如有错误,欢迎斧正。
我的答案是,在Conv2D输入通道为1的情况下,二者是没有区别或者说是可以相互转化的。首先,二者调用的最后的代码都是后端代码(以TensorFlow为例,在tensorflow_backend.py里面可以找到):
x = tf.nn.convolution( input=x, filter=kernel, dilation_rate=(dilation_rate,), strides=(strides,), padding=padding, data_format=tf_data_format)区别在于input和filter传递的参数不同,input不必说,filter=kernel是什么呢?
我们进入Conv1D和Conv2D的源代码看一下。他们的代码位于layers/convolutional.py里面,二者继承的都是基类_Conv(Layer)。
进入_Conv类查看代码可以发觉以下代码:
self.kernel_size = conv_utils.normalize_tuple(kernel_size, rank, 'kernel_size') ……#中间代码省略 input_dim = input_shape[channel_axis] kernel_shape = self.kernel_size + (input_dim, self.filters)我们假设,Conv1D的input的大小是(600,300),而Conv2D的input大小是(m,n,1),二者kernel_size为3。
进入conv_utils.normalize_tuple函数可以看到:
def normalize_tuple(value, n, name): """Transforms a single int or iterable of ints into an int tuple. # Arguments value: The value to validate and convert. Could an int, or any iterable of ints. n: The size of the tuple to be returned. name: The name of the argument being validated, e.g. "strides" or "kernel_size". This is only used to format error messages. # Returns A tuple of n integers. # Raises ValueError: If something else than an int/long or iterable thereof was passed. """ if isinstance(value, int): return (value,) * n else: try: value_tuple = tuple(value) except TypeError: raise ValueError('The `' + name + '` argument must be a tuple of ' + str(n) + ' integers. Received: ' + str(value)) if len(value_tuple) != n: raise ValueError('The `' + name + '` argument must be a tuple of ' + str(n) + ' integers. Received: ' + str(value)) for single_value in value_tuple: try: int(single_value) except ValueError: raise ValueError('The `' + name + '` argument must be a tuple of ' + str(n) + ' integers. Received: ' + str(value) + ' ' 'including element ' + str(single_value) + ' of type' + ' ' + str(type(single_value))) return value_tuple所以上述代码得到的kernel_size是kernel的实际大小,根据rank进行计算,Conv1D的rank为1,Conv2D的rank为2,如果是Conv1D,那么得到的kernel_size就是(3,)如果是Conv2D,那么得到的是(3,3)
input_dim = input_shape[channel_axis] kernel_shape = self.kernel_size + (input_dim, self.filters)
又因为以上的inputdim是最后一维大小(Conv1D中为300,Conv2D中为1),filter数目我们假设二者都是64个卷积核。
因此,Conv1D的kernel的shape实际为:
(3,300,64)
而Conv2D的kernel的shape实际为:
(3,3,1,64)
刚才我们假设的是传参的时候kernel_size=3,如果,我们将传参Conv2D时使用的的kernel_size设置为自己的元组例如(3,300),那么传根据conv_utils.normalize_tuple函数,最后的kernel_size会返回我们自己设置的元组,也即(3,300)那么Conv2D的实际shape是:
(3,300,1,64),也即这个时候的Conv1D的大小reshape一下得到,二者等价。
换句话说,Conv1D(kernel_size=3)实际就是Conv2D(kernel_size=(3,300)),当然必须把输入也reshape成(600,300,1),即可在多行上进行Conv2D卷积。
这也可以解释,为什么在Keras中使用Conv1D可以进行自然语言处理,因为在自然语言处理中,我们假设一个序列是600个单词,每个单词的词向量是300维,那么一个序列输入到网络中就是(600,300),当我使用Conv1D进行卷积的时候,实际上就完成了直接在序列上的卷积,卷积的时候实际是以(3,300)进行卷积,又因为每一行都是一个词向量,因此使用Conv1D(kernel_size=3)也就相当于使用神经网络进行了n_gram=3的特征提取了。
这也是为什么使用卷积神经网络处理文本会非常快速有效的内涵。
补充知识:Conv1D、Conv2D、Conv3D
由于计算机视觉的大红大紫,二维卷积的用处范围最广。因此本文首先介绍二维卷积,之后再介绍一维卷积与三维卷积的具体流程,并描述其各自的具体应用。
1. 二维卷积
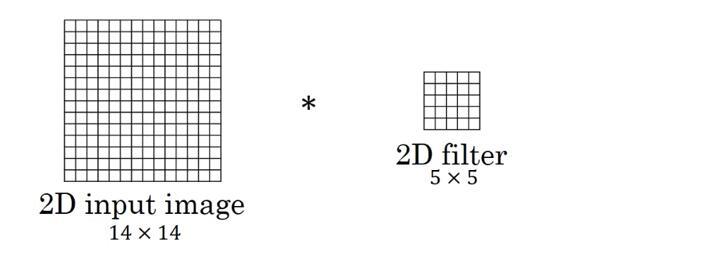
图中的输入的数据维度为
上述内容没有引入channel的概念,也可以说channel的数量为1。如果将二维卷积中输入的channel的数量变为3,即输入的数据维度变为(
以上都是在过滤器数量为1的情况下所进行的讨论。如果将过滤器的数量增加至16,即16个大小为
二维卷积常用于计算机视觉、图像处理领域。
2. 一维卷积

图中的输入的数据维度为8,过滤器的维度为5。与二维卷积类似,卷积后输出的数据维度为
如果过滤器数量仍为1,输入数据的channel数量变为16,即输入数据维度为
如果过滤器数量为
一维卷积常用于序列模型,自然语言处理领域。
3. 三维卷积
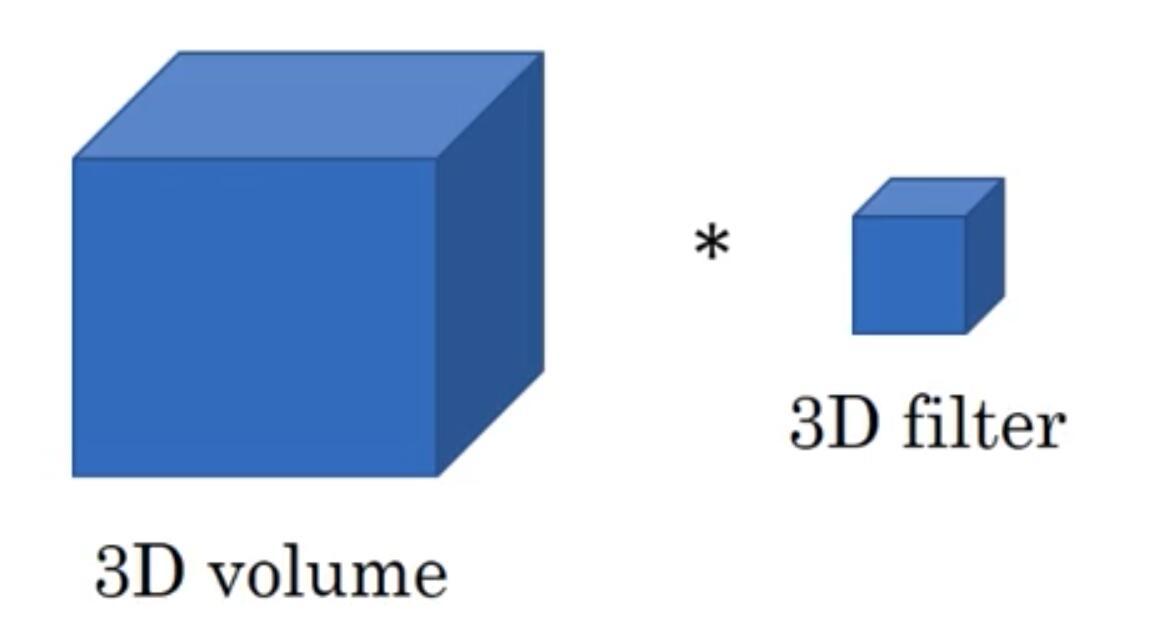
这里采用代数的方式对三维卷积进行介绍,具体思想与一维卷积、二维卷积相同。
假设输入数据的大小为
基于上述情况,三维卷积最终的输出为
三维卷积常用于医学领域(CT影响),视频处理领域(检测动作及人物行为)。
以上这篇基于Keras中Conv1D和Conv2D的区别说明就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
基于Keras中Conv1D和Conv2D的区别说明
看: 1426次 时间:2020-09-11 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!