正则表达式是处理字符串的强大工具。作为一个概念而言,正则表达式对于Python来说并不是独有的。但是,Python中的正则表达式在实际使用过程中还是有一些细小的差别。
(1)匹配1-100之间的数
import re s = '100' # 1-100内的任意数字 ret = re.match(r'(100|[1-9]\d{0,1})$',s) print(ret.group())(100|[1-9]\d{0,1})$
100可以匹配100 | 或者匹配[1-9]中的一个数,然后后面\d是数字,后面的{0,1}匹配最多一个数字或没有数字
[1-9]\d意思是只能是前面是1-9的任意数字主要是不包括0,否则01是不允许,后面是任意包括0。
(2)匹配座机号码
010-67132692,其构造规则为[3位数字][-][8位数字]
或者
0516-8978981,其构造规则为[4位数字][-][7位数字]
import re s = "010-67132692" ret = re.search(r'^\d{3,4}-\d{7,8}$' , s) print(ret.group())注意:print(ret.group(0)) 一样的效果,python默认可以0,不用()也可以获取,一般php与js中都是\1开始
(3)对输入的qq号进行匹配(qq匹配规则:长度为5-10位,纯数字组成,且不能以0开头。)
import re s = "1101111123" ret = re.match(r'[1-9]\d{4,9}$' , s) if ret != None: print(ret.group()) else : print('匹配失败!')(4)查找字符串中有多少个af
import re s = "asdfjvjadsffvaadfkfasaffdsasdffadsafafsafdadsfaafd" ret = re.findall(r'(af)' , s) print(len(ret))(5)规则是按照空格出现一次或者多次切割
import re s = "zhangsan lisi wangwu" res = re.compile(r'\s+') ret = res.split(s) print(ret)效果图:

(6)用正则\\切割
import re s = "c:\\abc\\a.txt" res = re.compile(r'\\') ret = res.split(s) print(ret)效果图:

(7)将连续5个以上数字替换成#
import re s = "wer8934605juo123wa89320571f" res = re.compile(r'\d{5,}') ret = res.sub('#' , s) print(ret)效果图:

(8)取出字符串中的所有字母
import re s = "abDEe23dJfd343dPOddfe4CdD5ccv!23rr" res = re.compile(r'[a-zA-Z]+') ret = res.findall(s) print(ret)效果图:

(9)找出以字母e结尾的单词,忽略大小写
import re s = 'THREE people at HERE do some THING' res = re.compile(r'\w+e\b' , re.I) #\b为边界 ret = res.findall(s) print(ret)效果图:

(10)将多个重复字母替换成&
import re s = "cudddbhuuujdddcaa" res = re.compile(r'([a-zA-Z])\1+') ret = res.sub('&' , s) print(ret)效果图:
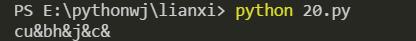
(11)将多个重复字母替换成一个字母(比如ddd替换成d)
import re s = "cudddbhuuujddd" res = re.compile(r'([a-zA-Z])\1+') ret = res.sub(r'\1',s) print(ret)效果图:

(12)获取长度为3个字母的单词
import re s = "min tian jiu yao fang jia le ,da jia" ret = re.findall(r'\b\w{3}\b' , s) print(ret)效果图:

(13)将字符串变成 '我要学编程'
import re s = "我我...我我...我要..要要...要要...学学学...学学...编编编..编程..程.程...程...程" res = re.sub(r'\W+','', s) ret = re.sub(r'(.)\1+',r'\1',res) print(ret)效果图:

(14)去掉div和b标签
结果:正则表达式练习
import re s = "<div class='a'>正则<span>表达式</span><b style='color:red'>练习</b></div>" ret = re.sub(r'(</?div.*?>|</?b.*?>)','',s) print(ret)效果图:

(15)找出每行中只有3个数字的字符串
import re s = '''121fefe 3qsqse2 ded6d32 aaaaa1a 1234adc ''' ret = re.findall(r'^\D*\d\D*\d\D*\d\D*$' , s ,re.M) print(ret)效果图:

以下是补充
收集一些常用的python正则练习
# 匹配出0-99之间的数字 print("---匹配出0-99之间的数字---") ret = re.match(r"^[1-9]?[0-9]$","77") print(ret.group()) # 8到20位的密码,可以是⼤⼩写英⽂字⺟、数字、下划线 print("---,8到20位的密码,可以是⼤⼩写英⽂字⺟、数字、下划线---") ret = re.match("[\w_]{8,20}","1123dasf1") print(ret.group()) # 匹配出163的邮箱地址,且@符号之前有4到 20位,例如hello@163.com print("---匹配出163的邮箱地址,且@符号之前有4到 20位,例如hello@163.com---") ret = re.match("[\w_]{4,20}@163\.com","evan_qb@163.com") print(ret.group()) print("---b---") ret = re.match(r".*\b163\b","evan_qb@163.com") print(ret.group()) # 匹配1-100之间的数 print("---匹配1-100之间的数---") ret = re.match("[1-9]?\d$|100","100") print(ret.group()) # 匹配163、126、qq邮箱 print("---匹配163、126、qq邮箱---") ret = re.match("[\w_]{4,20}@(163|126|qq)\.com","123342@126.com") print(ret.group()) # 匹配<html>hello world</html> print("---匹配<html>hello world</html>---") ret = re.match(r"<([a-zA-Z]*)>.*</\1>","<html>hello world</html>") print(ret.group()) # 第一种:匹配出<html><h1>www.itcast.cn</h1></html> print("---第一种:匹配出<html><h1>www.qblank.cn</h1></html>---") ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>","<html><h1>www.itcast.cn</h1></html>") print(ret.group()) # 第二种: 匹配出<html><h1>www.qblank.cn</h1></html> print("---第二种: 匹配出<html><h1>www.qblank.cn</h1></html>") ret = re.match("<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>","<html><h1>www.qblank.cn</h1></html>") print(ret.group()) # ******re模块的高级用法***** # 使用search匹配文章的阅读的次数 print("---匹配文章的阅读的次数---") ret = re.search(r"\d+","阅读次数为 9999") print(ret.group()) # 统计出python、c、c++相应⽂章阅读的次数 print("---统计出python、c、c++相应⽂章阅读的次数---") ret = re.findall(r"\d+","python = 2342,c = 7980,java = 9999") print(ret) # 将匹配到的阅读次数加1 print("---将匹配到的阅读次数加1---") ret = re.sub(r"\d+","999","python = 997") print(ret) # <div> # <p>岗位职责:</p> # <p>完成推荐算法、数据统计、接⼝、后台等服务器端相关⼯作</p> # <p><br></p> <p>必备要求:</p> <p>良好的⾃我驱动⼒和职业素养,⼯作积极主动、结果导向</p> # <p> <br></p> <p>技术要求:</p> # <p>1、⼀年以上Python开发经验,掌握⾯向对象分析和设计,了解设计模式</p > # <p>2、掌握HTTP协议,熟悉MVC、MVVM等概念以及相关WEB开发框架</p> # <p>3、掌握关系数据库开发设计,掌握SQL,熟练使⽤MySQL/PostgreSQL中 的⼀种<br></p> # <p>4、掌握NoSQL、MQ,熟练使⽤对应技术解决⽅案</p> # <p>5、熟悉Javascript/CSS/HTML5,JQuery、React、Vue.js</p> # <p> <br></p> <p>加分项:</p> # <p>⼤数据,数理统计,机器学习,sklearn,⾼性能,⼤并发。</p> # </div> data = """ <div> <p>岗位职责:</p> <p>完成推荐算法、数据统计、接⼝、后台等服务器端相关⼯作</p> <p><br></p> <p>必备要求:</p> <p>良好的⾃我驱动⼒和职业素养,⼯作积极主动、结果导向</p> <p> <br></p> <p>技术要求:</p> <p>1、⼀年以上Python开发经验,掌握⾯向对象分析和设计,了解设计模式</p > <p>2、掌握HTTP协议,熟悉MVC、MVVM等概念以及相关WEB开发框架</p> <p>3、掌握关系数据库开发设计,掌握SQL,熟练使⽤MySQL/PostgreSQL中 的⼀种<br></p> <p>4、掌握NoSQL、MQ,熟练使⽤对应技术解决⽅案</p> <p>5、熟悉Javascript/CSS/HTML5,JQuery、React、Vue.js</p> <p> <br></p> <p>加分项:</p> <p>⼤数据,数理统计,机器学习,sklearn,⾼性能,⼤并发。</p> </div> """ print("---爬取就业信息网址---") # 方法一:关闭贪婪模式 print("---方法一---") ret = re.sub(r"<.+?>","",data) print(ret) # 方法二: print("---方法二---") ret = re.sub(r"</?\w+>","",data) print(ret) # 切割字符串“info:xiaoZhang33shandong” print("---切割字符串“info:xiaoZhang33shandong”---") ret = re.split(r":|","切割字符串info:xiaoZhang33shandong") print(ret) # Thisisanumber234-235-22-423 data = "Thisisanumber234-235-22-423" print("---贪婪和非贪婪---") # 贪婪 ret = re.match(".+(\d+-\d+-\d+-\d+)",data) print(ret.group(1)) # 非贪婪 ret = re.match(".+?(\d+-\d+-\d+-\d+)",data) print(ret.group(1)) # 提取图片的url data = """ <img data-original="https://rpic.douyucdn.cn/appCovers/2016/1 1/13/1213973_201611131917_small.jpg" src="https://rpic.douyuc dn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg" style="display:inline;"> """ print("---提取图片的url") ret = re.search(r"https.+?\.jpg",data) print(ret.group()) data = """ http://www.interoem.com/messageinfo.asp?id=35 http://3995503.com/class/class09/news_show.asp?id=14 http://lib.wzmc.edu.cn/news/onews.asp?id=769 http://www.zy-ls.com/alfx.asp?newsid=377&id=6 http://www.fincm.com/newslist.asp?id=415 """ # 去掉后缀 print("---去掉后缀---") ret = re.sub(r"(http://.+?/).*", lambda x: x.group(1),data) print(ret) # 找出所有单词 data = "helloworldhaha" print("---找出所有单词---") print("--方法一--") ret = re.split(r" +",data) print(ret) print("--方法二--") ret = re.findall(r"\b[a-zA-Z]+\b",data) print(ret)到此这篇关于Python正则表达式学习小例子的文章就介绍到这了,更多相关Python正则学习例子内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
-
<< 上一篇 下一篇 >>
Python正则表达式学习小例子
看: 1463次 时间:2020-08-08 分类 : python教程
- 相关文章
- 2021-12-20Python 实现图片色彩转换案例
- 2021-12-20python初学定义函数
- 2021-12-20图文详解Python如何导入自己编写的py文件
- 2021-12-20python二分法查找实例代码
- 2021-12-20Pyinstaller打包工具的使用以及避坑
- 2021-12-20Facebook开源一站式服务python时序利器Kats详解
- 2021-12-20pyCaret效率倍增开源低代码的python机器学习工具
- 2021-12-20python机器学习使数据更鲜活的可视化工具Pandas_Alive
- 2021-12-20python读写文件with open的介绍
- 2021-12-20Python生成任意波形并存为txt的实现
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!