1、Binary Cross Entropy
常用于二分类问题,当然也可以用于多分类问题,通常需要在网络的最后一层添加sigmoid进行配合使用,其期望输出值(target)需要进行one hot编码,另外BCELoss还可以用于多分类问题Multi-label classification.
定义:
For brevity, let x = output, z = target. The binary cross entropy loss is
loss(x, z) = - sum_i (x[i] * log(z[i]) + (1 - x[i]) * log(1 - z[i]))对应的代码为:
def binary_crossentropy(t,o):
return -(t*tf.log(o+eps) + (1.0-t)*tf.log(1.0-o+eps))2、Categorical cross-entropy
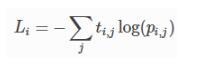
p are the predictions, t are the targets, i denotes the data point and j denotes the class.
适用于多分类问题,并使用softmax作为输出层的激活函数的情况。
补充知识:训练GAN的一些小贴士
下面是我认识到自己犯过的一些错误,以及我从中学到的一些东西。所以,如果你是GANs的新手,并没有看到在训练方面取得很大的成功,也许看看以下几个方面会有所帮助:
1、大卷积核和更多的滤波器
更大的卷积核覆盖了前一层图像中的更多像素,因此可以查看更多信息。5x5的核与CIFAR-10配合良好,在判别器中使用3x3核使判别器损耗迅速趋近于0。对于生成器,你希望在顶层的卷积层有更大的核,以保持某种平滑。在较低的层,我没有看到改变内核大小的任何主要影响。
滤波器的数量可以大量增加参数的数量,但通常需要更多的滤波器。我在几乎所有的卷积层中都使用了128个滤波器。使用较少的滤波器,特别是在生成器中,使得最终生成的图像过于模糊。因此,看起来更多的滤波器可以帮助捕获额外的信息,最终为生成的图像增加清晰度。
2、标签翻转(Generated=True, Real=False)
虽然一开始看起来很傻,但对我有用的一个主要技巧是更改标签分配。
如果你使用的是Real Images = 1,而生成的图像= 0,则使用另一种方法会有所帮助。正如我们将在后面看到的,这有助于在早期迭代中使用梯度流,并帮助使梯度流动。
3、使用有噪声的标签和软标签
这在训练判别器时是非常重要的。硬标签(1或0)几乎扼杀了早期的所有学习,导致识别器非常快地接近0损失。最后,我使用0到0.1之间的随机数表示0标签(真实图像),使用0.9到1.0之间的随机数表示1标签(生成的图像)。在训练生成器时不需要这样做。
此外,增加一些噪音的训练标签也是有帮助的。对于输入识别器的5%的图像,标签被随机翻转。比如真实的被标记为生成的,生成的被标记为真实的。
4、使用批归一化是有用的,但是需要有其他的东西也是合适的
批归一化无疑有助于最终的结果。添加批归一化后,生成的图像明显更清晰。但是,如果你错误地设置了卷积核或滤波器,或者识别器的损失很快达到0,添加批归一化可能并不能真正帮助恢复。
5、每次一个类别
为了更容易地训练GANs,确保输入数据具有相似的特征是很有用的。例如,与其在CIFAR-10的所有10个类中都训练GAN,不如选择一个类(例如,汽车或青蛙)并训练GANs从该类生成图像。DC-GAN的其他变体在学习生成多个类的图像方面做得更好。例如,以类标签为输入,生成基于类标签的图像。但是,如果你从一个普通的DC-GAN开始,最好保持事情简单。
6、查看梯度
如果可能的话,试着监控梯度以及网络中的损失。这些可以帮助你更好地了解训练的进展,甚至可以帮助你在工作不顺利的情况下进行调试。
理想情况下,生成器应该在训练的早期获得较大的梯度,因为它需要学习如何生成真实的数据。另一方面,判别器并不总是在早期获得较大的梯度,因为它可以很容易地区分真假图像。一旦生成器得到足够的训练,判别器就很难分辨真假图像。它会不断出错,并得到大的梯度。
以上这篇解决keras GAN训练是loss不发生变化,accuracy一直为0.5的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
解决keras GAN训练是loss不发生变化,accuracy一直为0.5的问题
看: 1586次 时间:2020-09-03 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!