用 '[\u4e00-\u9fa5]‘ 匹配中文
在字符串中匹配中文
示例:
匹配字符串中的第一个中文字符

匹配字符串中的第一个连续的中文片段
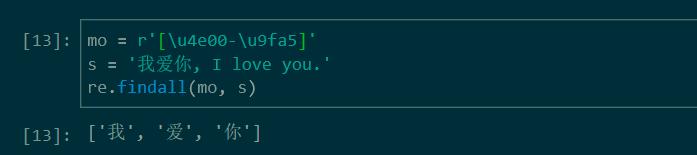
匹配字符串中的所有中文字符
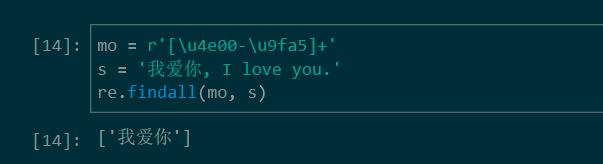

注:要确保正则字符和匹配文本是 unicode 范围内的编码。
其他 扩充 范围
几个主要非英文语系字符范围: 2E80~33FFh:中日韩符号区。收容康熙字典部首、中日韩辅助部首、注音符号、日本假名、韩文音符,中日韩的符号、标点、带圈或带括符文数字、月份,以及日本的假名组合、单位、年号、月份、日期、时间等。 3400~4DFFh:中日韩认同表意文字扩充A区,总计收容6,582个中日韩汉字。 4E00~9FFFh:中日韩认同表意文字区,总计收容20,902个中日韩汉字。 A000~A4FFh:彝族文字区,收容中国南方彝族文字和字根。 AC00~D7FFh:韩文拼音组合字区,收容以韩文音符拼成的文字。 F900~FAFFh:中日韩兼容表意文字区,总计收容302个中日韩汉字。 FB00~FFFDh:文字表现形式区,收容组合拉丁文字、希伯来文、阿拉伯文、中日韩直式标点、小符号、半角符号、全角符号等。以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
Python正则表达式如何匹配中文
看: 1874次 时间:2020-07-03 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!