使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象
我们在淘宝里搜索“python”,出来的结果
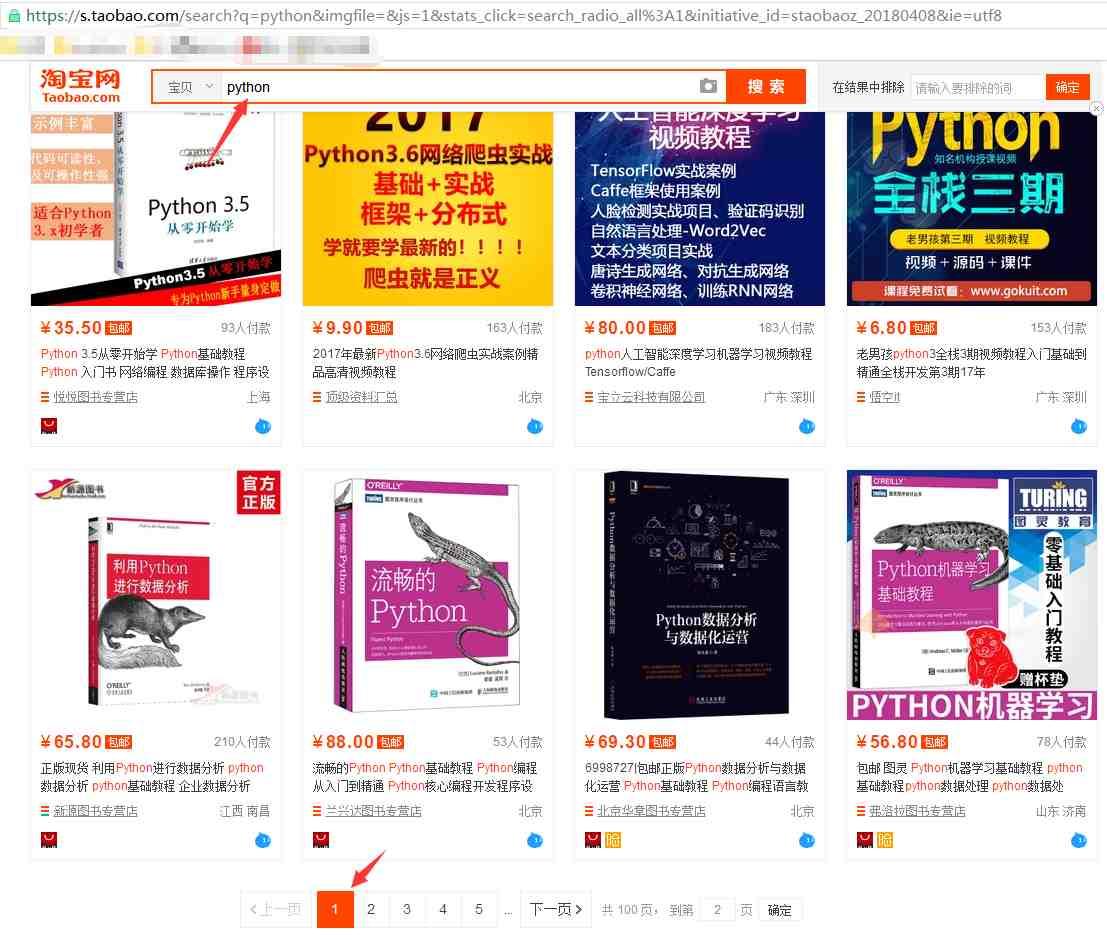
从url连接中可以得到搜索商品的关键字是“q=”,所以我们要用的起始url为:https://s.taobao.com/search?q=python
然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44)
所以可以根据关键字“s=”,来设置爬取的深度(爬取多少页)右键查看源码,商品名称可能的关键字是“title”和“raw_title”,进一步多看几个商品的名称,发现选取“raw_title”比较合适;商品价格自然就是“view_price”(通过比对淘宝商品展示页面);所以商品名称和商品价格分别是以"raw_title":"名称"和"view_price":"价格",这样的键/值对的形式展示的。
# coding:utf-8 import requests import re goods = '水杯' url = 'https://s.taobao.com/search?q=' + goods r = requests.get(url=url, timeout=10) html = r.text tlist = re.findall(r'\"raw_title\"\:\".*?\"', html) # 正则提取商品名称 plist = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) # 正则提示商品价格 print(tlist) print(plist) print(type(plist)) # 正则表达式提取出的商品名称和商品价格都是以列表形式存储数据的利用for循环,把每个商品的名称和价格组成一个列表,然后把这写列表再追加到一个大列表中:
goodlist = [] for i in range(len(tlist)): title = eval(tlist[i].split(':')[1]) # eval()函数简单说就是用于去掉字符串的引号 price = eval(plist[i].split(':')[1]) goodlist.append([title, price]) # 把每个商品的名称和价格组成一个小列表,然后把所有商品组成的列表追加到一个大列表中 print(goodlist)大概的思路就是这样的。
def get_html(url): """获取源码html""" try: r = requests.get(url=url, timeout=10) r.encoding = r.apparent_encoding return r.text except: print("获取失败") def get_data(html, goodlist): """使用re库解析商品名称和价格 tlist:商品名称列表 plist:商品价格列表""" tlist = re.findall(r'\"raw_title\"\:\".*?\"', html) plist = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) for i in range(len(tlist)): title = eval(tlist[i].split(':')[1]) # eval()函数简单说就是用于去掉字符串的引号 price = eval(plist[i].split(':')[1]) goodlist.append([title, price]) def write_data(list, num): # with open('E:/Crawler/case/taob2.txt', 'a') as data: # print(list, file=data) for i in range(num): # num控制把爬取到的商品写进多少到文本中 u = list[i] with open('E:/Crawler/case/taob.txt', 'a') as data: print(u, file=data) def main(): goods = '水杯' depth = 3 # 定义爬取深度,即翻页处理 start_url = 'https://s.taobao.com/search?q=' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44 * i) # 因为淘宝显示每页44个商品,第一页i=0,一次递增 html = get_html(url) get_data(html, infoList) except: continue write_data(infoList, len(infoList)) if __name__ == '__main__': main()以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持python博客。
-
<< 上一篇 下一篇 >>
标签:requests
Python通过正则库爬取淘宝商品信息代码实例
看: 1615次 时间:2020-08-08 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!