使用python爬虫库requests,urllib爬取今日头条街拍美图
代码均有注释
import re,json,requests,os from hashlib import md5 from urllib.parse import urlencode from requests.exceptions import RequestException from bs4 import BeautifulSoup from multiprocessing import Pool #请求索引页 def get_page_index(offset,keyword): #传送的数据 data={ 'offset': offset, 'format': 'json', 'keyword': keyword, 'autoload': 'true', 'count': '20', 'cur_tab': 1 } #自动编码为服务器可识别的url url="https://www.toutiao.com/search_content/?"+urlencode(data) #异常处理 try: #获取返回的网页 response=requests.get(url) #判断网页的状态码是否正常获取 if response.status_code==200: #返回解码后的网页 return response.text #不正常获取,返回None return None except RequestException: #提示信息 print("请求索引页出错") return None #解析请求的索引网页数据 def parse_page_index(html): #json加载转换 data=json.loads(html) #数据为真,并且data键值存在与数据中 if data and 'data' in data.keys(): #遍历返回图集所在的url for item in data.get('data'): yield item.get('article_url') #图集详情页请求 def get_page_detail(url): #设置UA,模拟浏览器正常访问 head = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} #异常处理 try: response=requests.get(url,headers=head) if response.status_code==200: return response.text return None except RequestException: print("请求详情页出错") return None #解析图集详情页的数据 def parse_page_detail(html,url): #异常处理 try: #格式转换与图集标题提取 soup=BeautifulSoup(html,'lxml') title=soup.select('title')[0].get_text() print(title) #正则查找图集链接 image_pattern = re.compile('gallery: (.*?),\n', re.S) result = re.search(image_pattern, html) if result: #数据的优化 result=result.group(1) result = result[12:] result = result[:-2] #替换 result = re.sub(r'\\', '', result) #json加载 data = json.loads(result) #判断数据不为空,并确保sub——images在其中 if data and 'sub_images' in data.keys(): #sub_images数据提取 sub_images=data.get('sub_images') #列表数据提取 images=[item.get('url') for item in sub_images] #图片下载 for image in images:download_images(image) #返回字典 return { 'title':title, 'url':url, 'images':images } except Exception: pass #图片url请求 def download_images(url): #提示信息 print('正在下载',url) #浏览器模拟 head = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} #异常处理 try: response = requests.get(url, headers=head) if response.status_code == 200: #图片保存 save_image(response.content) return None except RequestException: print("请求图片出错") return None #图片保存 def save_image(content): #判断文件夹是否存在,不存在则创建 if '街拍' not in os.listdir(): os.makedirs('街拍') #设置写入文件所在文件夹位置 os.chdir('E:\python写网路爬虫\CSDN爬虫学习\街拍') #路径,名称,后缀 file_path='{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg') #图片保存 with open(file_path,'wb') as f: f.write(content) f.close() #主函数 def mian(offset): #网页获取 html=get_page_index(offset,'街拍') #图集url for url in parse_page_index(html): if url!=None: #图集网页详情 html=get_page_detail(url) #图集内容 result=parse_page_detail(html,url) if __name__ == '__main__': #创建访问的列表(0-9)页 group=[i*10 for i in range(10)] #创建多线程进程池 pool=Pool() #进程池启动,传入的数据 pool.map(mian,group)爬取图片如下
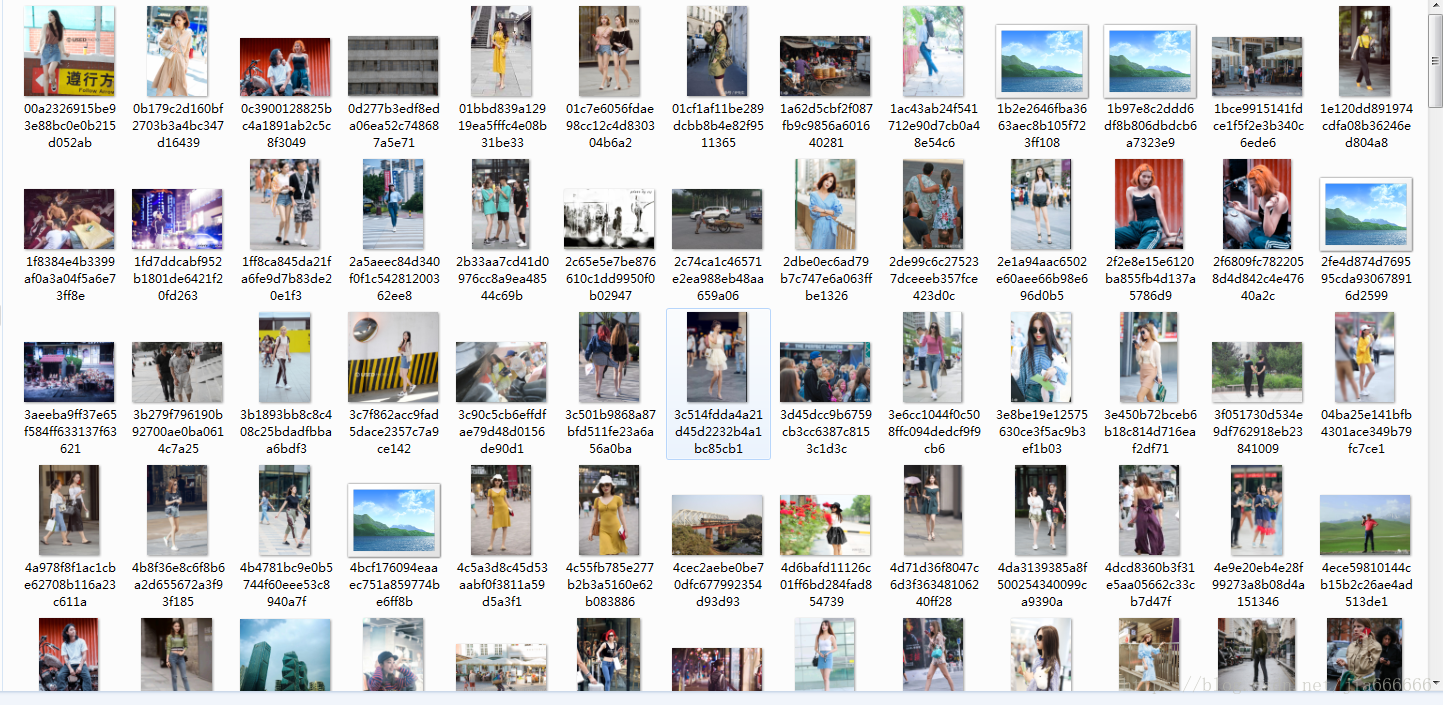
本文主要讲解了python爬虫库requests、urllib与OS模块结合使用爬取今日头条搜索内容的实例,更多关于python爬虫相关知识请查看下面的相关链接
- << 上一篇 下一篇 >>
python爬虫开发之使用python爬虫库requests,urllib与今日头条搜索功能爬取搜索内容实例
看: 1638次 时间:2020-08-05 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!