1. 背景
在软件需求、开发、测试过程中,有时候需要使用一些测试数据,针对这种情况,我们一般要么使用已有的系统数据,要么需要手动制造一些数据。由于现在的业务系统数据多种多样,千变万化。在手动制造数据的过程中,可能需要花费大量精力和工作量,此项工作既繁复又容易出错,比如要构造一批用户三要素(姓名、手机号、身份证)、构造一批银行卡数据、或构造一批地址通讯录等。
这时候,人们常常为了偷懒快捷,测试数据大多数可能是类似这样子的:
测试, 1300000 000123456
张三, 1310000 000123456
李四, 1320000 000234567
王五, 1330000 000345678测试数据中包括了大量的“测试XX”,要么就是随手在键盘上一顿乱敲,都是些无意义的假数据。
你是不是这样做的呢?坦白的说,有过一段时间,笔者偶尔也是这么干的。
但是,细想一下,这样的测试数据,不仅要自己手动敲,还假的不能再假,浪费时间、浪费人力、数据价值低。
而且,部分数据的手工制造还无法保障:比如UUID类数据、MD5、SHA加密类数据等。
为了帮助大家解决这个问题,更多还是提供种一种解决方案或思路,今天给大家分享一款Python造数据利器:Faker库,利用它可以生成一批各种各样的看起来“像真的一样”的假数据。
2. Faker介绍 、安装
2.1 Faker是什么
Faker是一个Python包,主要用来创建伪数据,使用Faker包,无需再手动生成或者手写随机数来生成数据,只需要调用Faker提供的方法,即可完成数据的生成。
项目地址:https://github.com/joke2k/faker
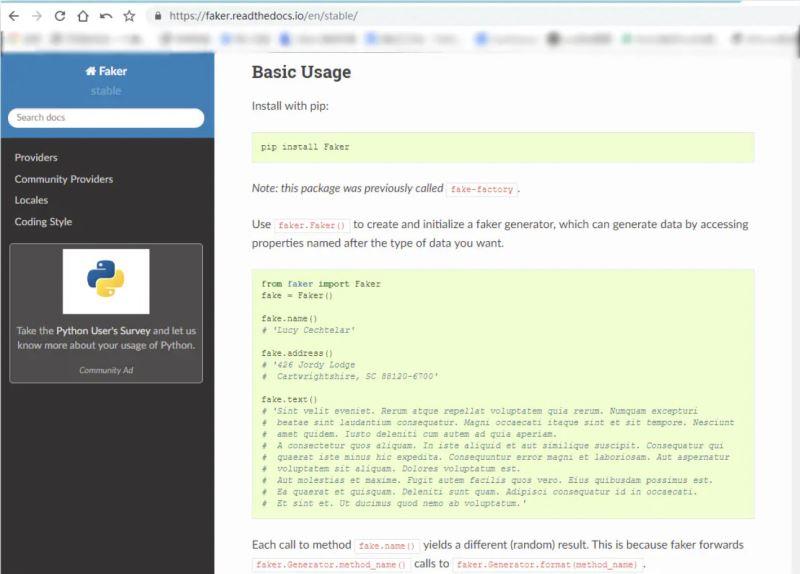
2.2 安装
安装 Faker 很简单,使用 pip 方式安装:
pip install Faker
除了pip 安装,也可以通过上方提供的github地址,来下载编译安装。
(py3_env) ➜ py3_env pip show faker
Name: Faker
Version: 4.1.1
Summary: Faker is a Python package that generates fake data for you.
Home-page: https://github.com/joke2k/faker
Author: joke2k
Author-email: joke2k@gmail.com
License: MIT License
Location: /Users/xxx/work_env/py3_env/lib/python3.7/site-packages
Requires: python-dateutil, text-unidecode
Required-by:3. Faker常用使用
3.1 基本用法
Faker 的使用也是很简单的,从 faker 模块中导入类,然后实例化这个类,就可以调用方法使用了:
from faker import Faker fake = Faker() name = fake.name() address = fake.address() print(name) print(address) # 输出信息 Ashley Love 074 Lee Village Suite 464 Dawnborough, RI 44234这里我们造了一个名字和一个地址,由于 Faker 默认是英文数据,所以如果我们需要造其他语言的数据,可以使用 locale参数,例如:
from faker import Faker fake = Faker(locale='zh_CN') name = fake.name() address = fake.address() print(name) print(address) # 输出信息 张艳 海南省上海市朝阳邱路y座 175208是不是看起来还不错,但是有一点需要注意,这里的地址并不是真实的地址,而是随机组合出来的,也就是将省、市、道路之类的随机组合在一起。
这里介绍几个比较常见的语言代号:
- 简体中文:zh_CN
- 繁体中文:zh_TW
- 美国英文:en_US
- 英国英文:en_GB
- 德文:de_DE
- 日文:ja_JP
- 韩文:ko_KR
- 法文:fr_FR
例如将语言修改为繁体中文
fake = Faker(locale='zh_TW'),输出信息为:楊志宏
100 中壢博愛街10號9樓3.2 常用函数
除了上述介绍的
fake.name和fake.address生成姓名和地址两个函数外,常用的faker函数按类别划分有如下一些常用方法。1、地理信息类
- fake.city_suffix():市,县
- fake.country():国家
- fake.country_code():国家编码
- fake.district():区
- fake.geo_coordinate():地理坐标
- fake.latitude():地理坐标(纬度)
- fake.longitude():地理坐标(经度)
- fake.postcode():邮编
- fake.province():省份
- fake.address():详细地址
- fake.street_address():街道地址
- fake.street_name():街道名
- fake.street_suffix():街、路
2、基础信息类
- ssn():生成身份证号
- bs():随机公司服务名
- company():随机公司名(长)
- company_prefix():随机公司名(短)
- company_suffix():公司性质
- credit_card_expire():随机信用卡到期日
- credit_card_full():生成完整信用卡信息
- credit_card_number():信用卡号
- credit_card_provider():信用卡类型
- credit_card_security_code():信用卡安全码
- job():随机职位
- first_name_female():女性名
- first_name_male():男性名
- last_name_female():女姓
- last_name_male():男姓
- name():随机生成全名
- name_female():男性全名
- name_male():女性全名
- phone_number():随机生成手机号
- phonenumber_prefix():随机生成手机号段
3、计算机基础、Internet信息类
- ascii_company_email():随机ASCII公司邮箱名
- ascii_email():随机ASCII邮箱:
- company_email():
- email():
- safe_email():安全邮箱
4、网络基础信息类
- domain_name():生成域名
- domain_word():域词(即,不包含后缀)
- ipv4():随机IP4地址
- ipv6():随机IP6地址
- mac_address():随机MAC地址
- tld():网址域名后缀(.com,.net.cn,等等,不包括.)
- uri():随机URI地址
- uri_extension():网址文件后缀
- uri_page():网址文件(不包含后缀)
- uri_path():网址文件路径(不包含文件名)
- url():随机URL地址
- user_name():随机用户名
- image_url():随机URL地址
5、浏览器信息类
- chrome():随机生成Chrome的浏览器user_agent信息
- firefox():随机生成FireFox的浏览器user_agent信息
- internet_explorer():随机生成IE的浏览器user_agent信息
- opera():随机生成Opera的浏览器user_agent信息
- safari():随机生成Safari的浏览器user_agent信息
- linux_platform_token():随机Linux信息
- user_agent():随机user_agent信息
6、数字类
- numerify():三位随机数字
- random_digit():0~9随机数
- random_digit_not_null():1~9的随机数
- random_int():随机数字,默认0~9999,可以通过设置min,max来设置
- random_number():随机数字,参数digits设置生成的数字位数
pyfloat():
left_digits=5 #生成的整数位数,
right_digits=2 #生成的小数位数,
positive=True #是否只有正数- pyint():随机Int数字(参考random_int()参数)
- pydecimal():随机Decimal数字(参考pyfloat参数)
7、文本、加密类
- pystr():随机字符串
- random_element():随机字母
- random_letter():随机字母
- paragraph():随机生成一个段落
- paragraphs():随机生成多个段落,通过参数nb来控制段落数,返回数组
- sentence():随机生成一句话
- sentences():随机生成多句话,与段落类似
- text():随机生成一篇文章(不要幻想着人工智能了,至今没完全看懂一句话是什么意思)
- word():随机生成词语
- words():随机生成多个词语,用法与段落,句子,类似
- binary():随机生成二进制编码
- boolean():True/False
- language_code():随机生成两位语言编码
- locale():随机生成语言/国际 信息
- md5():随机生成MD5
- null_boolean():NULL/True/False
- password():随机生成密码,可选参数:length:密码长度;special_chars:是否能使用特殊字符;digits:是否包含数字;upper_case:是否包含大写字母;lower_case:是否包含小写字母
- sha1():随机SHA1
- sha256():随机SHA256
- uuid4():随机UUID
8、时间信息类
- date():随机日期
- date_between():随机生成指定范围内日期,参数:start_date,end_date
- date_between_dates():随机生成指定范围内日期,用法同上
- date_object():随机生产从1970-1-1到指定日期的随机日期。
- date_time():随机生成指定时间(1970年1月1日至今)
- date_time_ad():生成公元1年到现在的随机时间
- date_time_between():用法同dates
- future_date():未来日期
- future_datetime():未来时间
- month():随机月份
- month_name():随机月份(英文)
- past_date():随机生成已经过去的日期
- past_datetime():随机生成已经过去的时间
- time():随机24小时时间
- timedelta():随机获取时间差
- time_object():随机24小时时间,time对象
- time_series():随机TimeSeries对象
- timezone():随机时区
- unix_time():随机Unix时间
- year():随机年份
9、python 相关方法
- profile():随机生成档案信息
- simple_profile():随机生成简单档案信息
- pyiterable()
- pylist()
- pyset()
- pystruct()
- pytuple()
- pydict()
可以用dir(fake),看Faker库都可以fake哪些数据,目前Faker支持近300种数据,此外还支持自己进行扩展。
有了这些生成数据函数之后用fake对象就可以调用不同的方法生成各种数据了。
3.3 常用数据场景
1、构造通讯录记录
from faker import Faker fake = Faker(locale='zh_CN') for _ in range(5): print('姓名:', fake.name(), ' 手机号:', fake.phone_number()) # 输出信息: 姓名: 骆柳 手机号: 18674751460 姓名: 薛利 手机号: 13046558454 姓名: 翟丽丽 手机号: 15254904803 姓名: 宋秀珍 手机号: 13347585045 姓名: 孔桂珍 手机号: 182589115042、构造信用卡数据
from faker import Faker fake = Faker(locale='zh_CN') print('Card Number:', fake.credit_card_number(card_type=None)) print('Card Provider:', fake.credit_card_provider(card_type=None)) print('Card Security Code:', fake.credit_card_security_code(card_type=None)) print('Card Expire:', fake.credit_card_expire()) # 输出信息: Card Number: 676181530350 Card Provider: Diners Club / Carte Blanche Card Security Code: 615 Card Expire: 09/213、生成个人档案信息
from faker import Faker fake = Faker(locale='zh_CN') print(fake.profile()) # 输出信息 {'job': '美术指导', 'company': '易动力传媒有限公司', 'ssn': '370703197807179500', 'residence': '广西壮族自治区旭县蓟州东莞街L座 784064', 'current_location': (Decimal('78.3608745'), Decimal('-95.946407')), 'blood_group': 'B+', 'website': ['https://www.jiewang.org/', 'https://www.longsong.cn/', 'https://jingyong.net/', 'https://58.cn/'], 'username': 'qinqiang', 'name': '唐伟', 'sex': 'F', 'address': '新疆维吾尔自治区建华市东丽拉萨街a座 875743', 'mail': 'shenyang@hotmail.com', 'birthdate': datetime.date(2014, 4, 27)}4、生成Python相关结构信息
from faker import Faker fake = Faker(locale='zh_CN') print('生成Python字典: {}'.format(fake.pydict( nb_elements=10, variable_nb_elements=True))) # Python字典 print('生成Python可迭代对象:{}.'.format(fake.pyiterable( nb_elements=10, variable_nb_elements=True))) # Python可迭代对象 print('生成Python结构:{}'.format(fake.pystruct(count=1))) # Python结构 # 输出信息 成Python字典: {'论坛': 'nVcSbHlrcrhIBtwByVUM', '直接': 'drkyFUNcNxdbwYKhRLEZ', '成功': 'https://fang.cn/main/search/blog/search/', '没有': datetime.datetime(2006, 2, 24, 15, 40, 14), '原因': 404, '作者': 'OTJjsFHQklpUvTPtLCqP'} 生成Python可迭代对象:{1088, 'ignqbohwYRxqolLEzSti', 'http://gang.cn/main/search.php', 'zRnNYdIpPXUxEVISHbvS', 'ToZxuBetghvlPHUumAvi', 9830, 'OYAjoKeVNGhHMLgnYUAw', 970446.888, -17681479853.4069, 872236250787063.0, datetime.datetime(2017, 12, 24, 5, 58, 58), 'aRSfxiUSuMqHXvKCCkMJ'} 生成Python结构:(['cKwOvdCEFOhCERMSMXSf'], {'只有': 'hhwGCmjkHMOUjBTDztXp'}, {'还有': {0: 'vjcNqpnRbNUUxXpgVyvh', 1: [8725, 7125, 'aTSJssAJUKpuRLcbiwyK'], 2: {0: 'RmWlFQQpVZIQkxZPfJnq', 1: 'efsUVLgeStXbCOJDuJCf', 2: ['FgZQLCRjUTmEbBdDMEPZ', 'https://min.cn/search/faq/']}}})4. Faker常用使用
如果这些数据还不够生成数据使用,Faker还支持创建自定义的Provider生成数据。
from faker import Faker from faker.providers import BaseProvider # 创建自定义Provider class CustomProvider(BaseProvider): def customize_type(self): return 'test_Faker_customize_type' # 添加Provider fake = Faker() fake.add_provider(CustomProvider) print(fake.customize_type())是不是十分简单,以后常用的数据就可以自己创建Provider用自动化的方法生成了,不仅节省了时间,复用性也变高了。
5. 总结
这些只是其中的一些常见的数据,Faker 可以造的数据远不止这些类型。相信通过本文的介绍,大家应该对 Faker 不陌生了吧。以后在需要造数据的时候,一定要想起 Faker 这个利器哦!
此外,作为一个开源的库,Faker的源码是非常值得研究的,也是Python新手可以用来练开源项目的利器。
到此这篇关于推荐技术人员一款Python开源库(造数据神器)的文章就介绍到这了,更多相关Python开源库内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
推荐技术人员一款Python开源库(造数据神器)
看: 1300次 时间:2020-08-30 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!