我就废话不多说了,大家还是直接看代码吧~
import pandas as pd import numpy as np columns = [['A', 'A', 'B', 'B', 'C'], ['a', 'b', 'c', 'd', 'e']] # 创建形状为(10,5) 的DataFrame 并设置二级标题 demo_df = pd.DataFrame(np.arange(50).reshape(10, 5), columns=columns) print(demo_df) def style_color(df, colors): """ :param df: pd.DataFrame :param colors: 字典 内容是 {标题:颜色} :return: """ return df.style.apply(style_apply, colors=colors) def style_apply(series, colors, back_ground=''): """ :param series: 传过来的数据是DataFramt中的一列 类型为pd.Series :param colors: 内容是字典 其中key 为标题名 value 为颜色 :param back_ground: 北京颜色 :return: """ series_name = series.name[0] a = list() # 为了给每一个单元格上色 for col in series: # 其中 col 为pd.DataFrame 中的 一个小单元格 大家可以根据不同需求为单元格设置不同的颜色 # 获取什么一级标题获取什么颜色 if series_name in colors: for title_name in colors: if title_name == series_name: back_ground = 'background-color: ' + colors[title_name] # '; border-left-color: #080808' a.append(back_ground) return a style_df = style_color(demo_df, {"A": '#1C1C1C', "B": '#00EEEE', "C": '#1A1A1A'}) with pd.ExcelWriter('df_style.xlsx', engine='openpyxl') as writer: #注意: 二级标题的to_excel index 不能为False style_df.to_excel(writer, sheet_name='sheet_name')以上就是pandas.DataFrame 二级标题to_excel() 添加颜色的demo 大家可以自行根据不同需求修改
主要注意
style_apply 方法中的内容 里面是真正设置颜色的地方
补充知识:对pandas的dataframe自定义颜色显示
原始表是这样,一堆数字视觉表达能力很差
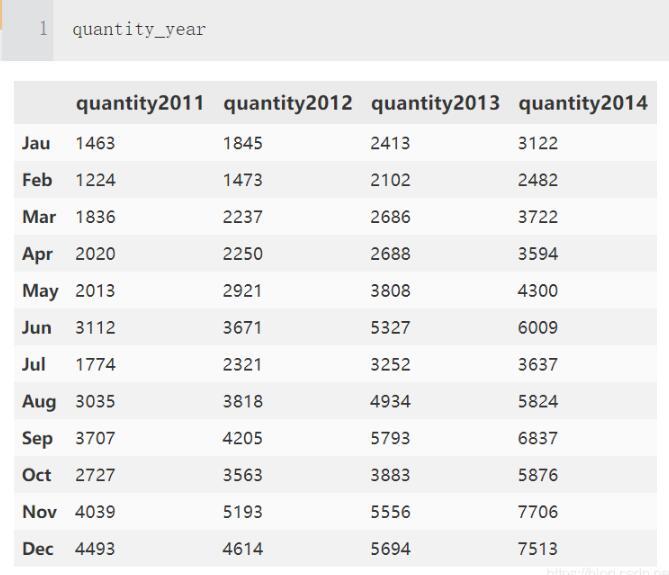
quantity_year.style.background_gradient(cmap='gray_r')

按照大小对其进行不同颜色的填充,视觉表达能力强了很多。 也可以自定义颜色填充,比如我这里对大于平均值的进行颜色填充。
quantity_year.style.applymap(lambda v : 'background-color: %s' %'#FFCCFF' if v>quantity_year.mean().mean() else'background-color: %s'% '')当然也可以自己def 更复杂的功能,都是大同小异。当然还有highlight_max(‘color'),highlight_min(‘color')这种高亮最小最大值,也有hide_index()这种隐藏索引的小操作,在这里记录一下。
以上这篇pandas to_excel 添加颜色操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持python博客。
- << 上一篇 下一篇 >>
pandas to_excel 添加颜色操作
看: 2815次 时间:2020-08-28 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!