python 网页解析器
1、常见的python网页解析工具有:re正则匹配、python自带的html.parser模块、第三方库BeautifulSoup(重点学习)以及lxm库。
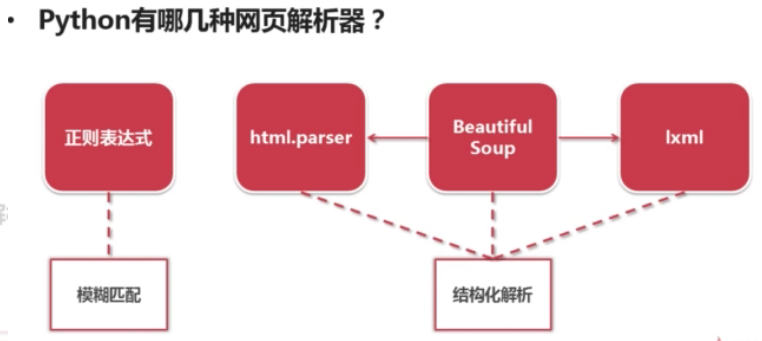
2、常见网页解析器分类
(1)模糊匹配 :re正则表达式即为字符串式的模糊匹配模式;
(2)结构化解析: BeatufiulSoup、html.parser与lxml,他们都以DOM树结构为标准,进行标签结构信息的提取。
3.DOM树解释:即文档对象模型(Document Object Model),其树形标签结构,请见下图。
所谓结构化解析,就是网页解析器它会将下载的整个HTML文档当成一个Doucment对象,然后在利用其上下结构的标签形式,对这个对象进行上下级的标签进行遍历和信息提取操作。
# 引入相关的包,urllib与bs4,是获取和解析网页最常用的库 from urllib.request import urlopen from bs4 import BeautifulSoup # 打开链接 html=urlopen("https://www.datalearner.com/website_navi") # 通过urlopen获得网页对象,将其放入BeautifulSoup中,bsObj存放的目标网页的html文档 bsObj=BeautifulSoup(html.read()) print(bsObj)# soup = BeautifulSoup(open(url,'r',encoding = 'utf-8'))
import requests from bs4 import BeautifulSoup headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36','referer':"www.mmjpg.com" } all_url = 'http://www.mmjpg.com/' #'User-Agent':请求方式 #'referer':从哪个链接跳转进来的 start_html = requests.get(all_url, headers=headers) #all_url:起始的地址,也就是访问的第一个页面 #headers:请求头,告诉服务器是谁来了。 #requests.get:一个方法能获取all_url的页面内容并且返回内容。 Soup = BeautifulSoup(start_html.text, 'lxml') #BeautifulSoup:解析页面 #lxml:解析器 #start_html.text:页面的内容以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
- << 上一篇 下一篇 >>
Python网页解析器使用实例详解
看: 1774次 时间:2020-07-02 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!