请求
3.获取响应数据
4.持久化存储
环境安装:
pip install requests
案例一:破解百度翻译(post请求)
1.代码如下:
#爬取百度翻译 #导入模块 import requests import json #UA伪装:将对应的User-Agent封装到一个字典中 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/57.0.2987.98 Safari/537.36'} #网页访问连接 url='https://fanyi.baidu.com/sug' #处理url携带的参数:封装到字典中 word=input("input a word: ") data={ 'kw': word } #请求发送 res=requests.post(url=url,data=data,headers=headers) #获取响应数据:json()方法返回的是obj(如果确认响应数据是json类型的,才可以使用json()) dic_obj=res.json() #持久化存储 filename=word+'.json' fp=open(filename,'w',encoding='utf-8') json.dump(dic_obj,fp=fp,ensure_ascii=False) #打印完成提示 print('finish')其中:
https://fanyi.baidu.com/sug 这个url的定位如下图:
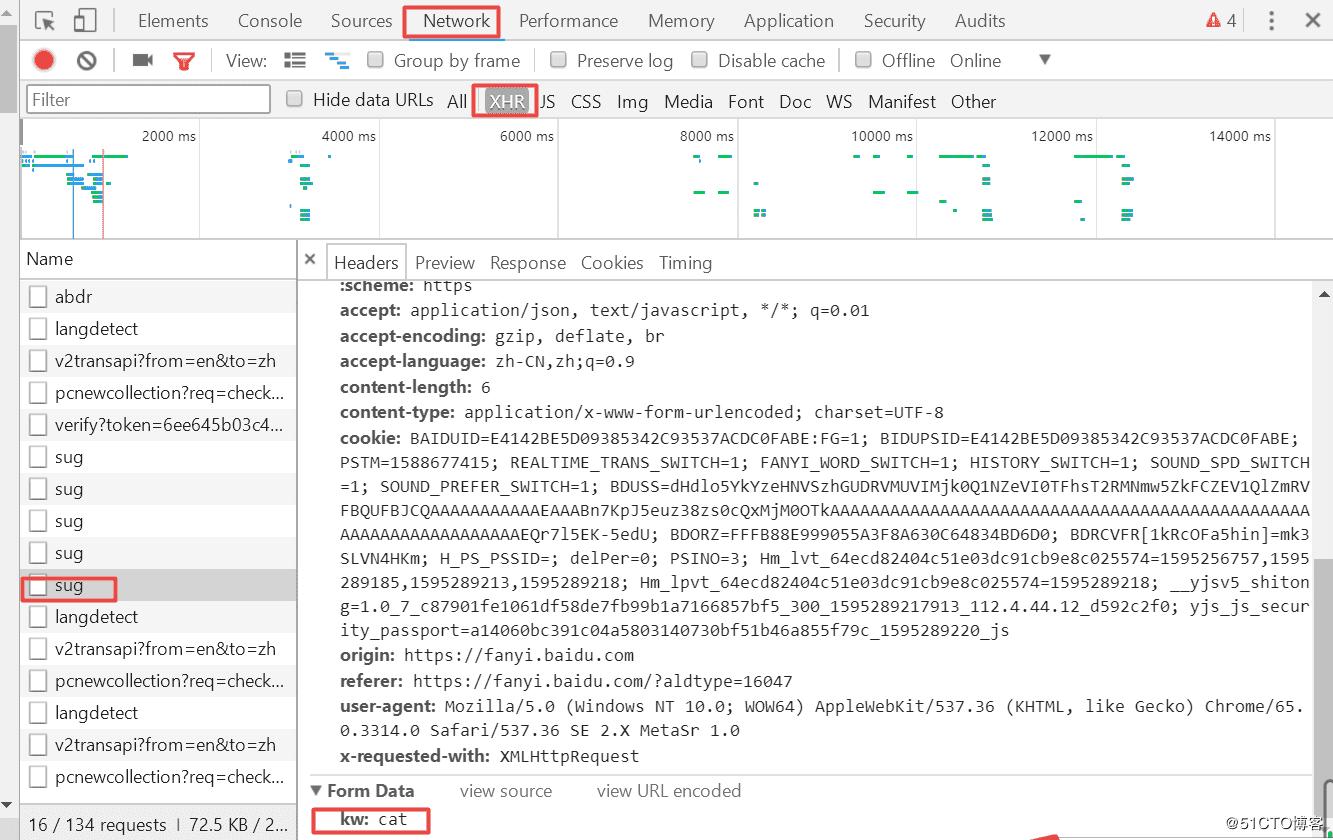
2.运行结果
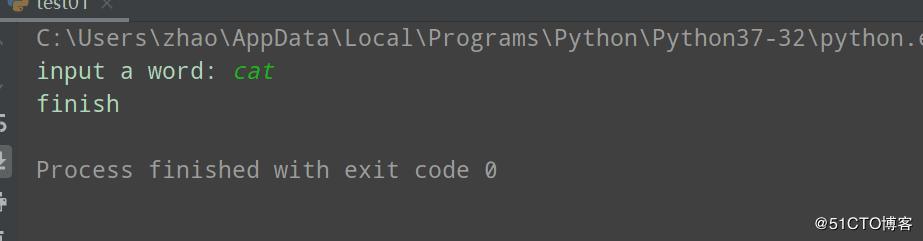

案例二:爬取搜狗页面数据(get请求)
1.代码如下
import requests if __name__ == "__main__": #step_1:指定url url = 'https://www.sogou.com/' #step_2:发起请求 #get方法会返回一个响应对象 response = requests.get(url=url) #step_3:获取响应数据.text返回的是字符串形式的响应数据 page_text = response.text print(page_text) #step_4:持久化存储 with open('./sogou.html','w',encoding='utf-8') as fp: fp.write(page_text) print('爬取数据结束!!!')2.运行结果如下:
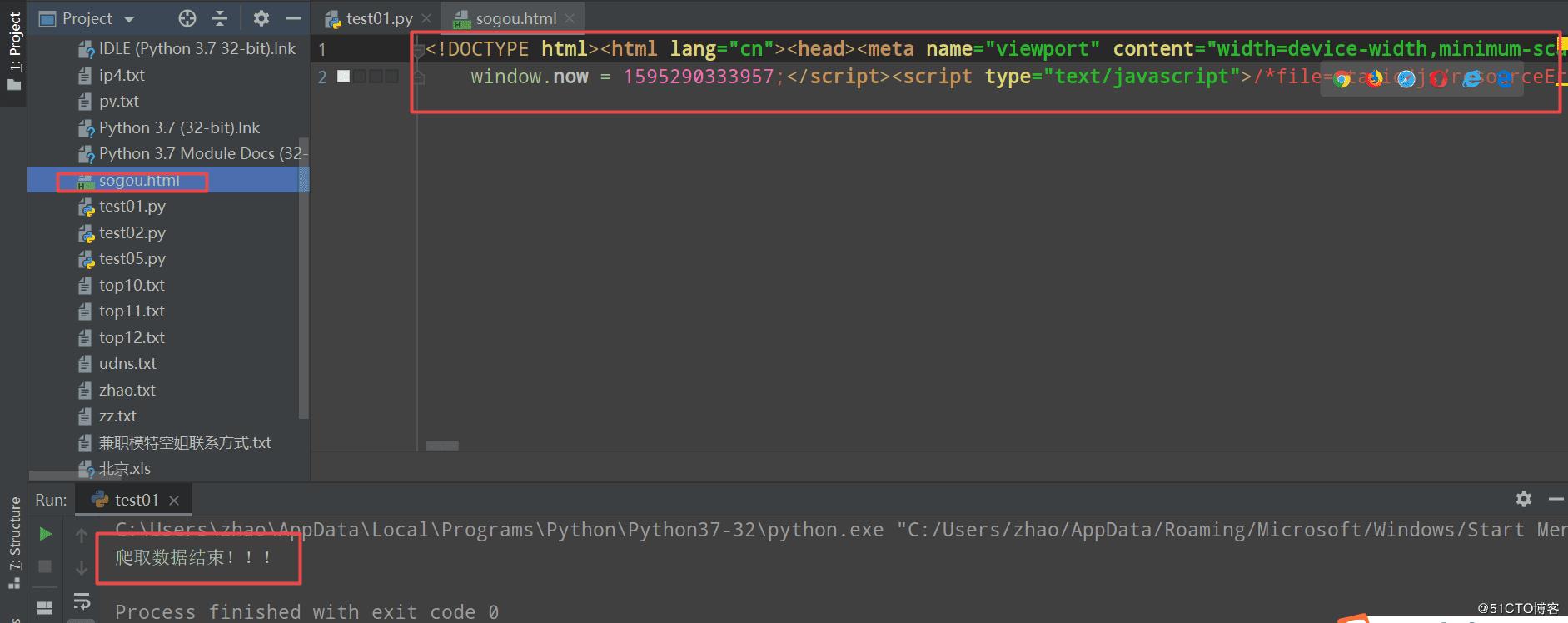
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
- << 上一篇 下一篇 >>
Python使用requests模块爬取百度翻译
看: 1768次 时间:2020-10-11 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!