csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据,比如如下的表格
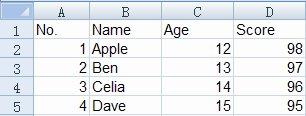
就可以存储为csv文件,文件内容是:
No.,Name,Age,Score
1,Apple,12,98
2,Ben,13,97
3,Celia,14,96
4,Dave,15,95
假设上述csv文件保存为"A.csv",如何用Python像操作Excel一样提取其中的一行,也就是一条记录,利用Python自带的csv模块,有2种方法可以实现:
方法一:reader
第一种方法使用reader函数,接收一个可迭代的对象(比如csv文件),能返回一个生成器,就可以从其中解析出csv的内容:比如下面的代码可以读取csv的全部内容,以行为单位:
import csv with open('A.csv','rb') as csvfile: reader = csv.reader(csvfile) rows = [row for row in reader] print rows得到:
[['No.', 'Name', 'Age', 'Score'],
['1', 'Apple', '12', '98'],
['2', 'Ben', '13', '97'],
['3', 'Celia', '14', '96'],
['4', 'Dave', '15', '95']]
要提取其中第二行,可以用下面的代码:
import csv with open('A.csv','rb') as csvfile: reader = csv.reader(csvfile) for i,rows in enumerate(reader): if i == 2: row = rows print row得到:
['2', 'Ben', '13', '97']
这种方法是通用的方法,要事先知道行号,比如Ben的记录在第2行,而不能根据'Ben'这个名字查询。这时可以采用第二种方法:
方法二:DictReader
第二种方法是使用DictReader,和reader函数类似,接收一个可迭代的对象,能返回一个生成器,但是返回的每一个单元格都放在一个字典的值内,而这个字典的键则是这个单元格的标题(即列头)。用下面的代码可以看到DictReader的结构:
import csv with open('A.csv','rb') as csvfile: reader = csv.DictReader(csvfile) rows = [row for row in reader] print rows得到:
[{'Age': '12', 'No.': '1', 'Score': '98', 'Name': 'Apple'},
{'Age': '13', 'No.': '2', 'Score': '97', 'Name': 'Ben'},
{'Age': '14', 'No.': '3', 'Score': '96', 'Name': 'Celia'},
{'Age': '15', 'No.': '4', 'Score': '95', 'Name': 'Dave'}]
如果我们想用DictReader读取csv的某一列,就可以用列的标题查询:
import csv with open('A.csv','rb') as csvfile: reader = csv.DictReader(csvfile) for row in reader: if row['Name']=='Ben': print row就得到:
{'Age': '13', 'No.': '2', 'Score': '97', 'Name': 'Ben'}
可见,DictReader很适合读取csv的的行(记录)。
-
<< 上一篇 下一篇 >>
python读取csv文件指定行的2种方法详解
看: 1533次 时间:2020-08-14 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!