首先,需要简单的了解一下爬虫,尽可能简单快速的上手,其次,需要了解的是百度的API的接口,搞定这个之后,最后,按照官方给出的demo,然后写自己的一个小程序
打开浏览器 F12 打开百度翻译网页源代码:
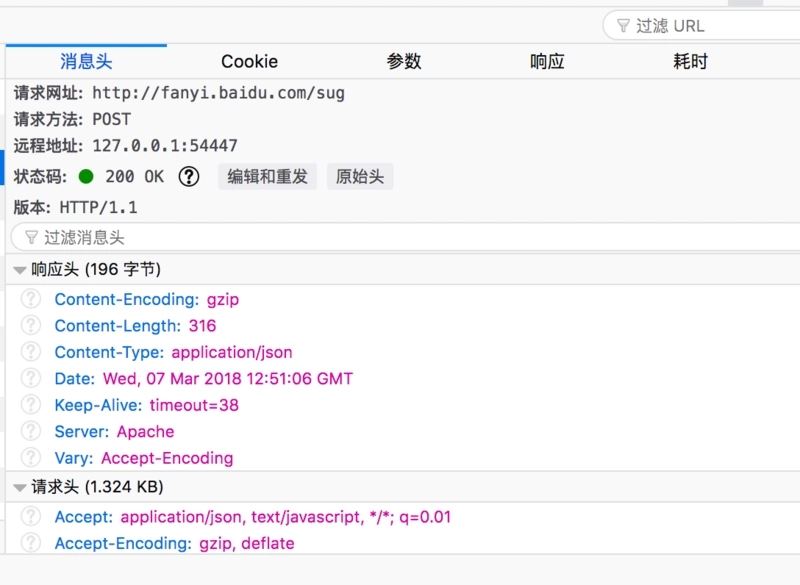
我们可以轻松的找到百度翻译的请求接口为:http://fanyi.baidu.com/sug

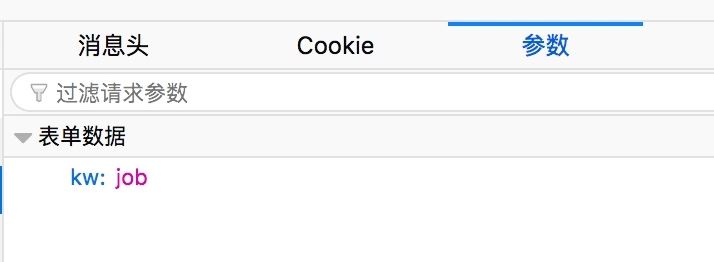
然后我们可以从方法为POST的请求中找到参数为:kw:job(job是输入翻译的内容)
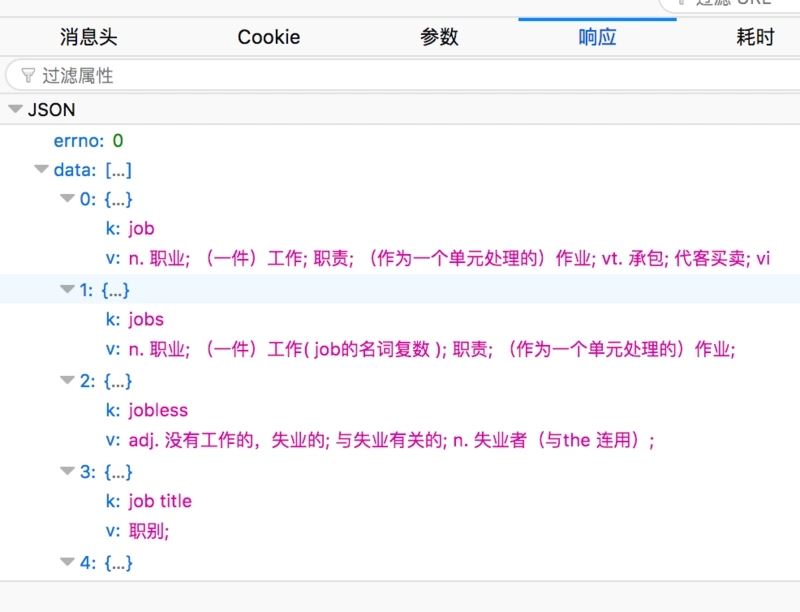
下面是代码部分:
from urllib import request,parse import json def translate(content): url = "http://fanyi.baidu.com/sug" data = parse.urlencode({"kw":content}) # 将参数进行转码 headers = { 'User-Agent': 'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10' } req = request.Request(url,data=bytes(data,encoding="utf-8"),headers=headers) r = request.urlopen(req) # print(r.code) 查看返回的状态码 html = r.read().decode('utf-8') # json格式化 html = json.loads(html) # print(html) for k in html["data"]: print(k["k"],k["v"]) if __name__ == '__main__': content = input("请输入您要翻译的内容:") translate(content)结果如下
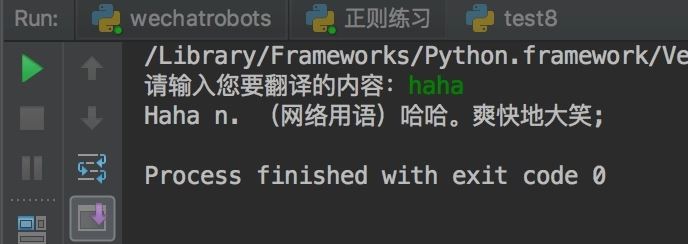
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:urllib
Python爬虫实现百度翻译功能过程详解
看: 1815次 时间:2020-07-02 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!