在编写爬虫爬取数据的时候,因为很多网站都有反爬虫措施,所以很容易被封IP,就不能继续爬了。在爬取大数据量的数据时更是瑟瑟发抖,时刻担心着下一秒IP可能就被封了。
本文就如何解决这个问题总结出一些应对措施,这些措施可以单独使用,也可以同时使用,效果更好。
伪造User-Agent
在请求头中把User-Agent设置成浏览器中的User-Agent,来伪造浏览器访问。比如:
headers ={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'} resp = requests.get(url,headers = headers)
还可以先收集多种浏览器的User-Agent,每次发起请求时随机从中选一个使用,可以进一步提高安全性:
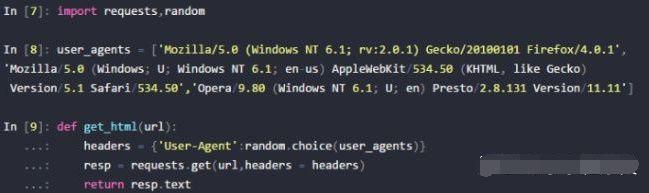
把上面随机选择一个User-Agent的代码封装成一个函数:
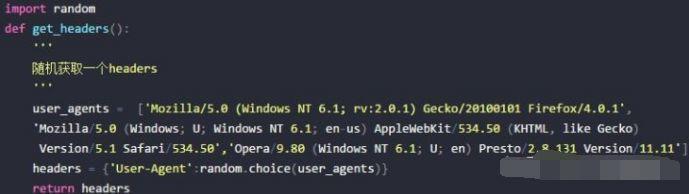
在每次重复爬取之间设置一个随机时间间隔
比如:
time.sleep(random.randint(0,3)) # 暂停0~3秒的整数秒,时间区间:[0,3]或:
time.sleep(random.random()) # 暂停0~1秒,时间区间:[0,1)伪造cookies
若从浏览器中可以正常访问一个页面,则可以将浏览器中的cookies复制过来使用,比如:

注:用浏览器cookies发起请求后,如果请求频率过于频繁仍会被封IP,这时可以在浏览器上进行相应的手工验证(比如点击验证图片等),然后就可以继续正常使用该cookies发起请求。
使用代理
可以换着用多个代理IP来进行访问,防止同一个IP发起过多请求而被封IP,比如:
附:GitHub上的一个"反反爬虫"项目
道高一尺魔高一丈,你有反爬虫措施,那我也有各种"反反爬虫"的措施,GitHub上就有一位大神专门整理了一个这样的项目:Anti-Anti-Spider,链接地址为:github.com/luyishisi/An可以研究一下。
以上就是Python爬虫防封ip的一些技巧的详细内容,更多关于Python爬虫防封ip的资料请关注python博客其它相关文章!
-
<< 上一篇 下一篇 >>
标签:requests
Python爬虫防封ip的一些技巧
看: 1507次 时间:2020-08-20 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!