首先介紹一下我們用360搜索派取城市排名前20。
我们爬取的网址:https://baike.so.com/doc/24368318-25185095.html我们要爬取的内容:
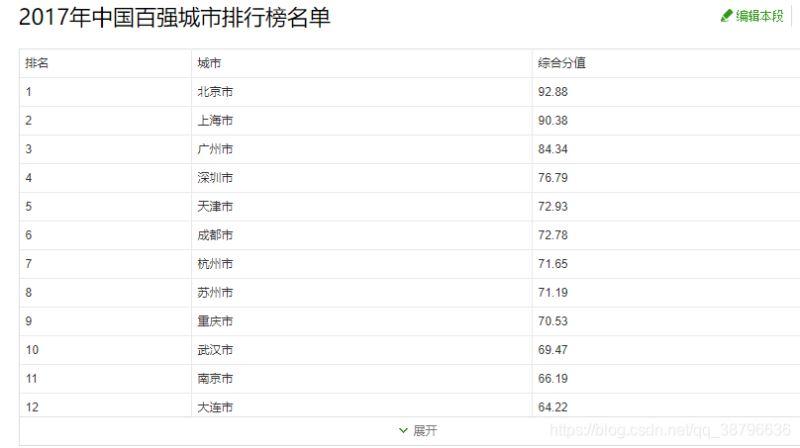
html字段:

robots协议:
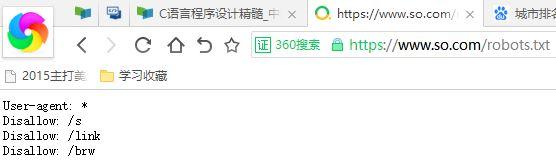
现在我们开始用python IDLE 爬取

import requests r = requests.get("https://baike.so.com/doc/24368318-25185095.html") r.status_code r.text结果分析,我们可以成功访问到该网页,但是得不到网页的结果。被360搜索识别,我们将headers修改。
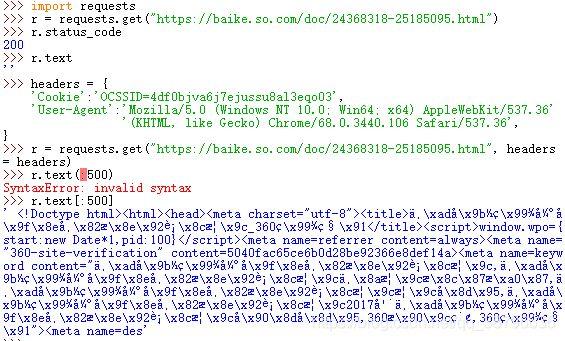
输出有个小插曲,网页内容很多,我是想将前500个字符输出,第一次格式错了
import requests headers = { 'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36' '(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', } r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers) r.status_code r.text接着我们对需要的内容进行爬取,用(.find)方法找到我们内容位置,用(.children)下行遍历的方法对内容进行爬取,用(isinstance)方法对内容进行筛选:
import requests from bs4 import BeautifulSoup import bs4 headers = { 'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36' '(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', } r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers) r.status_code r.encoding = r.apparent_encoding soup = BeautifulSoup(r.text, "html.parser") for tr in soup.find('tbody').children: if isinstance(tr, bs4.element.Tag): tds = tr('td') print([tds[0].string, tds[1].string, tds[2].string])得到结果如下:
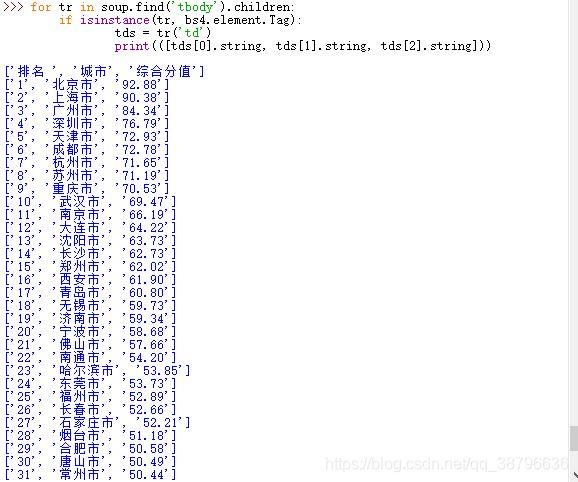
修改输出的数目,我们用Clist列表来存取所有城市的排名,将前20个输出代码如下:
import requests from bs4 import BeautifulSoup import bs4 Clist = list() #存所有城市的列表 headers = { 'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36' '(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', } r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers) r.encoding = r.apparent_encoding #将html的编码解码为utf-8格式 soup = BeautifulSoup(r.text, "html.parser") #重新排版 for tr in soup.find('tbody').children: #将tbody标签的子列全部读取 if isinstance(tr, bs4.element.Tag): #筛选tb列表,将有内容的筛选出啦 tds = tr('td') Clist.append([tds[0].string, tds[1].string, tds[2].string]) for i in range(21): print(Clist[i])最终结果:
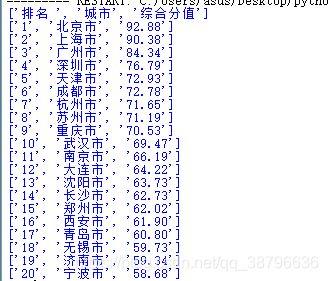
到此这篇关于Python用requests库爬取返回为空的解决办法的文章就介绍到这了,更多相关Python requests返回为空内容请搜索python博客以前的文章或继续浏览下面的相关文章希望大家以后多多支持python博客!
- << 上一篇 下一篇 >>
Python用requests库爬取返回为空的解决办法
看: 1971次 时间:2021-03-29 分类 : python爬虫
- 相关文章
- 2021-07-20Python爬虫基础之爬虫的分类知识总结
- 2021-07-20Python爬虫基础讲解之请求
- 2021-07-20PyQt5爬取12306车票信息程序的实现
- 2021-07-20Python爬虫之m3u8文件里提取小视频的正确姿势
- 2021-07-20如何用python抓取B站数据
- 2021-07-20快速搭建python爬虫管理平台
- 2021-07-20Python爬虫之获取心知天气API实时天气数据并弹窗提醒
- 2021-07-20Python爬虫之批量下载喜马拉雅音频
- 2021-07-20python使用pywinauto驱动微信客户端实现公众号爬虫
- 2021-07-20Requests什么的通通爬不了的Python超强反爬虫方案!
-
搜索
-
-
推荐资源
-
Powered By python教程网 鲁ICP备18013710号
python博客 - 小白学python最友好的网站!