前言
做数据分析的时候通常我们并不是对真个excel文件进行操作,换言之,每一列都是一个特征,我们需要针对分析。遇到这类问题的时候,我们通常想得到一列中所有符合条件的数据,挑出来,然后组成一个单独的文件进行分析。比如一列中我们希望找到所有大于100的所有行,又比如 我们希望得到一列中包含某个特定字母的所有行,那么我们应该怎么办呢,这里就说一下。
在这之前我们先介绍一个pandas里面一个函数 loc()
英文解释是这样的:Purely label-location based indexer for selection by label.
.loc[] is primarily label based, but may also be used with a boolean array.
最通俗的讲就是标签索引器
了解了这个函数(具体用法下面两个例子就可以懂),我们可两个例子 就可以选择我们想要的行了
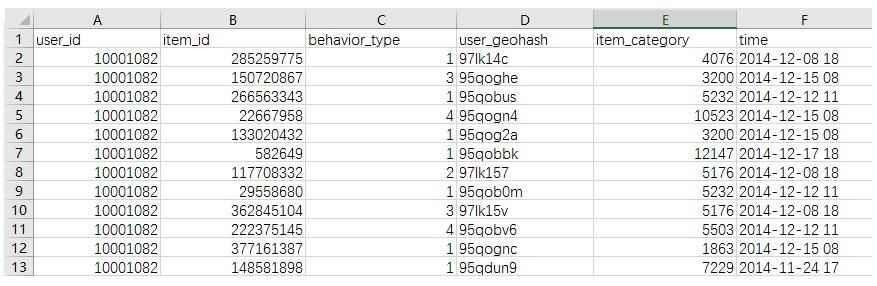
问题一:我们想要“behavior_type”列中所有为3或4的行
import pandas as pd import numpy as np import csv for df in pd.read_csv(open(r'C:\Users\yang\Desktop\useer.csv','r'),chunksize=10000): print(df.loc[df['behavior_type']>1,:])从这个程序我们可以得出 .loc() 前面是我们的整个索引目标,括号中为索引标签(我们回到loc英文解释第二局话,可以索引布尔型) ,那么这么简单一句话就可以把所以为3,4的行输出了.后面的冒号代表从开始到最后索引
print(df.loc[df['behavior_type'].isin([3,4]),:])注意 这里的isin([ ])有小括号 也有中括号集合的形式。
我们也可以利用isin代替大于号性质是一样的,该标签下所有为3,4的集合的布尔型 然后再索引
print(df[df['behavior_type'].isin([3,4])])提到isin 我们想到了一个更为简单的方法,直接索引即可
问题一:我们想要“user_geohash”列中所有含有字母‘qo'的行
print(df.loc[df['user_geohash'].str.contains('qo')])是不是已经想到了 利用loc就可以了,只要后面加上字符串str.contains()函数即可。
那么到这里所有的问题迎刃而解,那么我们想要索取特定行呢 我们想要索取特定列呢
没问题 让我们继续深入了解loc函数
df是一个dataframe,列名为A B C D
具体值如下:
A B C D
0 ss 小红 8
1 aa 小明 d
4 f f
6 ak 小紫 7dataframe里的属性是不定的,空值默认为NA。
一、选取标签为A和C的列,并且选完类型还是dataframe
df = df.loc[:, ['A', 'C']] df = df.iloc[:, [0, 2]]二、选取标签为C并且只取前两行,选完类型还是dataframe
df = df.loc[0:2, ['A', 'C']] df = df.iloc[0:2, [0, 2]]聪明的你发现loc的用法了吗?
总结
到此这篇关于利用python3筛选excel中特定的行(行值满足某个条件/行值属于某个集合)的文章就介绍到这了,更多相关python3筛选excel特定的行内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
- << 上一篇 下一篇 >>
利用python3筛选excel中特定的行(行值满足某个条件/行值属于某个集合)
看: 2386次 时间:2020-09-30 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!